數據湖與數據倉庫之間的五大差異
根據Google的說法,對“大數據”的興趣已經持續了好幾年,而且在過去幾年里真正的興起。這篇文章的目的是為了幫助突出數據湖泊和數據倉庫之間的差異,幫助您就如何管理數據做出明智的決定。

我們這些數據和分析從業者當然聽過這個詞,當我們開始與客戶討論大數據解決方案時,談話自然轉向了對數據湖的討論。但是,我經常發現客戶要么沒有聽說過這個詞,要么沒有很好地理解它的含義。
數據倉庫
維基百科,將數據倉庫定義為:
“...來自一個或多個不同來源的綜合數據的中央存儲庫。他們存儲當前和歷史數據,并用于創建高級管理報告的趨勢報告,如年度和季度比較。“
這是一個非常高層次的定義,它描述了數據倉庫的目的,但沒有解釋如何達到目的。
我會繼續添加一個數據倉庫有以下屬性:
- 它代表了由主題領域組織的業務的抽象圖片。
- 這是高度轉變和結構。
- 在定義使用數據之前,數據不會被加載到數據倉庫中。
- 它通常遵循諸如Ralph Kimball和Bill Inmon所定義的方法。
數據湖
Pentaho首席技術官詹姆斯·迪克森(James Dixon)通常被稱為“數據湖”(data lake)。他描述了一個類似于一瓶水的數據集市(數據倉庫的一個子集)...“清理,打包和結構化以便于消費”,而數據湖更像是一個自然狀態的水體。數據從流(源系統)流向湖。用戶可以進入湖泊進行檢查,采樣或潛水。
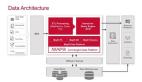
現代數據架構中的數據湖這也是一個相當不精確的定義。我們來添加一個數據湖的一些特定屬性:
- 所有數據都從源系統加載。沒有數據被拒絕。
- 數據以未轉換或幾乎未轉換的狀態存儲在葉級。
- 數據被轉換,模式被應用來滿足分析的需要。
接下來,我們將重點介紹數據湖的五個關鍵區別以及它們與數據倉庫方法的對比。
1. Data Lakes保留所有數據
在開發數據倉庫的過程中,花費大量時間分析數據源,了解業務流程和分析數據。其結果是設計用于報告的高度結構化的數據模型。這個過程的很大一部分包括決定要包含哪些數據,而不包括在倉庫中。一般來說,如果數據不是用來回答特定的問題或在一個定義的報告中,它可能被排除在倉庫之外。這通常是為了簡化數據模型,并節省昂貴的磁盤存儲上的空間,用于提高數據倉庫的性能。
相比之下,數據湖保留所有數據。不僅僅是今天正在使用的數據,還有可能使用的數據,甚至可能永遠不會被使用的數據。數據也一直保存下來,以便我們能及時回到任何一點做分析。
這種方法成為可能,因為數據湖的硬件通常與用于數據倉庫的硬件大不相同。商品,現成的服務器與便宜的存儲相結合,使數據湖擴展到TB級和PB級相當經濟。
2.數據湖支持所有數據類型
數據倉庫一般由從事務系統中提取的數據組成,并由定量度量和描述它們的屬性組成。Web服務器日志,傳感器數據,社交網絡活動,文本和圖像等非傳統數據源在很大程度上被忽略。這些數據類型的新用途不斷被發現,但是消耗和存儲它們可能是昂貴和困難的。
數據湖方法包含這些非傳統的數據類型。在數據湖中,我們保留所有數據而不管源和結構。我們保持它的原始形式,只有在我們準備好使用它時,我們才會改變它。這種方法被稱為“讀取模式”與數據倉庫中使用的“寫入模式”方法。
3.數據湖支持所有用戶
在大多數組織中,80%或更多的用戶是“運營”的。他們希望獲得他們的報告,查看他們的關鍵績效指標,或者每天在電子表格中對同一組數據進行分組。數據倉庫通常是這些用戶的理想選擇,因為它結構合理,易于使用和理解,并且專門用于回答他們的問題。
接下來的10%左右,對數據做更多的分析。他們使用數據倉庫作為數據源,但往往回溯到源系統,以獲取未包含在倉庫中的數據,有時從組織外部獲取數據。他們最喜歡的工具是電子表格,他們創建新的報告,通常分布在整個組織。數據倉庫是他們的數據源,但是他們經常超出界限
