16萬視頻對、28萬對片段,螞蟻開源視頻侵權檢測超大數據集
?傳統的版權保護行業費時、費力、成本高,海量內容難以全量保護,內容分發難以掌控傳播的安全問題。區塊鏈技術具有不可篡改、追根溯源、分布式共識等特點,和數字版權保護具有天然契合之處,將區塊鏈技術與 AI 多媒體侵權檢測技術相結合,極大降低了版權維權成本,提升版權保護效率,同時也為網絡版權的存證、交易、維權提供了新的途徑。因此,螞蟻集團 - 數字科技線推出了一站式數字內容原創保護平臺 「鵲鑿」,圖片視頻等內容一鍵上鏈,快速完成版權存證,在司法機關和公證機構的共同見證下,成為“盜版維權” 的鐵證。
相關的產品介紹可見于官網:https://www.mydcs.com/pages/index
在版權保護中,視頻侵權檢測能力是極為重要的一部分。現如今,盜版視頻的猖獗不僅讓視頻網站損失慘重,同時給內容創作者帶來經濟和精神上的損失更是不可估量。2021 年 4 月,中宣部版權局提出,加大對視頻侵權行為的打擊力度。近些年,包括二次創作、視頻剪輯在內的侵權手段層出不窮,盜版視頻的侵權樣例也不僅局限在簡單的盜攝或者加水印等容易被識別的方式。因此面向版權保護的視頻侵權檢測方法就變得尤為重要,針對這一系列問題,基于 AI 的多媒體比對算法技術,能夠顯著地節省人工審核的成本,提高侵權取證的效率,實現在大范圍檢索情況下做出精確的識別,是解決視頻侵權問題的有效方案。
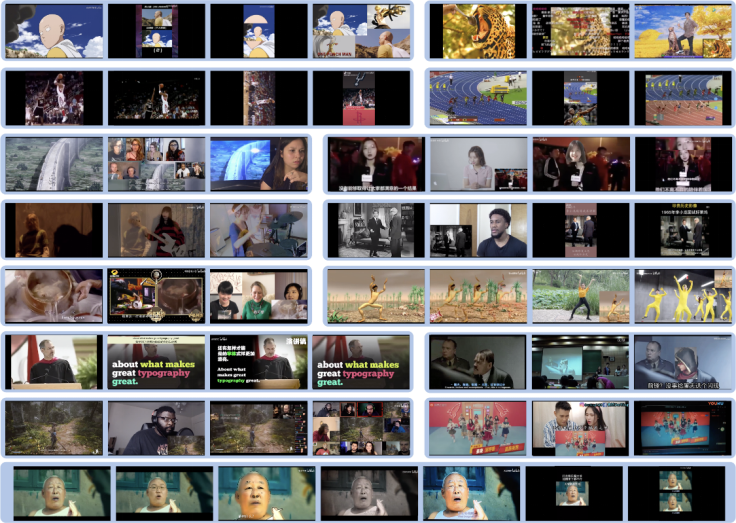
圖 1. 螞蟻構建大規模視頻侵權數據集(VCSL)中的典型侵權樣例
但是目前針對版權侵權檢測,尤其是視頻侵權這一領域在學術界和產業界都存在著一些瓶頸問題,主要體現在下面三點:
- 數據集,目前學術界已經開源的數據集大部分都是只有視頻級別的標注(Trecvid[1], SVD[2], FIVR[3]),即視頻對之間只標注了是否侵權,而并未標注兩個視頻之間實際侵權的時間片段(即侵權起始時間位置和結束時間位置)。目前開源的擁有片段級別標注的數據集僅有 2014 年 ECCV 上開源的 VCDB 數據集[4],但這個數據集規模比較小,僅有 6k 對實際侵權的視頻對,這也會在后面的章節進行介紹。
