架構瓶頸原則:用注意力probe估計神經網絡組件提供多少句法信息
預訓練語言模型在各種自然語言處理任務上的驚人表現,引起了人們對其分析的興趣。Probing 是進行此類分析所采用的最普遍的方法之一。在典型的 probing 研究中,probing 是一個插在中間層的淺層神經網絡,通常是一個分類器層。其有助于探查不同層捕獲的信息。使用輔助任務對 probing 進行訓練和驗證,以發現是否捕獲了此類輔助信息。
一般來講,研究者首先凍結模型的權重,然后在模型的上下文表示的基礎上訓練probe,從而預測輸入句子的屬性,例如句法解析(其對句子結構進行分析,理清句子中詞匯之間的連接規則)。不幸的是,關于如何設計此類 probe 的最佳實踐仍然存在爭議。
一方面,有研究者傾向于使用簡單的 probe,這樣就可以將 probe 與 NLP 任務區分開來;另一方面,一些人認為需要復雜的 probe 才能從表示中提取相關信息。此外,還有一些人考慮折中的方法,主張將復雜性 - 準確性帕累托曲線上的 probe 考慮在內。
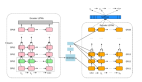
本文中,來自劍橋大學、蘇黎世聯邦理工學院的研究者提出架構瓶頸原則 (ABP,architectural bottleneck principle) 作為構建有用 probe 的指南,并試圖測量神經網絡中的一個組件可以從饋送到它的表示中提取多少信息。為了估計給定組件可以提取多少信息,該研究發現 probe 應該與組件完全相同。根據這一原理,該研究通過注意力 probe 來估計有多少句法信息可用于 transformer。

論文地址:https://arxiv.org/pdf/2211.06420.pdf
舉例來說,該研究假設 transformer 的注意力頭是其使用句法信息的瓶頸,因為這是 transformer 中唯一可以同時訪問多個 token 的組件。根據 ABP,該研究提出注意力 probe,就像注意力頭一樣。該 probe 回答了這樣一個問題:transformer 在計算其注意力權重時可以使用多少句法信息?
結果表明,大多數(盡管不是全部)句法信息都可以通過這種簡單的注意力頭架構提取:英語句子平均包含 31.2 bit 的句法樹結構信息,而注意力 probe 可以提取 28.0 bits 信息。更進一步,在 BERT、ALBERT 和 RoBERTa 語言模型上,一個句子的語法樹大部分是可以被 probe 提取的,這表明這些模型在組成上下文表示時可以訪問句法信息。然而,這些模型是否真的使用了這些信息,仍然是一個懸而未決的問題。
注意力 Probe
目前,有許多方法用來設計有效的 probe,分類原則大致包括:線性原則、最大信息原則、易提取原則,此外還包括本文提出的 ABP 原則。
可以說 ABP 將前三個原則聯系起來。最重要的是,ABP 泛化了線性原則、最大信息原則,此外,ABP 還通過限制 probe 的容量來隱式控信息制提取的難易程度。
該研究重點關注 transformer 注意力機制。此前研究人員曾斷言,在計算注意力權重時,transformer 會使用句法信息。此外,注意力頭是 transformer 中唯一可以同時訪問多個單詞的組件。因此,在注意力頭的背景下探索 ABP 是一個自然的起點。具體而言,根據 ABP,我們可以研究 transformer 的注意力頭可以從輸入表示中提取多少信息。
實驗結果
對于數據,研究者使用了通用依賴(UD)樹庫。他們分析了四種不同類型的語言,包括巴斯克語、英語、泰米爾語和土耳其語。此外,研究者將分析重點放在未標記的依賴樹上,并注意到 UD 使用特定的句法形式,這可能會對結果造成影響。
對于模型,研究者探討了以上四種語言的多語言 BERT 以及僅支持英語的 RoBERTa 和 ALBERT。根據 ABP,他們保持 probe 的隱藏層大小與 probed 架構中的相同。最后,他們還將一個具有與 BERT 相同架構的未訓練 transformer 模型作為基線。
下圖 1 展示了主要結果。首先,研究者的 probe 估計大多數句法信息可以在中間層提取。其次,大量句法信息在饋入注意力頭的表示中進行編碼。雖然他們估計使用英語、泰米爾語和巴斯克語句子編碼的信息接近 31 bits,但使用土耳其句子編碼的信息約為 15 bits。研究者懷疑這是因為土耳其語在語料庫中的句子最短。

研究者還發現,句子中的幾乎所有句法信息都可用于考慮中的基于 transformer 的模型。例如在英語中,他們發現信息量最大的層在 BERT、RoBERTa 和 ALBERT 中的 V 系數分別為 90%、82% 和 89%,具體如下表 1 所示。這意味著這些模型可以訪問一個句子中約 85% 的句法信息。不過未訓練的 BERT 表示并不適合這種情況。

最后,研究者將 BERT 的注意力權重(通過其預訓練的注意力頭計算)直接插入到原文公式 (8) 并分析產生的未標記附件分數。英語相關的 BERT 結果如下圖 2 所示。簡言之,雖然注意力頭可以使用大量的句法信息,但沒有一個實際的頭可以計算與句法樹非常相似的權重。
但是,由于 BERT 有 8 個注意力頭,因此可能以分布式方式使用句法信息,其中每個頭依賴該信息的子集。