













成都程序員分析,核酸系統一崩再崩,到底誰的鍋?
作為9月2日成都核酸檢測的親歷者, 也跟所有的成都市民一樣,經歷了核酸系統崩潰之后的排隊崩潰和心理崩潰。
昨天,在至少排了一個小時的隊之后,前面還沒有動靜。我跑到志愿者掃碼登記的地方觀察了很久,也看了網上各種各樣的分析,聲音很多。
作為一個程序猿,也來說說我的看法
在發出這個內容之前,我看到 東軟已經發出了聲明 ,概括起來主要是這樣:第一次崩潰是成都政府的系統不行,第二次則是因為網絡不行。總而言之,都不是東軟自己軟件的問題。

對于這個聲明,你問我怎么看?我最后再告訴你。
我先從技術角度對這個問題做一個整體分析。 首先是網上的幾個傳說,但傳說也僅僅只是傳說,這個鍋應該都不歸它們。
首先:是說網絡信號有問題,這個說法很明顯在打臉。 運營商的資源非常豐富。從事實上看,當時排隊的人那么多,大家也都在刷視頻、聊天,都非常流暢,完全無卡頓。呼吁大家讓出信號通道,設置為飛行模式,完全是想多了,運營商表示不答應。

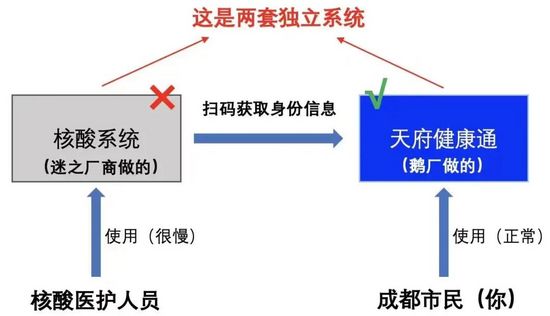
其次:有人認為是天府健康通的問題
這個問題也有人澄清,成都的核酸檢測可以通過刷身份證,或者掃天府健康通的健康碼進行。
如果說真的是健康碼有了故障,那市民們完全可以刷身份證來做核酸。但從市民們的反饋來看,這兩種方法都無法成功。
那很明顯,問題自然出現在了核酸系統這一端。我們也可以看到,這兩套系統也是兩個不同廠家提供的支持,另外根據熱心人士提供信息,天府健康通規劃的容量是完全足夠的。

第三:有人認為是數據庫的問題
這個確實有可能,但不是數據庫本身的問題,而是數據設計的問題。 即便用了MySQL,也不能就說是數據庫本身的問題,比如說,有一個灶臺和一口小鍋,一次不能炒很多,但可以多幾口鍋,分開炒,所以也不能把這個鍋甩給MySQL數據庫,同時這個數據庫的設計一定是核酸系統廠家(迷之廠商)設計的才對。
分析完了幾個傳言,那么核酸系統是哪里出現了問題?
成都市民不外出小區,檢測點全部進入小區,所以一下子要多出好幾倍的業務量,的確對核酸系統提出了非常高的要求。針對這類高并發的業務系統,如何提高系統穩定性,可靠性,確實是一個技術活,這也不是簡單某一點上的問題,而是一個系統工程,在多個環節上都需要進行控制,否則很難達到目標。
我接著從程序員的角度,來列舉幾個可能存在問題的環節。
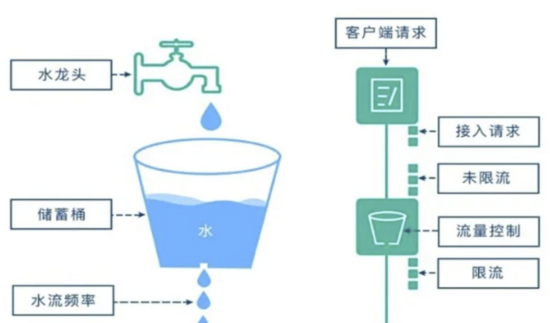
第一:接入網關
這個能力非常重要,也是互聯網架構中不可缺少的環節,主要的能力是鑒權和限流。鑒權的目的是防止被非法訪問,不合規不合法的訪問請求被阻止掉;其次是限流,我們的系統設計一定有一個上限,超過上限怎么辦?與其讓系統崩潰還不如把請求控制在設計的流量范圍內,系統還可以運行。
例如:我們設計的交通是四車道,當車流量達到四車道的負荷時,就進行限制,控制車輛進入,這樣可以保障四車道的車流繼續進行運轉,如果不限流,其結果就是將四車道變成停車場,全部都堵死,誰也跑不了。這就是有些系統設計時考慮了這個環節時的情況是可能較慢,但不至于崩盤,不至于都不能用。
成都核酸系統,就很可能存在這種問題,在2號之前在區縣使用的時候沒有問題,2號進行大面積使用時,系統經常卡死,一直轉圈,操作人員被迫終止程序重新登錄。

