













交叉驗證太重要了!
首先需要搞明白,為什么需要交叉驗證?
交叉驗證是機器學習和統計學中常用的一種技術,用于評估預測模型的性能和泛化能力,特別是在數據有限或評估模型對新的未見數據的泛化能力時,交叉驗證非常有價值。

那么具體在什么情況下會使用交叉驗證呢?
- 模型性能評估:交叉驗證有助于估計模型在未見數據上的表現。通過在多個數據子集上訓練和評估模型,交叉驗證提供了比單一訓練-測試分割更穩健的模型性能估計。
- 數據效率:在數據有限的情況下,交叉驗證充分利用了所有可用樣本,通過同時使用所有數據進行訓練和評估,提供了對模型性能更可靠的評估。
- 超參數調優:交叉驗證通常用于選擇模型的最佳超參數。通過在不同數據子集上使用不同的超參數設置來評估模型的性能,可以確定在整體性能上表現最好的超參數值。
- 檢測過擬合:交叉驗證有助于檢測模型是否對訓練數據過擬合。如果模型在訓練集上的表現明顯優于驗證集,可能表明存在過擬合的情況,需要進行調整,如正則化或選擇更簡單的模型。
- 泛化能力評估:交叉驗證提供了對模型對未見數據的泛化能力的評估。通過在多個數據分割上評估模型,它有助于評估模型捕捉數據中的潛在模式的能力,而不依賴于隨機性或特定的訓練-測試分割。
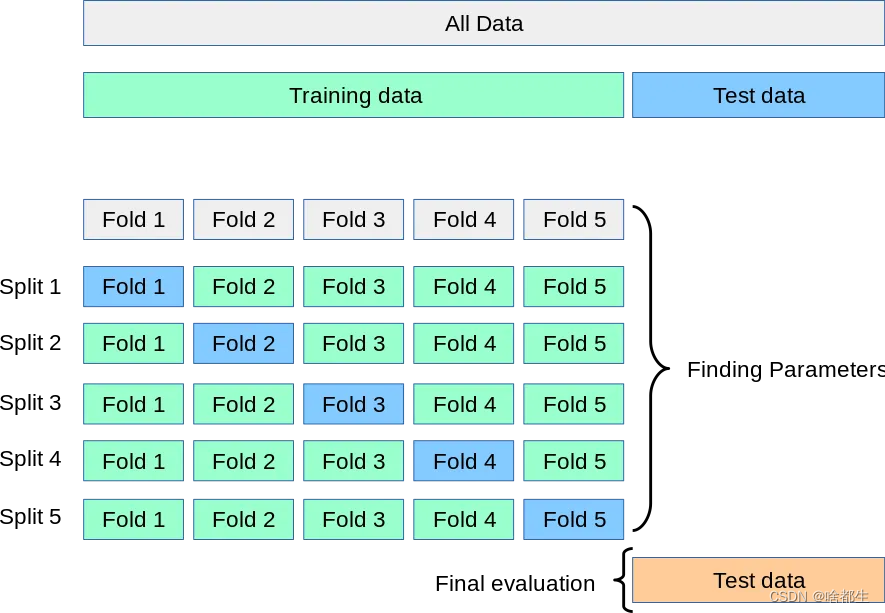
交叉驗證的大致思想可如圖5折交叉所示,在每次迭代中,新模型在四個子數據集上訓練,并在最后一個保留的子數據集上進行測試,確保所有數據得到利用。通過平均分數及標準差等指標,提供了對模型性能的真實度量
一切還得從K折交叉開始。
KFold
K折交叉在Sklearn中已經集成,此處以7折為例:
from sklearn.datasets import make_regression
from sklearn.model_selection import KFold
x, y = make_regression(n_samples=100)
# Init the splitter
cross_validation = KFold(n_splits=7)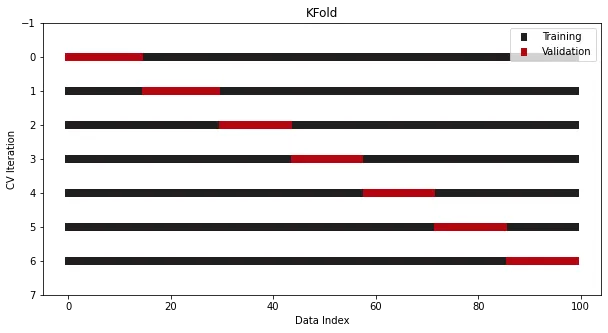
還有一個常用操作是在執行拆分前進行Shuffle,通過破壞樣本的原始順序進一步最小化了過度擬合的風險:
cross_validation = KFold(n_splits=7, shuffle=True)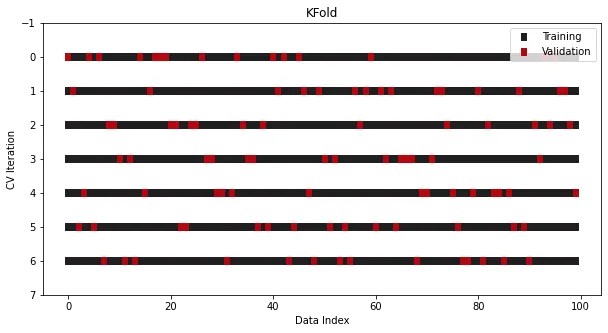
這樣,一個簡單的k折交叉驗證就實現了,記得看源碼看源碼看源碼!!