最后,最后幾個百分比的用戶做了深入的分析。他們可能會根據研究創建全新的數據源。他們混合了許多不同類型的數據,并提出了全新的問題來回答。這些用戶可能會使用數據倉庫,但往往會忽略它,因為他們通常被控超越其能力。這些用戶包括數據科學家,他們可能會使用先進的分析工具和功能,如統計分析和預測建模。
數據湖方法同樣支持所有這些用戶。數據科學家可以前往湖泊,利用他們所需要的大量不同的數據集,而其他用戶則可以使用更為結構化的數據視圖來提供數據。
4.數據湖適應變化
關于數據倉庫的主要抱怨之一是需要多長時間來改變它們。在開發過程中花費了相當多的時間來獲得倉庫的結構。一個好的倉庫設計可以適應變化,但是由于數據加載過程的復雜性以及為使分析和報告容易進行而做的工作,這些變化將必然消耗一些開發人員資源并花費一些時間。
許多業務問題都迫不及待地讓數據倉庫團隊調整系統來回答問題。自助服務商業智能的概念引發了日益增長的對更快答案的需求。
另一方面,在數據湖中,由于所有數據都是以原始形式存儲的,并且總是可以被需要的人訪問,所以用戶有權超越倉庫結構以新穎的方式探索數據并回答問題在他們的步伐。
如果一個探索的結果被證明是有用的,并且有一個重復的愿望,那么可以應用一個更正式的模式,并且可以開發自動化和可重用性來幫助將結果擴展到更廣泛的觀眾。如果確定結果不是有用的,則可以丟棄該結果,并且沒有對數據結構進行改變,也沒有消耗開發資源。
5.數據湖提供更快的洞察力
這最后一個區別實際上是其他四個的結果。因為數據湖泊包含了所有的數據和數據類型,因為它使用戶能夠在數據被轉換,清理和結構化之前訪問數據,使得用戶能夠比傳統的數據倉庫方法更快地獲得結果。
但是,這種對數據的早期訪問是有代價的。通常由數據倉庫開發團隊完成的工作可能無法完成分析所需的部分或全部數據源。這讓駕駛座位的用戶可以根據需要探索和使用數據,但上述第一層業務用戶可能不希望這樣做。他們還只是想要他們的報告和關鍵績效指標。
在數據湖中,這些操作報告消費者將利用數據庫中的數據的更加結構化的視圖,類似于以前在數據倉庫中的數據。不同之處在于,這些視圖主要是作為元數據存在于湖泊中的數據之上,而不是物理上需要開發者改變的剛性表格。
我應該選擇哪種方法?
這是一個困難的問題。如果你已經建立了完善的數據倉庫,我當然不主張把所有的工作都放在窗口上,從頭開始。但是,像許多其他數據倉庫一樣,您可能會遇到我所描述的一些問題。如果是這種情況,您可以選擇在倉庫的旁邊實施一個數據湖。倉庫可以像以往一樣繼續經營,您可以用新的數據源開始填充您的湖泊。您還可以將其用于您的倉庫數據的歸檔存儲庫,以便實際使其保持可用狀態,從而為用戶提供比以前更多的數據訪問權限。隨著倉庫的老化,您可能會考慮將其移至數據湖,否則您可能會繼續提供混合方法。
如果您剛剛開始構建集中式數據平臺,我強烈建議您考慮兩種方法。
那么技術呢?
我故意沒有提到任何具體的技術。數據湖這個詞已經成為像Hadoop這樣的大數據技術的代名詞,而數據倉庫仍然與關系數據庫平臺保持一致。我這篇文章的目標是突出兩種數據管理方法的差異,而不是強調一個特定的技術。然而事實是,上述技術方法的一致并不是巧合。關系數據庫技術是數據倉庫應用的理想選擇,因為它們在高速查詢結構數據方面表現優異。
另一方面,Hadoop生態系統非常適用于數據湖方法,因為它可以非常容易地適應和擴展非常大的卷,并且可以處理任何數據類型或結構。但是,另外,Hadoop還可以通過將結構化視圖應用于原始數據來支持數據倉庫場景。正是這種靈活性使Hadoop能夠擅長向所有業務用戶層提供數據和洞察力。
未來該何去何從?
兩個陣營的技術不斷發展。
關系數據庫軟件在軟件和硬件方面不斷發展和進步,專門用于使數據倉庫更快,更具可擴展性和更可靠。
Hadoop生態系統正被看到前所未有的采用,而且它是由社區支持的開源項目的集合,這意味著開發和進步的速度比傳統軟件快得多。
Hadoop對開源軟件和商品硬件的依賴使得從成本和功能的角度來看,如果您正在評估一個新的數據平臺,或者正在計劃替換或升級一個遺留系統,那么它就非常有吸引力。