特斯聯打造聯邦學習算法引擎盤活城市靜默數據
數據是人工智能及機器學習的基礎。隨著人工智能從計算、感知階段發展到認知階段,其進一步發展對數據的需求量亦在逐步攀升。然而在大多數行業中,囿于各種各樣的原因,數據常常以孤島的形式存在——即使是在同一個公司的不同部門之間,要實現數據的集中整合也面臨著重重阻力——在現實中將分散在各地、各個機構的數據進行整合幾乎是不可能做到的事,其成本也十分高昂。此外,隨著人工智能的進一步發展,數據的隱私和安全業已成為了世界性的議題。
針對人工智能發展及其所面臨的數據孤島和數據隱私的兩難問題,聯邦機器學習(Federated Machine Learning)即為能有效幫助多個機構在滿足用戶隱私保護、數據安全和政府法規的要求下,進行數據使用和機器學習建模的機器學習框架。
日前特斯聯所打造的德陽科創中心正式落地運營。德陽科創中心的設立旨在充分貫通學術生態和產業生態,以“成本共擔”的方式,為周邊的中小微企業提供AI所需的算力、數據、算法模型等核心要素,讓各體量、具備不同AI基礎的企業均能通過學術機構所研發出的模型,以低代碼、模塊化的生產方式依據自身的需求,實現自有知識產權算法的孵化及既有成熟算法的調用,而支撐產業算法孵化的原料來自于學術科研生態的研究成果——預訓練模型。
通過聯邦學習的核心技術,特斯聯向學術科研生態提供科研的原料——城市及產業數據——并將算力下沉至數據端,形成聯邦學習智算節點,通過九章算法賦能平臺為學術科研提供服務。
據特斯聯透露,在聯邦學習方向,特斯聯基于九章算法賦能平臺打造了聯邦學習算法引擎,以其作為研究型算法孵化平臺的核心。目前聯邦學習算法引擎已支持橫向聯邦學習算法和縱向聯邦學習算法,通過AI-Research-Studio,向學術科研生態提供基于聯邦學習數據使用的API接口。
本文通過城市用電數據以聯邦樹模型及聯邦神經網絡的算法實現預測類預訓練模型的研究實踐,對特斯聯打造的聯邦學習算法引擎進行介紹。
橫向聯邦學習:支持跨場域高重疊數據特征機器學習
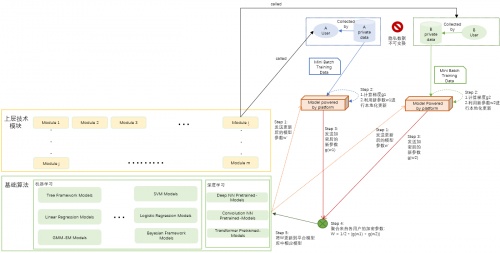
特斯聯聯邦學習算法引擎橫向聯邦學習架構圖
橫向聯邦學習主要應用于具有相同特征樣本、用戶重疊度較少的數據集。
科研人員通過查看數據樣例來確定這些數據是否滿足科研要求,在滿足要求的情況下,通過調用聯邦學習的API實現數據的使用。而特斯聯聯邦學習算法引擎的橫向聯邦學習內部運行過程主要由如下幾步構成:
各智算節點從中心安全可信服務器中下載由科研人員提供需要訓練的模型;
每個智算節點利用本地數據訓練模型(無需上傳本地數據),將數據加密梯度上傳至中心安全可信服務器,并由中心安全可信服務器聚合各數據持有方的梯度更新模型參數;
中心安全可信服務器依據貢獻度,將更新后的模型返回至各智算節點;
各智算節點更新各自模型,并從第2步重復直至訓練完成;
完成訓練后,研究人員即可使用模型完成其目標任務。
特斯聯所打造引擎的橫向聯邦學習部分目前已實現基于聯邦DNN實現片區用電數據的打通。通過上述橫向聯邦學習步驟完成訓練后,引擎可實現一鍵部署,并為用戶提供相應的API調用接口——后續可直接面向科研人員提供服務,在保證數據安全的前提下實現預訓練模型的研究。
縱向聯邦學習:面向固定場域低重疊數據特征機器學習
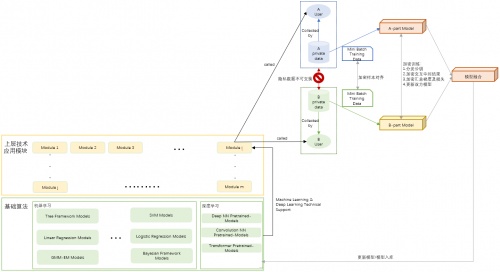
特斯聯聯邦學習算法引擎縱向聯邦學習架構圖
與橫向聯邦學習不同,縱向聯邦學習主要應用于具有用戶重疊較多而特征重疊較少的特性的數據集。
具體而言,科研人員通過查看數據樣例來確定這些數據是否滿足科研要求,在滿足要求的情況下,通過調用聯邦學習的API實現數據的使用。特斯聯的聯邦學習算法引擎的縱向聯邦學習過程由如下幾步構成:
中心安全可信服務器通過特定選擇及評估機制,將科研人員提供的算法模型打散成多個小模型(如圖示中將原模型分解為A-part和B-part兩部分),然后分發到每個智算節點下。中心保留模型完整結構信息和各小模型在各方節點的信息;
引擎參考SecureBoost算法的去中心化思想,每個智算節點自行完成加密中間結果的交互,其中包括各數據持有方的小模型計算結果,梯度等;
各智算節點完成加密中間結果的交互后,各智算節點方(如圖示A)均可從其他智算節點(如圖示B)中收集到加密梯度統計,然后進行聚合產生最優解,再反饋至其他智算節點;重復第2步,共同完成聯合建模;
完成聯合建模后,各智算節點的小模型信息更新至中心安全可信服務器,各智算節點的小模型依舊存儲在其本地;
在使用模型預測時,中心安全可信服務器通過基于各小模型節點信息,聯合調用各方小模型共同完成推算。
特斯聯打造的聯邦學習算法引擎的縱向聯邦學習部分目前已應用于基于SecureBoost算法通過城市用電數據的接入,實現預測類預訓練模型的研究和抽象。在穩定性實驗下,基于SecureBoost算法所實現的城市用電預測模型和傳統本地訓練模型的結果進行對比,預測結果誤差在8%左右;在準確率實驗下,多縱向節點聯合建模的城市用電預測模型相對于單節點建模的結果進行對比,性能提升了30%,即多縱向節點聯合建模的預測結果相較于標簽結果的誤差更小。特斯聯將這一模型進行抽象化封裝,以應用于跨行業的更多場景。
通過用電數據抽象預測類預訓練模型
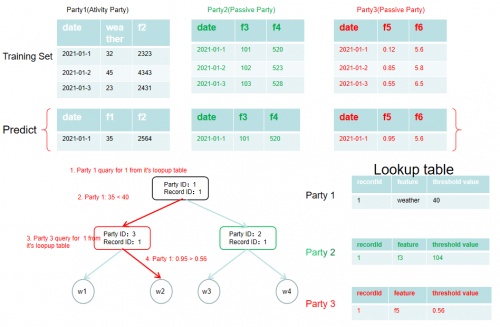
城市用電量預測算法圖示
具體在城市用電案例下,由于數據的保密性,聯邦學習算法引擎得到的特征都經過脫敏處理。在具體的操作過程中,首先,我們考慮一個具有三個parties(參與方)的系統,如圖所示,其中party2和party3為passive parties(被參與動方),party1是一個activity party(主動方)。我們首先通過前述算法訓練得到一個樹模型,并生成對應的lookup table(查找表)。為了預測在2021年1月1日的用電量,三個參與方將協作工作,由主動方調動被動方完成。首先從根節點開始,通過[party id:1, record id:1]的記錄,主動方可以知道其所控制節點的劃分,主動方則可通過其對應的查找表找到對應的劃分屬性和閾值。通過這一過程我們可以發現相應節點是通過屬性weather(天氣)進行劃分的,且劃分閾值為40,因此該節點落下左節點,依次類推,一直到達葉子節點。而這個模型通過抽象轉化可應用于其他行業的預測領域。通過前述過程可進一步達到去中心化效果,實現數據的跨行業使用,訓練過程中無需數據擁有方的直接參與,科研機構即可使用上述能源數據實現跨界的預測算法研究,解決單邊數據規模小和標簽樣本少的問題,同時,也降低了能源數據泄露的幾率,提升數據的安全性。
提升數據可及性及安全性,聯邦學習推動AI與各行各業深度滲透
事實上,針對用電數據的模型化抽象僅是特斯聯聯邦學習數據應用場景的冰山一角,特斯聯將行業數據根據技術分類進行抽象,按視頻圖像、自然語言處理、推薦預測、知識圖譜進行歸類劃分,通過API對科研機構、高校提供數據服務。科研機構高校將研究的成果以預訓練模型的形式通過九章算法賦能平臺的弱監督大模型技術向產業提供低門檻、高質量的人工智能算法孵化功能。
在特斯聯看來,能夠盤活城市中龐大的沉默數據資源,使數據真正有效地為行業所應用即為其打造科創中心最大的價值。特斯聯德陽科創中心負責人認為,作為人工智能發展的三大核心要素之一,數據是人工智能得以不斷向前發展的基礎,“可以說未來行業的發展與數據的可及性、安全性是正相關的。通過打造聯邦學習算法引擎,我們希望在確保數據隱私的同時,為各個行業尤其是中小微企業降低數據獲取的門檻,推動AI與各行各業更深度地綁定。這也是推動AI普惠化發展必經的一段路程。”