- 算法評價指標,在學術界中,視頻級別的拷貝檢測評價指標比較成熟,但是片段粒度的拷貝檢測準確度的評價指標仍然存在著比較多的問題。之前 VCDB 論文中提出的評價指標在實際的實驗測試中出現了一系列指標上的偏差以及應用上的問題。
- 侵權定位算法,侵權定位算法,在這里侵權定位(Temporal Alignment)算法指的是在提取出兩段視頻的時序特征后,需要輸出兩段視頻侵權的時間片段。大部分侵權定位的算法都是不開源的,因此學術界也無法形成一個完善的 benchmark,視頻拷貝檢測和侵權定位這個領域也相對較為停滯。
針對以上三個主要問題,該研究做了大量的視頻拷貝檢測和侵權定位相關的研究工作,包括了:
- 提出了目前最大規模(超過現有其他數據集 2 個數量級規模)的視頻侵權定位數據集,包括了超過 16 萬對侵權視頻對,28 萬對侵權片段,并且涵蓋了大量的視頻領域和視頻時長。
- 提出了全新的視頻片段拷貝檢測的評價指標,該評價指標充分考慮到了視頻拷貝檢測這個任務的特殊性,并且在實際場景下體現出了更好的適應性。
- 提出了關鍵幀和侵權定位端到端的模型 SSAN 并達到了現階段最高指標,并且將現階段學術界的常見侵權定位算法進行復現并且開源,形成了完善全面的視頻侵權定位 benchmark。
上面的成果已經分別被計算機視覺頂會 CVPR 和多媒體頂會 ACM MM 成功錄用和發表。

- CVPR 2022 VCSL 論文:https://arxiv.org/abs/2203.02654
- VCSL 數據集和評測以及算法代碼:https://github.com/alipay/VCSL
大規模視頻片段拷貝檢測數據集 VCSL針對上一節提出的現有數據集問題,該研究希望提出一個全面的數據集,滿足下面的要求:
- 視頻拷貝的類型必須要盡可能的全面,但是要避免過度變換使得侵權的視頻基本不具備觀賞性。
- 視頻類型必須覆蓋常見的視頻種類,比如電影、電視劇、動畫、體育等不同場景。
- 視頻時長分布盡可能廣泛,不要局限于只是短視頻或者只是長視頻。
基于以上三個要求,該研究打標完成了 VCSL(Video Copy Segment Localization)數據集。研究者從 Youtube 和 Bilibili 上選取了 122 個種子視頻,每個種子視頻也與關鍵詞相關聯。在打標過程中,研究者模擬了真實情況,讓打標同學進行搜索找到可能侵權的視頻然后再進行打標比對,濾除不相干的視頻并標注出實際侵權的時間片段。