StratifiedKFold
StratifiedKFold是專門為分類問題而設計。
在有的分類問題中,即使將數據分成多個集合,目標分布也應該保持不變。比如大多數情況下,具有30到70類別比例的二元目標在訓練集和測試集中仍應保持相同的比例,在普通的KFold中,這個規則被打破了,因為在拆分之前對數據進行shuffle時,類別比例將無法保持。
為了解決這個問題,在Sklearn中使用了另一個專門用于分類的拆分器類——StratifiedKFold:
from sklearn.datasets import make_classification
from sklearn.model_selection import StratifiedKFold
x, y = make_classification(n_samples=100, n_classes=2)
cross_validation = StratifiedKFold(n_splits=7, shuffle=True, random_state=1121218)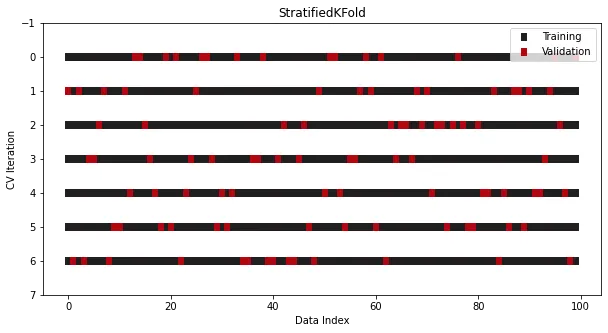
雖然看起來與KFold相似,但現在類別比例在所有的split和迭代中都維持一致。
ShuffleSplit
有的時候只是多次重復進行訓練/測試集拆分過程,也是和交叉驗證很像的一種方式。
從邏輯上講,使用不同的隨機種子生成多個訓練/測試集應該在足夠多的迭代中類似于一個穩健的交叉驗證過程。
Sklearn中也有提供接口:
from sklearn.model_selection import ShuffleSplit
cross_validation = ShuffleSplit(n_splits=7, train_size=0.75, test_size=0.25)
TimeSeriesSplit
當數據集為時間序列時,不能使用傳統的交叉驗證,這將完全打亂順序,為了解決這個問題,參考Sklearn提供了另一個拆分器——TimeSeriesSplit,
from sklearn.model_selection import TimeSeriesSplit
cross_validation = TimeSeriesSplit(n_splits=7)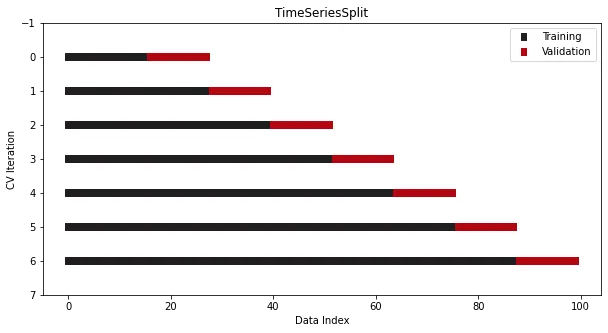
如圖,驗證集始終位于訓練集的索引之后。由于索引是日期,不會意外地在未來的日期上訓練時間序列模型并對之前的日期進行預測。
非獨立同分布(non-IID)數據的交叉驗證
前面所述方法均在處理獨立同分布數據集,也就是說生成數據的過程不會受到其他樣本的影響。
然而,有些情況下,數據并不滿足IID的條件,即一些樣本組之間存在依賴關系,Kaggle上的競賽就有出現,如Google Brain Ventilator Pressure,該數據記錄了人工肺在數千個呼吸過程中(吸入和呼出)的氣壓值,并且對每次呼吸的每個時刻進行了記錄,每個呼吸過程大約有80行數據,這些行之間是相互關聯的,在這種情況下,傳統的交叉驗證無法工作,因為拆分可能會“剛好發生在一個呼吸過程的中間”。
可以理解為需要對這些數據進行“分組”,因為組內數據是有關聯的,比如當從多個患者收集醫療數據時,每個患者都有多個樣本,而這些數據很可能會受到患者個體差異的影響,所以也需要分組。
往往我們希望在一個特定組別上訓練的模型是否能夠很好地泛化到其他未見過的組別,所以在進行交差驗證時給這些組別數據打上“tag”,告訴他們如何區分別瞎拆。
在Sklearn中提供了若干接口處理這些情況:
- GroupKFold
- StratifiedGroupKFold
- LeaveOneGroupOut
- LeavePGroupsOut
- GroupShuffleSplit
強烈建議搞清楚交叉驗證的思想,以及如何實現,搭配看Sklearn源碼是一個肥腸不錯的方式。此外,需要對自己的數據集有著清晰的定義,數據預處理真的很重要。























