













CUDA編程模型都改了!英偉達架構師團隊撰文詳解:Hopper為啥這么牛?
?在英偉達GTC 2022大會上,老黃更新了服役近兩年的安培微架構(Ampere),推出Hopper架構,并拋出一塊專為超算設計、包含800億個晶體管的顯卡Hopper H100,比老前輩A100顯卡的540億晶體管還要高出不少。
但光看名字和參數還不夠,Hopper到底牛在哪?
最近英偉達的架構開發師們發布了一篇博客,深入講解和分析了Hopper架構。文章作者包括英偉達首席GPU架構師Michael Andersch,GPU架構組杰出工程師Greg Palmer和Ronny Krashinsky,英偉達高級技術營銷總監Nick Stam,高級開發技術工程師Vishal Mehta等核心開發成員。

Hopper牛在哪?
Hopper架構的名字來自Grace Hopper女士,她被譽為計算機軟件工程第一夫人、編譯語言COBOL之母,她是耶魯大學第一位數學女博士、世界上第三位程序員、全球首個編譯器的發明者,也是第一位發現「bug」的人。

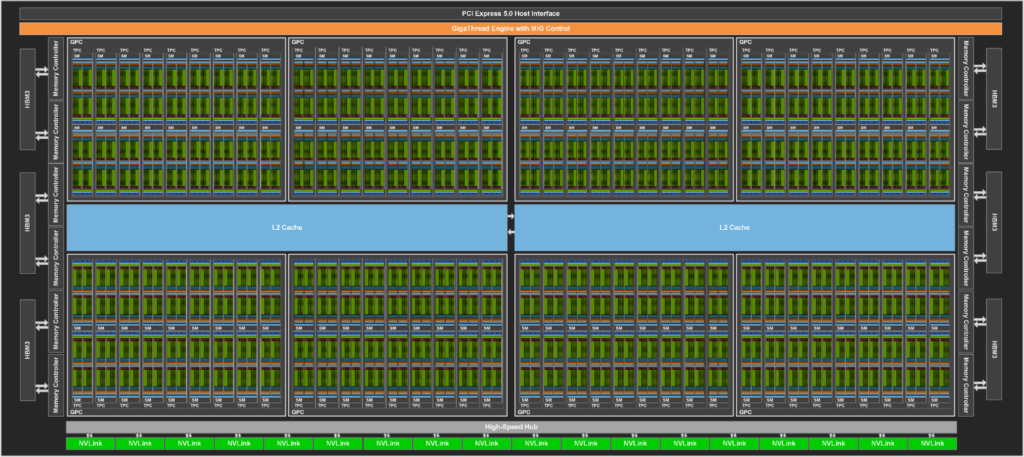
基于Hopper架構的英偉達Hopper H100張量核心GPU已經是第九代數據中心GPU了,相比上一代安培架構的A100 GPU,Hopper架構明顯強悍了很多,不僅晶體管數量有明顯提升,制作工藝也從7納米提升到4納米,為大規模AI和HPC提供了一個數量級的性能飛躍。
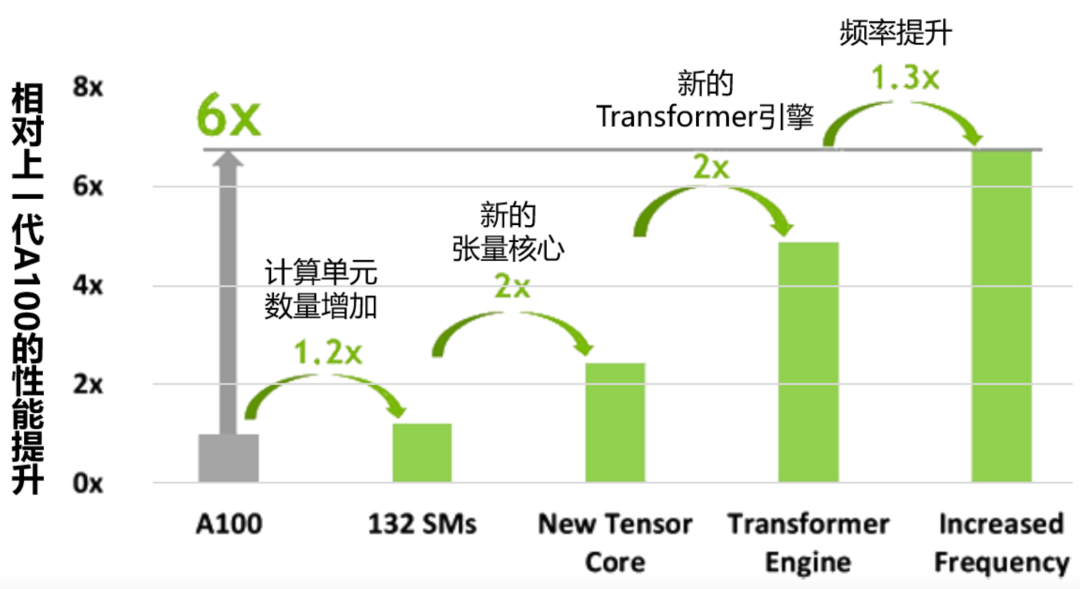
同時H100繼承了A100的主要設計重點,提升了對AI和HPC工作負載的擴展能力,并在架構效率方面進行了大幅改進。

