













Google最新《高效Transformers》闡述提升Transformers效率方式
Transformer模型是當下的研究焦點,因為它們在語言、視覺和強化學習等領域的有效性。例如,在自然語言處理領域,Transformer已經成為現代深度學習堆棧中不可缺少的主要部分。
最近,提出的令人眼花繚亂的X-former模型Linformer, Performer, Longformer等這些都改進了原始Transformer架構的X-former模型,其中許多改進了計算和內存效率。
為了幫助熱心的研究人員在這一混亂中給予指導,本文描述了大量經過深思熟慮的最新高效X-former模型的選擇,提供了一個跨多個領域的現有工作和模型的有組織和全面的概述。

論文鏈接:https://arxiv.org/abs/2009.06732
介紹
Transformer是現代深度學習領域中一股強大的力量。Transformer無處不在,在語言理解、圖像處理等許多領域都產生了巨大的影響。因此,在過去的幾年里,大量的研究致力于對該模型進行根本性的改進,這是很自然的。這種巨大的興趣也刺激了對該模式更高效變體的研究。
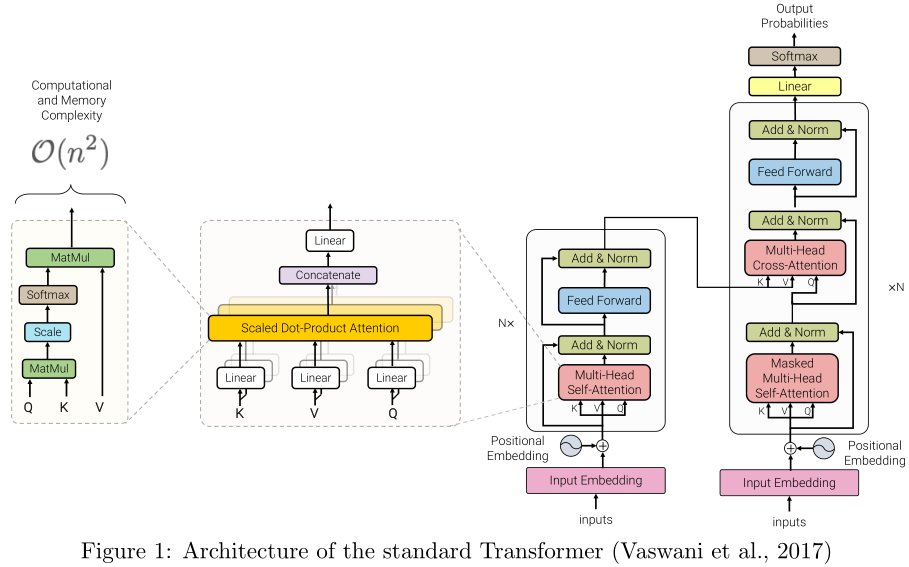
最近出現了大量的Transformer模型變體,研究人員和實踐者可能會發現跟上創新的速度很有挑戰性。在撰寫本文時,僅在過去6個月里就提出了近12種新的以效率為中心的模式。因此,對現有文獻進行綜述,既有利于社區,又十分及時。
自注意力機制是確定Transformer模型的一個關鍵特性。該機制可以看作是一種類似圖的歸納偏差,它通過基于關聯的池化操作將序列中的所有標記連接起來。一個眾所周知的自注意力問題是二次時間和記憶復雜性,這可能阻礙模型在許多設置的可伸縮性。最近,為了解決這個問題,出現了大量的模型變體。以下我們將這類型號命名為「高效Transformers」。