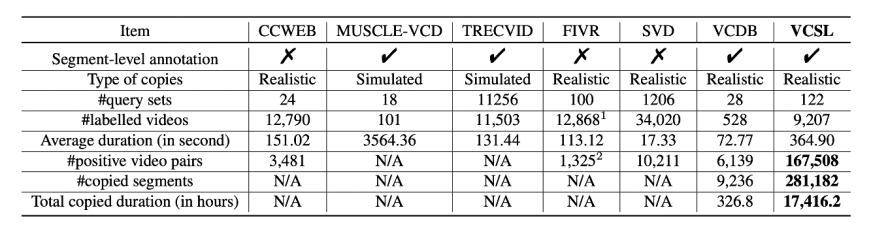
表 1. VCSL 與其他學術界現有數據集的比較
VCSL 數據集與學術界其他數據集的對比由表 1 所示,可以看到 VCSL 在侵權視頻對數量和侵權片段數量上都比現有學術界數據集高出兩個數量級。并且在視頻時長、侵權片段時長、視頻種類的分布上更加廣泛。
視頻片段拷貝檢測的新評價指標
學術界范圍內,之前在 Muscle-VCD[5]和 VCDB[4]中提出過片段級別拷貝檢測的評價指標,這幾年比較常見的學術界工作主要用了 VCDB[4]中定義的片段的準確率和召回率:

準確率和召回率的分子均為正確被檢測到的片段,其中正確檢測到的片段定義為只要與實際的侵權片段有一幀的重合即定義為正確檢測。準確率的分母為所有被檢測到的片段數量,召回率的分母為實際打標真實拷貝的片段數量。另外,VCDB 論文中還定義了幀的準確率和召回率:

與片段粒度類似,只不過統計維度是在幀粒度。
上述提到的片段準確率 / 召回率和幀準確率 / 召回率都有其局限性。最重要的一點是,該評價指標只適合于片段和視頻的拷貝檢測,即需要打標好的被侵權片段與可能侵權的視頻作為輸入,而不是兩段完整的視頻作為輸入,這種評價方式在實際場景下是不現實的。同時,對于片段準確率 / 召回率,檢測到的片段只要和實際的打標片段有一幀重疊就認為是正確的計算方式,會導致評價指標對侵權定位的準確度的感知比較差。另外,這些指標沒有考慮到視頻拷貝的一些重要特性,即下面提到的切分等效性。
之前的評價指標需要將標注好的片段和視頻比較,這個并不適合于實際的應用。在該研究提出的評價指標中,他們用兩個完整的視頻作為輸入來檢測這兩個視頻中可能存在的拷貝片段。另外,該研究在觀察視頻拷貝的標注數據中發現了視頻拷貝一個特性,即片段切分等效特性。這種特性是由于在某些情況下,很難確定拷貝片段的邊界,如下圖所示,視頻部分的中間幀被修改以及短暫插入其他視頻幀,如下圖 2(a)所示,另外圖 2(b)這種混剪的情況也類似,該研究認為在這些情況下,將拷貝視頻片段標注為一整段和多段連續的片段都是合理的。因此該研究在設計新的評價指標時,需要將這種片段切分等效特性考慮進去,使得評價指標對這種切分是魯棒的。