對于當今的主流人工智能和高性能計算模型,帶有InfiniBand互連的H100可提供比A100強30倍的性能。
并且新的NVLink Switch System在針對一些大型計算工作負載任務,比如需要在多個GPU加速節點上進行模型并行化時,能夠通過互聯調整負載,可以再次提高性能。在某些情況下,性能能夠在使用InfiniBand的H100基礎上再增加兩倍。
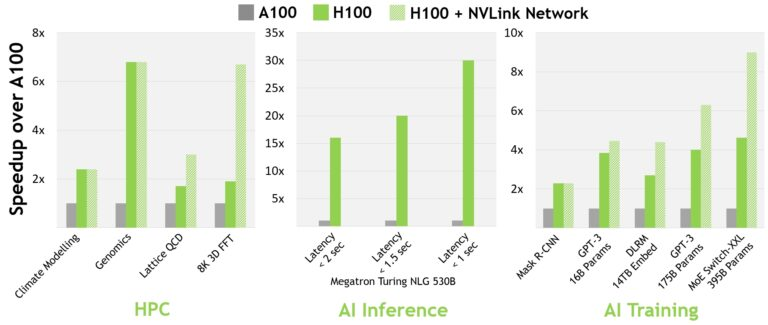
可以說H100 GPU專為高性能計算和超大規模AI模型加速而生,AI模型的推理速度少說也能提升10倍。
Hopper芯片利用了Arm架構的靈活性,是一個完全重新設計、專為加速計算而設計的CPU和服務器架構。H100能夠與英偉達Grace CPU搭配,借助超快英偉達chip-to-chip互聯,可以提供高達900GB/s的總帶寬,比PCIe Gen5還要快7倍。
在TB級數據的高性能計算下,和世界上最快的服務器相比,新設計能夠提升10倍性能和30倍的總帶寬。
開發人員總結了一個長長的H100 GPU關鍵新特性列表。
首先H100有一個新的流式多處理器(SM, streaming multiprocessor),性能和效率都有所提升。
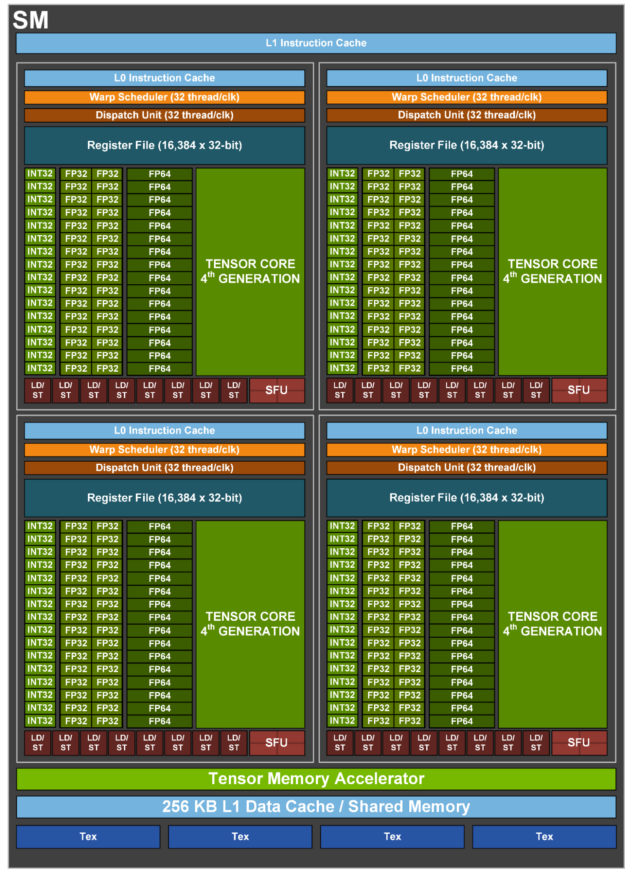
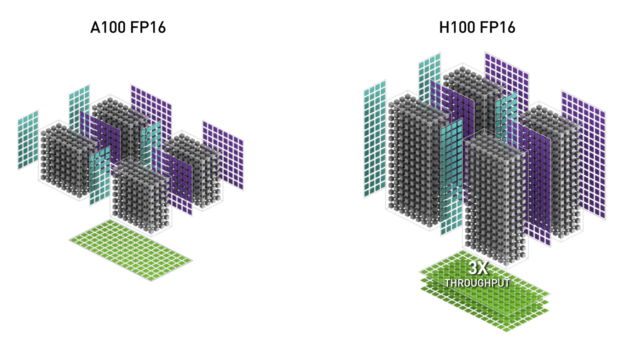
新的第四代張量核心與A100相比,chip-to-chip的性能提升6倍,速度提升主要來自更快的SM,更多的SM數量,以及H100中更高的時鐘頻率。在每個SM上,與上一代16位浮點選項相比,Tensor Cores在同等數據類型上的MMA(矩陣乘積)計算速率是A100 SM的2倍,使用新的FP8數據類型的速率是A100的4倍。稀疏性1功能利用了深度學習網絡中的細粒度結構化稀疏性,使標準張量核心操作的性能提高了一倍。
新的DPX指令對動態編程算法的加速比A100 GPU高7倍。在基因組學處理的Smith-Waterman算法,以及用于在動態倉庫環境中為機器人車隊尋找最佳路線的Floyd-Warshall算法上驗證后,證實了性能提升。