根據上下文,可以對模型的效率進行不同的解釋。它可能指的是模型的內存占用情況,當模型運行的加速器的內存有限時,這一點非常重要。效率也可能指計算成本,例如,在訓練和推理期間的失敗次數。特別是對于設備上的應用,模型應該能夠在有限的計算預算下運行。在這篇綜述中,我們提到了Transformer在內存和計算方面的效率,當它們被用于建模大型輸入時。
有效的自注意力模型在建模長序列的應用中是至關重要的。例如,文檔、圖像和視頻通常都由相對大量的像素或標記組成。因此,處理長序列的效率對于Transformer的廣泛采用至關重要。
本篇綜述旨在提供這類模型的最新進展的全面概述。我們主要關注的是通過解決自注意力機制的二次復雜性問題來提高Transformer效率的建模進展和架構創新,我們還將在后面的章節簡要討論一般改進和其他效率改進。
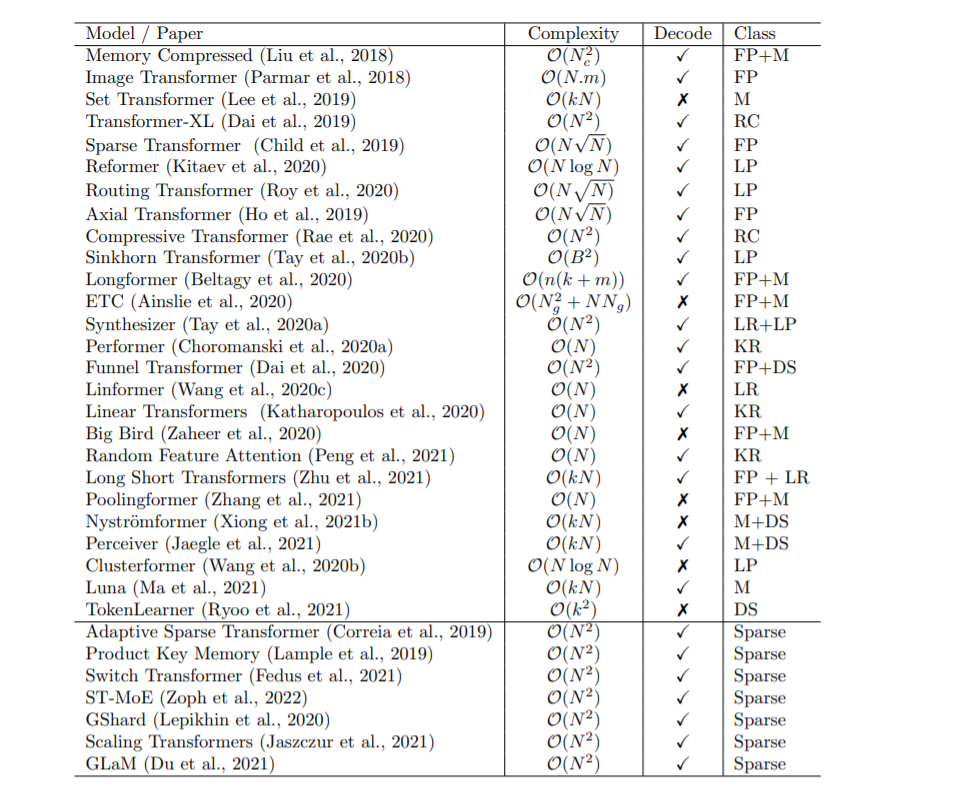
本文提出了一種高效Transformer模型的分類方法,并通過技術創新和主要用例對其進行了表征。特別地,我們回顧了在語言和視覺領域都有應用的Transformer模型,試圖對各個領域的文獻進行分析。我們還提供了許多這些模型的詳細介紹,并繪制了它們之間的聯系。
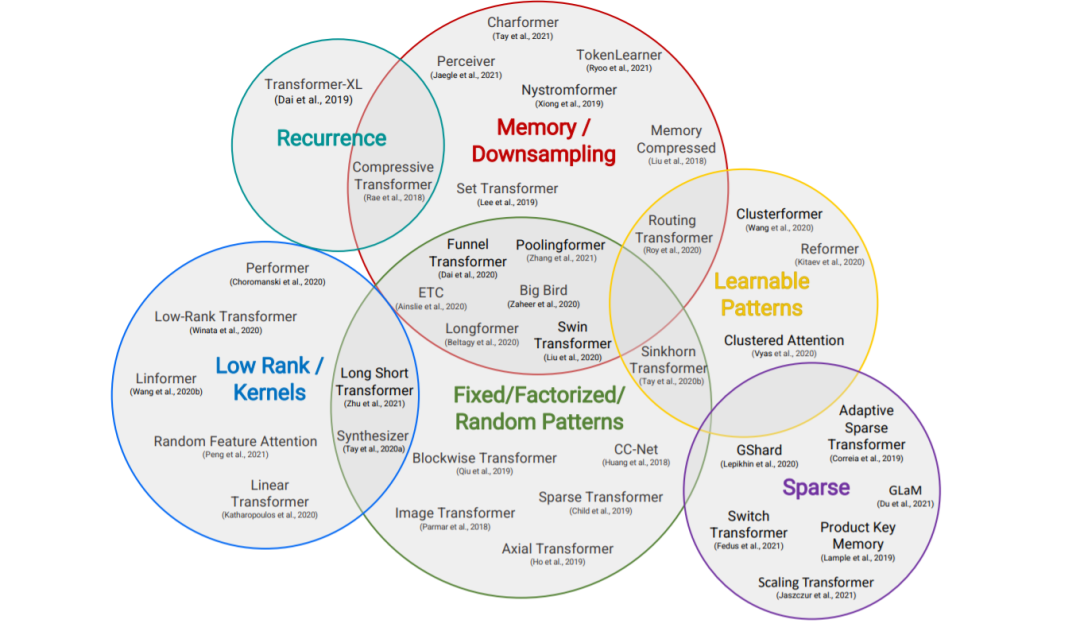
本節概述了高效Transformer模型的一般分類,以其核心技術和主要用例為特征。盡管這些模型的主要目標是提高自注意機制的內存復雜度,但我們還包括了提高Transformer體系結構的一般效率的方法。
固定模式(FP)——對自注意最早的修改是通過將視野限制在固定的、預定義的模式(如局部窗口和固定步距的塊模式)來簡化注意力矩陣。
組合模式(CP)——組合方法的關鍵思想是通過組合兩個或多個不同的訪問模式來提高覆蓋率。例如,Sparse Transformer通過將一半的頭部分配給每個模式,將跨步注意力和局部注意力結合起來。類似地,軸向Transformer運用了一系列以高維張量作為輸入的自注意計算,每個計算都沿著輸入張量的單個軸。從本質上說,模式的組合以與固定模式相同的方式降低了內存復雜度。但是,不同之處在于,多個模式的聚合和組合提高了自注意機制的整體覆蓋率。