圖 2. 視頻侵權案例,(a),(b)圖左側為按時間排布的視頻畫面幀,右側為視頻幀序列相似圖,橫軸和縱軸分別代表著兩個視頻的時間軸,黑框內表示實際標注的侵權事件片段,詳細解釋圖也可見于后文圖 6 右側。
這個評價指標的表示可以通過視頻幀相似圖進行表示,如下圖所示。拷貝片段對在相似圖上表現為一個檢測框,而這個拷貝片段,可以表現為在相似圖上的一條直線,這表示了幀的順序對應。而橘黃色框表示實際打標的 GT 拷貝片段,藍色框表示算法輸出的預測拷貝片段。
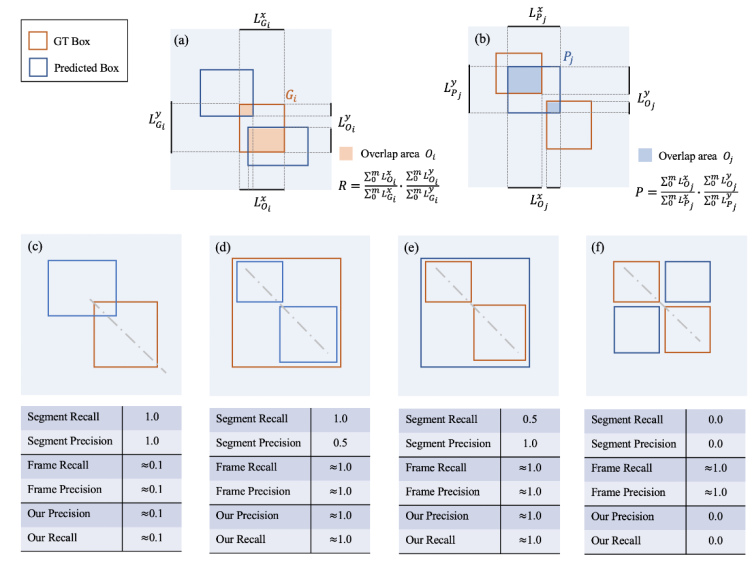
圖 3. (a-b)描述了該研究提出的算法計算過程,(c-f)描述了四種對比該研究提出的評價指標和之前指標對比的簡化情況。虛線表示侵權幀在時域上的位置,同時也會有其他更復雜的侵權情況表現為更復雜的 pattern。
具體來說,首先該研究找到每個 GT 框與所有的預測框的交際區域,如上圖 (a) 所示,接下來計算這個交疊區域在 x 軸和 y 軸上的并集長度。同時計算出每個 GT 框的長度和寬度,最后分子為交疊區域的并集長度相加,分母為 GT 框的長度相加,即可得到 recall,如上圖 (a) 所示。類似的,首先該研究找到每個預測框與所有 GT 框的交際區域,如上圖 (b) 所示,接下來計算這個交疊區域在 x 軸和 y 軸上的并集長度。同時計算出每個預測框的長度和寬度,最后分子為交疊區域的并集長度相加,分母為預測框的長度相加,即可得到 precision,如上圖 (b) 所示。
值得注意的是,該研究并沒有用學術界常用的面積,而是采用了 x y 軸的投影進行計算,這是為了評價指標對片段切分更加魯棒。最后,將 recall 和 precision 結合,得到 F-score,作為評價參數。
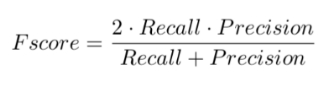

視頻片段拷貝檢測算法 benchmark
首先將視頻拷貝檢測算法的處理流程分為三個部分:視頻預處理,視頻特征提取和視頻侵權定位,如下圖所示。
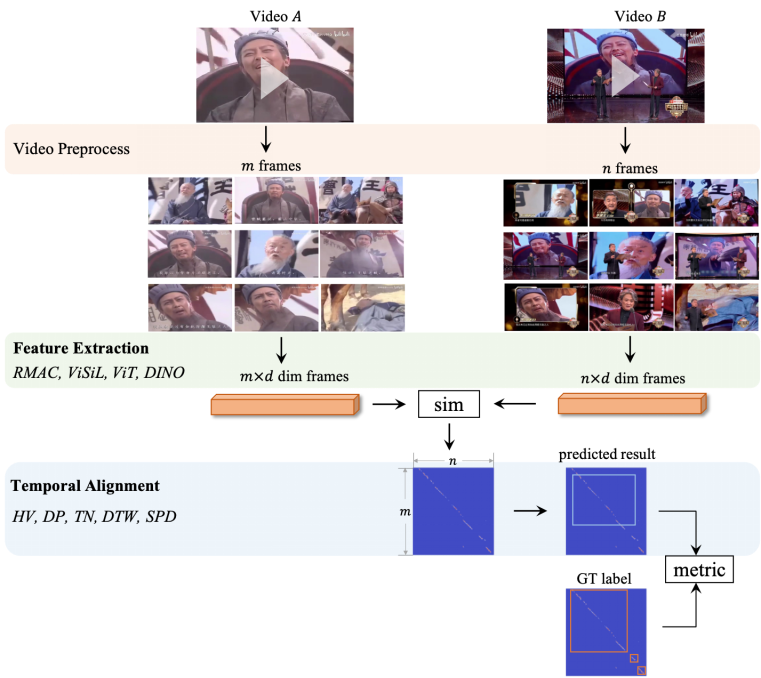
圖 4. 視頻拷貝檢測算法處理流程。