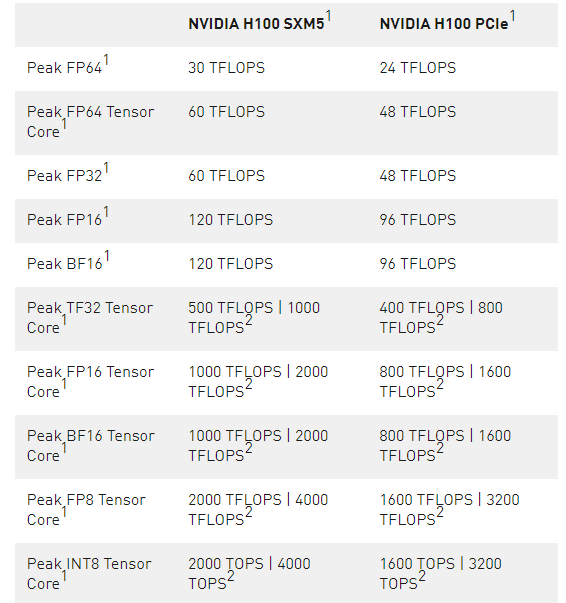
與A100相比,IEEE FP64和FP32的處理率在芯片間快了3倍,這是由于每個SM的clock-for-clock性能快了2倍,加上H100的額外SM數量和更高的時鐘。
新的線程塊集群功能能夠以大于單個SM上的單個線程塊的顆粒度對位置性進行編程控制。擴展了CUDA編程模型,為編程層次增加了一個層次,現在包括線程、線程塊、線程塊集群和網格。集群使多個線程塊可以在多個SM上并發運行,以同步和協作方式獲取和交換數據。
分布式共享內存允許在多個SM共享內存塊上進行SM到SM的直接通信,用于加載、存儲和原子學。
新的異步執行功能包括一個新的張量內存加速器(TMA)單元,可以在全局內存和共享內存之間有效地傳輸大型數據塊。TMA還支持集群中線程塊之間的異步拷貝。還有一個新的異步事務屏障,用于做原子數據移動和同步。
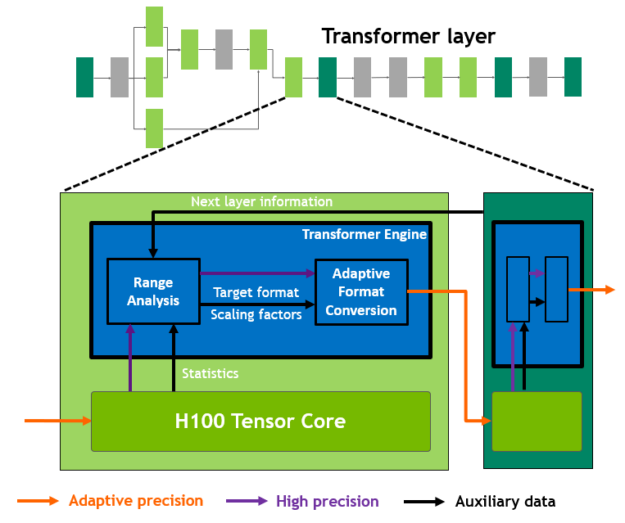
新的Transformer引擎采用了軟件和定制的英偉達Hopper Tensor Core技術的組合,專門用于加速轉化器模型的訓練和推理。Transformer引擎能夠智能管理并動態選擇FP8和16位計算,自動處理每一層中FP8和16位之間的重鑄和縮放,與上一代A100相比,在大型語言模型上的AI訓練速度提升了9倍,AI推理速度提升了30倍。
HBM3內存子系統比上一代增加了近2倍的帶寬。H100 SXM5 GPU是世界上第一個采用HBM3內存的GPU,提供領先于同級別的3TB/秒的內存帶寬。
50 MB L2 高速緩存架構緩存了大量的模型和數據集,在重復訪問時減少了對HBM3的訪問。
與A100相比,第二代多實例GPU(MIG)技術為每個GPU實例提供了約3倍的計算能力和近2倍的內存帶寬。也是首次提供具有MIG級TEE的機密計算能力。支持多達七個獨立的GPU實例,每個實例都有專用的NVDEC和NVJPG單元。每個實例都包括自己的一套性能監控器,可與NVIDIA開發人員工具一起使用。