可學習的模式(LP) -固定的,預先確定的模式的擴展是可學習的模式。不出所料,使用可學習模式的模型旨在以數據驅動的方式學習訪問模式。學習模式的一個關鍵特征是確定令牌相關性的概念,然后將令牌分配到桶或集群。值得注意的是,Reformer 引入了一種基于哈希的相似性度量,以有效地將令牌聚為塊。類似地,路由Transformer對令牌使用在線k-means聚類。同時,Sinkhorn排序網絡通過學習對輸入序列的塊進行排序,暴露了注意權值的稀疏性。在所有這些模型中,相似函數與網絡的其他部分一起端到端訓練。可學習模式的關鍵思想仍然是利用固定模式(塊狀模式)。然而,這類方法學會了對輸入標記進行排序/聚類——在保持固定模式方法的效率優勢的同時,實現了序列的更優全局視圖。
神經記憶——另一個突出的方法是利用可學習的側記憶模塊,它可以一次訪問多個令牌。一種常見的形式是全局神經存儲器,它能夠訪問整個序列。全局標記充當一種模型內存的形式,它學習從輸入序列標記中收集數據。這是在Set transformer中首次引入的誘導點方法。這些參數通常被解釋為「內存」,用作將來處理的臨時上下文的一種形式。這可以被認為是參數關注的一種形式。ETC 和Longformer也使用了全局記憶令牌。在有限的神經記憶(或誘導點)中,我們能夠對輸入序列執行一個初步的類似于池的操作來壓縮輸入序列——在設計高效的自注意模塊時,這是一個可以隨意使用的巧妙技巧。
低秩方法——另一種新興的技術是通過利用自注意矩陣的低秩近似來提高效率。
內核——另一個最近流行的提高transformer效率的方法是通過內核化來查看注意力機制。
遞歸——塊方法的一個自然擴展是通過遞歸連接這些塊。
下采樣——另一種降低計算成本的常用方法是降低序列的分辨率,從而以相應的系數降低計算成本。
稀疏模型和條件計算——雖然不是專門針對注意力模塊,稀疏模型稀疏地激活一個參數子集,這通常提高了參數與FLOPs的比率。























