三招提升數據不平衡模型的性能(附python代碼)
對于深度學習而言,數據集非常重要,但在實際項目中,或多或少會碰見數據不平衡問題。什么是數據不平衡呢?舉例來說,現在有一個任務是判斷西瓜是否成熟,這是一個二分類問題——西瓜是生的還是熟的,該任務的數據集由兩部分數據組成,成熟西瓜與生西瓜,假設生西瓜的樣本數量遠遠大于成熟西瓜樣本的數量,針對這樣的數據集訓練出來的算法“偏向”于識別新樣本為生西瓜,存心讓你買不到甜的西瓜以解夏天之苦,這就是一個數據不平衡問題。
針對數據不平衡問題有相應的處理辦法,比如對多數樣本進行采樣使得其樣本數量級與少樣本數相近,或者是對少數樣本重復使用等。最近恰好在面試中遇到一個數據不平衡問題,這也是面試中經常會出現的問題之一,現向讀者分享此次解決問題的心得。
數據集
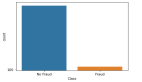
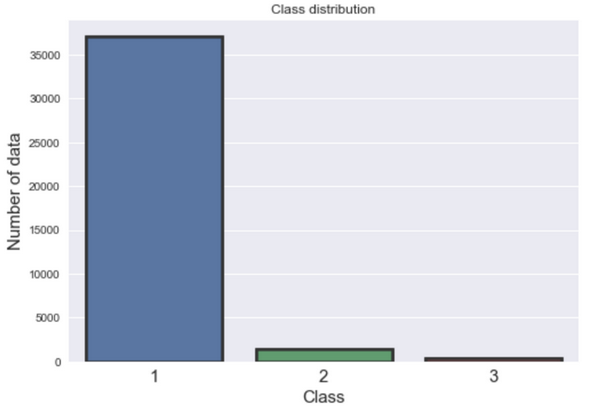
訓練數據中有三個標簽,分別標記為[1、2、3],這意味著該問題是一個多分類問題。訓練數據集有17個特征以及38829個獨立數據點。而在測試數據中,有16個沒有標簽的特征和16641個數據點。該訓練數據集非常不平衡,大部分數據是1類(95%),而2類和3類分別有3.0%和0.87%的數據,如下圖所示。
算法
經過初步觀察,決定采用隨機森林(RF)算法,因為它優于支持向量機、Xgboost以及LightGBM算法。在這個項目中選擇RF還有幾個原因:
- 機森林對過擬合具有很強的魯棒性;
- 參數化仍然非常直觀;
- 在這個項目中,有許多成功的用例將隨機森林算法用于高度不平衡的數據集;
- 個人有先前的算法實施經驗;
為了找到***參數,使用scikit-sklearn實現的GridSearchCV對指定的參數值執行網格搜索,更多細節可以在本人的Github上找到。
為了處理數據不平衡問題,使用了以下三種技術:
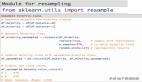
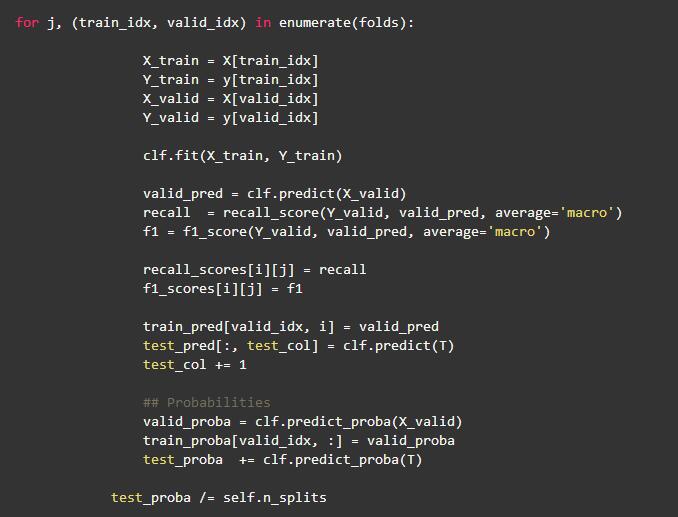
A.使用集成交叉驗證(CV):
在這個項目中,使用交叉驗證來驗證模型的魯棒性。整個數據集被分成五個子集。在每個交叉驗證中,使用其中的四個子集用于訓練,剩余的子集用于驗證模型,此外模型還對測試數據進行了預測。在交叉驗證結束時,會得到五個測試預測概率。***,對所有類別的概率取平均值。模型的訓練表現穩定,每個交叉驗證上具有穩定的召回率和f1分數。這項技術也幫助我在Kaggle比賽中取得了很好的成績(前1%)。以下部分代碼片段顯示了集成交叉驗證的實現:
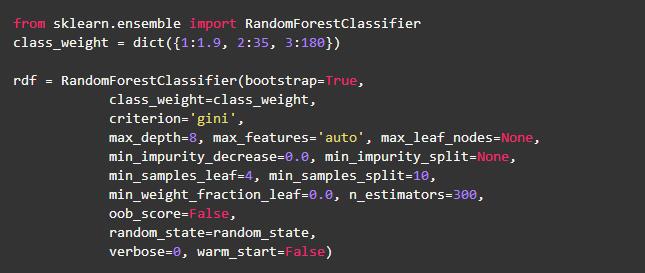
B.設置類別權重/重要性:
代價敏感學習是使隨機森林更適合從非常不平衡的數據中學習的方法之一。隨機森林有傾向于偏向大多數類別。因此,對少數群體錯誤分類施加昂貴的懲罰可能是有作用的。由于這種技術可以改善模型性能,所以我給少數群體分配了很高的權重(即更高的錯誤分類成本)。然后將類別權重合并到隨機森林算法中。我根據類別1中數據集的數量與其它數據集的數量之間的比率來確定類別權重。例如,類別1和類別3數據集的數目之間的比率約為110,而類別1和類別2的比例約為26。現在我稍微對數量進行修改以改善模型的性能,以下代碼片段顯示了不同類權重的實現:
C.過大預測標簽而不是過小預測(Over-Predict a Label than Under-Predict):
這項技術是可選的,通過實踐發現,這種方法對提高少數類別的表現非常有效。簡而言之,如果將模型錯誤分類為類別3,則該技術能***限度地懲罰該模型,對于類別2和類別1懲罰力度稍差一些。 為了實施該方法,我改變了每個類別的概率閾值,將類別3、類別2和類別1的概率設置為遞增順序(即,P3= 0.25,P2= 0.35,P1= 0.50),以便模型被迫過度預測類別。該算法的詳細實現可以在Github上找到。
最終結果
以下結果表明,上述三種技術如何幫助改善模型性能:
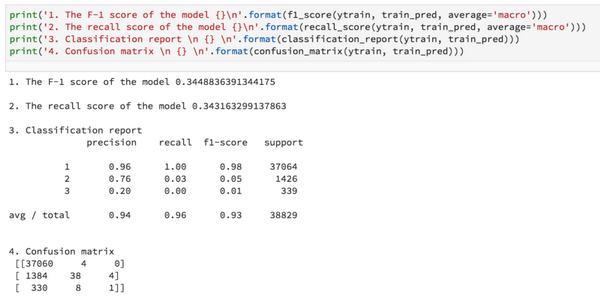
1.使用集成交叉驗證的結果:
2.使用集成交叉驗證+類別權重的結果:
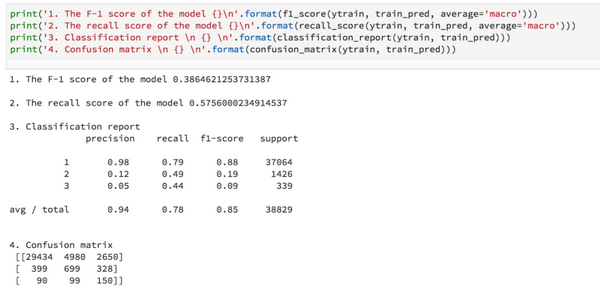
3.使用集成交叉驗證+類別權重+過大預測標簽的結果:
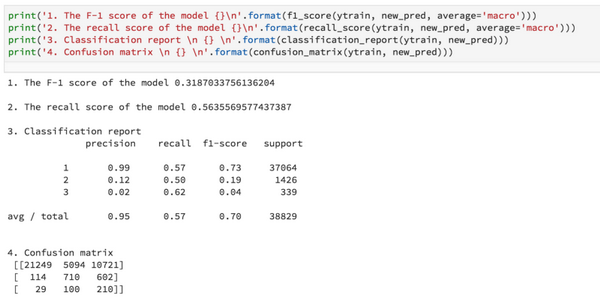
結論
由于在實施過大預測技術方面的經驗很少,因此最初的時候處理起來非常棘手。但是,研究該問題有助于提升我解決問題的能力。對于每個任務而言,起初可能確實是陌生的,這個時候不要害怕,一次次嘗試就好。由于時間的限制(48小時),無法將精力分散于模型的微調以及特征工程,存在改進的地方還有很多,比如刪除不必要的功能并添加一些額外功能。此外,也嘗試過LightGBM和XgBoost算法,但在實踐過程中發現,隨機森林的效果優于這兩個算法。在后面的研究中,可以進一步嘗試一些其他算法,比如神經網絡、稀疏編碼等。