新的機密計算(Confidential Computing)支持可以保護用戶數據,抵御硬件和軟件攻擊,并在虛擬化和MIG環境中更好地隔離和保護虛擬機(VM)。H100實現了世界上第一個原生機密計算GPU,并以全PCIe線速向CPU擴展了可信執行環境(TEE)。
第四代NVLink在all-reduce操作上提供了3倍的帶寬,比上一代NVLink增加了50%的通用帶寬,多GPU IO的總帶寬為900 GB/秒,操作帶寬是PCIe第五代的7倍。

第三代NVSwitch技術包括駐扎在節點內部和外部的交換機,用于連接服務器、集群和數據中心環境中的多個GPU。
節點內的每個NVSwitch提供64個第四代NVLink鏈接端口,以加速多GPU連接。交換機的總吞吐量從上一代的7.2 Tbits/秒增加到13.6 Tbits/秒。新的第三代NVSwitch技術還為多播和NVIDIA SHARP網內還原的集體操作提供了硬件加速。
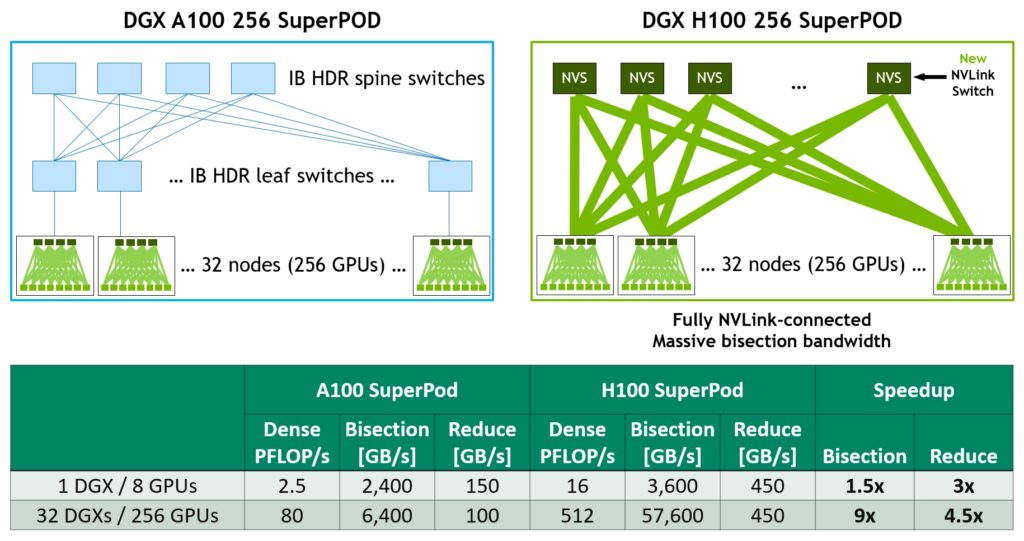
新的NVLink Switch系統互連技術和基于第三代NVSwitch技術的新的二級NVLink Switches引入了地址空間隔離和保護,使多達32個節點或256個GPU能夠通過NVLink以2:1的錐形樹狀拓撲連接起來。
這些連接的節點能夠提供57.6TB/秒的all-to-all帶寬,并能夠提供驚人的FP8稀疏AI計算的exaFLOP。PCIe Gen 5能夠提供128GB/秒的總帶寬(每個方向64GB/秒),而第四代PCIe的總帶寬為64GB/秒(每個方向32GB/秒)。PCIe Gen5使H100能夠與最高性能的x86 CPU和SmartNICs或數據處理單元(DPU)連接。

更多技術細節可以訪問原文查看。總而言之,H100就是更快、更高、更強!(更貴)


