高速公路變成停車場
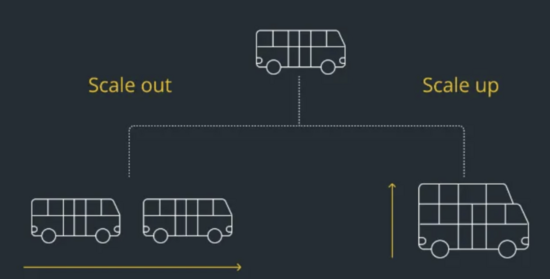
第二:應用服務器擴展能力
擴展分為垂直擴展和水平擴展。 所謂的垂直擴展,大家容易理解,就是將處理能力低的服務器升級到高配置,例如:增加CPU,增加內存等,但是這種往往比較受限,服務器垂直擴展能力是有限的,不能無限制的擴展。
其次是水平擴展,就是說增加數量,就是一臺服務不夠,再增加一臺,10臺不夠,就增加到20臺,這個就和架構設計有關系了,能做到水平擴展才行,不然想通過資源來擴展都沒有辦法使上力。
成都核酸系統根據2號的情況來看,無論是掃描身份證讀取身份基本信息, 還是讀取天府健康通健康碼獲取用戶信息都比較慢,比較懷疑這里處理的服務器能力也不足 ,如果架構上非常靈活支持水平擴展,通過申請政務云資源,應該很快可以提升。
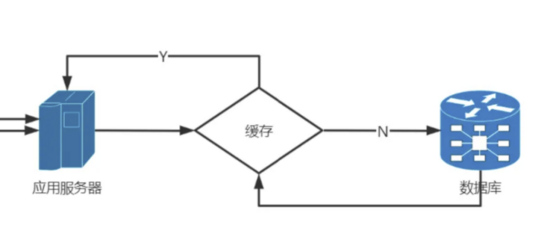
第三:業務緩存
大家都知道數據存放在數據庫中,每次的讀寫都需要產生大量的磁盤IO,這是性能的瓶頸,可以將高頻使用的數據存放在內存中,大大提升讀寫的效率,同時也不用每次都訪問數據庫,既減輕了數據庫的壓力,也大大提升效率。
但是內存的數據不是長久存放,最終還必須要寫到磁盤中,所以在架構設計的時候要充分考慮數據一致性和安全問題,防止數據丟失以及不一致。
根據2號的表現來看,成都的核酸系統在獲取完待檢測人員信息之后, 加入到檢測人員列表時,也需要較長時間,并且還容易在這個環節卡死,所以大概率是在寫入數據時出現異常, 有可能是直接采用寫入數據庫的方式,產生了數據庫擁塞,所以是否使用了緩存技術無法判斷。
第四:數據庫的性能優化
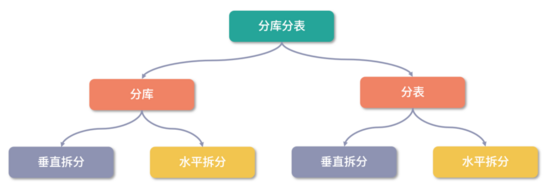
這是最后一個環節,包括:分庫、分表、讀寫分離,也是最容易出現問題的地方。
一是采用分庫,就是給數據庫瘦身,不要把所有的數據都放在一個庫中, 類似不能把高新區的人都安排在一個小區一樣,安排在一個小區,所有人都要通過小區大門進出,容易導致阻塞,就是說的請求擁堵。
二是采用分表,就是讓單個的表中的數據不能太多,也是避免讀寫時產生擁堵, 類似一個小區中的不同樓棟一樣,如果所有的人都住在一棟樓,這些人員的進出就會很擁堵,進門要堵,電梯要堵,所以可以分成不同的樓棟,大家分開進行,減低擁堵可能性。分表的方式很多,可以按照日期來分表,每天一套表,也可以按照區域來分表,不同區域的數據存在不同的表中,結果就是單表的數據量會變小,讀寫擁堵可能性大大減低,這也是提升數據庫性能的很好的手段。
三是采用讀寫分離,就是分成不同的庫, 有些庫主要負責寫入數據,有些數據庫是負責查詢數據,一個主庫負責寫,然后復制幾個庫來支持查詢,這樣可以將數據庫的負荷進行分擔,也可以大大提升性能。
成都的核酸系統也有可能是在寫入數據時出現異常,很大可能是沒有采用分庫、分表的技術,導致在數據寫入時產生大量的并發,寫入不了。
其實,核酸系統的業務并不復雜。
主要流程就是: 登錄人員登錄到對應的檢測點之后,然后就是選擇單檢、混檢1(10混)、混檢2(20混)。假如選擇混檢1,然后掃描試管上條碼,生成一組,再掃描檢測人員,滿10人后,選擇封管,就能完成一組操作。
但就算業務邏輯不復雜,還能出現如此差的表現,那我分析主要問題還是出現在架構設計上,沒有考慮高并發場景。
很大可能性是:
沒有考慮限流機制(應該根據壓測的容量進行設置閾值);
沒有考慮緩存機制,導致都需要直接讀寫數據庫,給數據庫造成極大壓力;
沒有考慮數據庫的分庫分表,導致數據庫異常繁忙,并發量大時,沒有辦法正常寫入。
所以我認為與網絡沒有太大關系,和天府健康通也沒有關系,和政務云資源也沒有關系 (按照需求進行分配,政務云的資源是動態分配,滿足業務需求不會太大挑戰)。
真心建議核酸系統開發公司認真分析,找出問題根源,進行認真優化,不要讓我們再經歷這樣的情況!
(本文系投稿,作者是一名來自成都的程序員)

