基于 VCSL 數據集和新的評價指標,該研究首先復現了目前常見的侵權定位算法,包括霍夫投票(Hough Voting)、時域網絡(Temporal Network)、動態規劃(Dynamic Programming)、動態時間扭曲(Dynamic Time Warping),并結合常見的開源幀特征算法,得到如下圖所示的 benchmark。
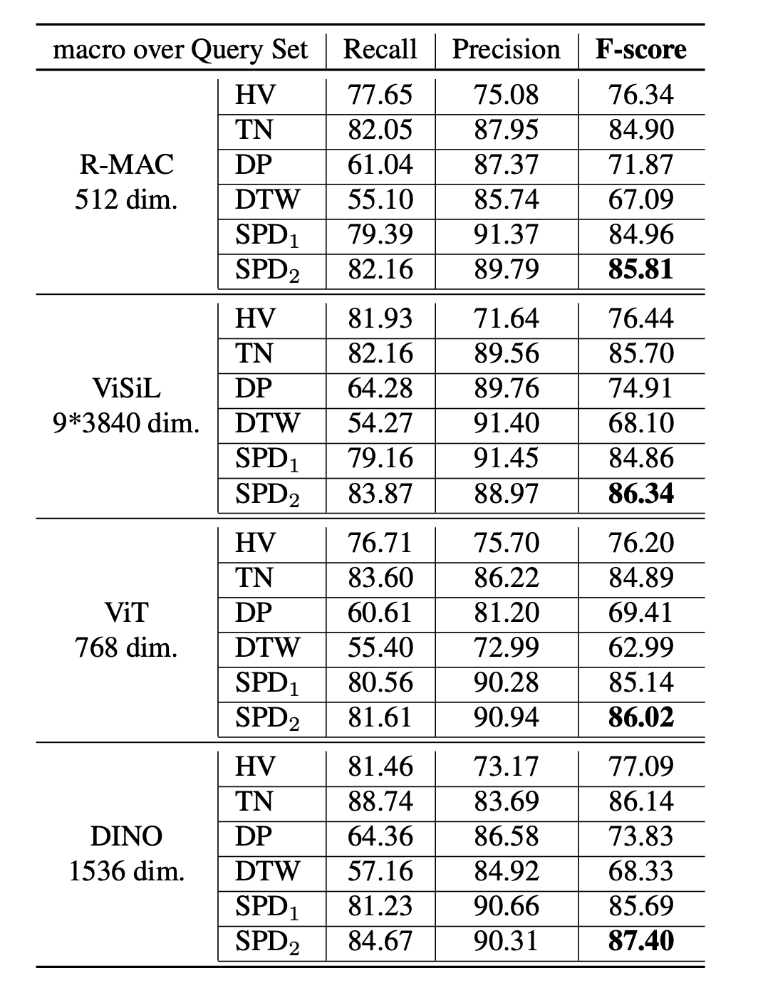
其中 SPD 是該研究團隊在去年 ACM MM21 中提出的侵權定位算法,也是當前視頻侵權定位效果最好的算法。其中 SPD 下劃線 1 表示在之前開源數據集 VCDB 上訓練的效果,下劃線 2 表示在 VCSL 數據集上訓練的效果。可以看到后者效果好于前者,這也說明了大規模數據集的重要性。
這里也簡單介紹下該研究在 ACM MM21 上發表的論文《Learning Segment Similarity and Alignment in Large-Scale Content Based Video Retrieval》,他們提出了一種視頻片段相似度和定位網絡(Segment Similarity and Alignment Network,SSAN),主要由兩個部分組成:自監督關鍵幀檢測 (Self-supervised Keyframe Extraction,SKE) 和相似圖侵權定位檢測(Similarity Pattern Detection,SPD)。關鍵幀檢測(SKE)主要用于提取魯棒且有代表性的關鍵幀,去除相似冗余幀;相似圖侵權定位檢測(SPD)主要用于視頻相似片段定位。整個 SSAN 可以端到端進行訓練,得到現階段最好的片段級別侵權定位效果。
論文地址:https://dl.acm.org/doi/abs/10.1145/3474085.3475301
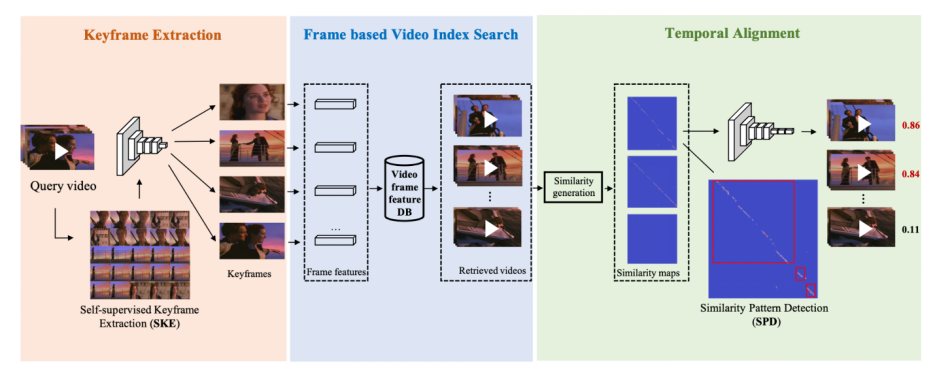
圖 5. SSAN 算法結構,包括了關鍵幀抽取模塊,基于幀的視頻檢索和時域侵權定位模塊
在相似圖侵權定位檢測(SPD)這個模塊中,該研究巧妙地將侵權定位問題轉變成一個目標檢測問題,如下圖所示,這樣就只需要極少的運算量就可以得到侵權定位的結果,并且具有多段侵權檢測能力。
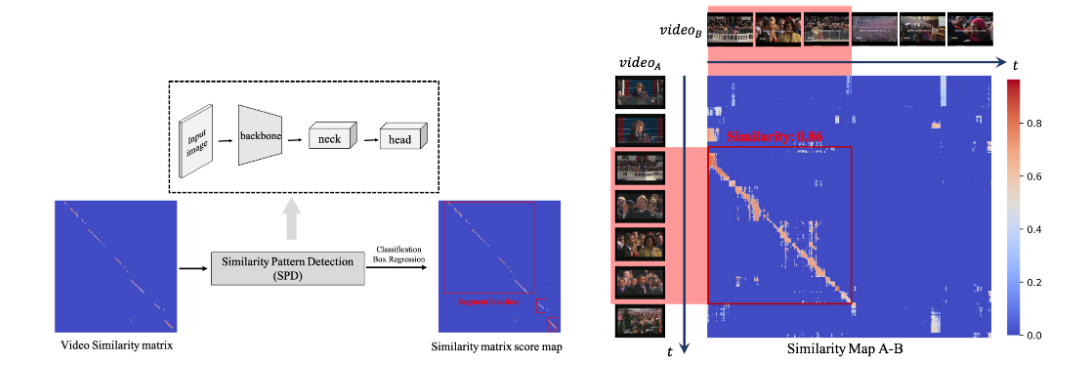
圖 6. 左圖,時域侵權定位 SPD 算法示意圖,右圖,相似圖生成與原視頻對示意圖