首個二值量化評測基準來了,北航/NTU/ETH聯合提出,論文登ICML 2023
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
二值量化可以有效節約AI模型消耗的資源。
具體而言,它可以把32位浮點數值壓縮到1位,大大降低了存儲和運算成本。
然而,此前對二值量化模型質量的評測一直停留在理論層面,難以對算法在準確性和效率方面的表現進行全面評估。
為此,來自北京航空航天大學、南洋理工大學、蘇黎世聯邦理工大學的研究者,全新推出了首個二值量化評測基準BiBench。

相關論文已被ICML 2023接收。
近日,機器學習頂會 ICML 2023接收論文結果已經正式公布。在 6538篇有效投稿中,最終有1827篇論文被接收,錄取率約為 27.9%。
論文地址:https://arxiv.org/abs/2301.11233
項目地址:https://github.com/htqin/BiBench
背景及概述
隨著深度學習的興起,較大模型的高資源需求與部署資源限制之間的矛盾持續加劇,模型壓縮技術被廣泛研究以解決這一問題。
神經網絡二值化作為將模型參數位寬減少到1位的壓縮方法,被視為最極致的量化技術,能夠極大地降低模型存儲開銷,并通過高效的位運算加速模型推理。
然而,現有的神經網絡二值化算法仍然遠非實用,局限主要存在于兩方面:
1) 模型精度評估范圍有限:目前的大部分工作主要都在CIFAR-10以及ImageNet這類2D圖像分類任務上展開的,同時數據噪聲在二值化算法的評估中也時常被忽略;
2) 效率分析仍停留在理論層面:由于缺乏二值神經網絡部署庫,大部分工作對于二值化算法的壓縮以及加速效果主要停留在理論分析層面。
精度和效率相關對比標準的缺失使得新二值化算法的貢獻逐漸模糊,架構通用的二值算子改進很難在對比中脫穎而出,而這本應是模型量化類技術的主要優勢。

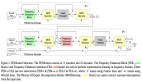
△ 圖 1: BiBench評估軌道與結果
為了解決以上的這些問題,本文提出了BiBench (Binarization Benchmark),這是一個神經網絡二值化算法評測基準,旨在全面評估二值化算法在準確性和效率方面的表現。
BiBench評估了8個基于算子級別并具有廣泛影響力的代表性二值化算法,并在9個深度學習數據集、13個神經架構、2個部署庫、14個硬件芯片以及各種超參數設置下對算法進行了基準測試。
BiBench消耗了約4個GPU年的計算時間來完成實際測試,全面地評估了神經網絡二值化算法,并針對基準的測試結果進行了深入的分析,為設計實用的二值化算法提供了有效建議。
評估軌道及指標
如圖1所示,BiBench的評估主要包含了面向精度的評測以及面向效率的評測這兩個方面,共計六個評測軌道,每個軌道都有相應的評測指標,有效地解決了在生產和部署二值化網絡中面臨的實際挑戰。
面向精度的二值化算法評估
在面向精度的二值化算法評估中,主要包括了“學習任務”,“網絡架構”和“擾動魯棒性”這三個評測軌道。

在“學習任務”這一軌道上,本文詳盡地評測了二值化算法在四個模態共計九個深度學習數據集上的性能表現。
在2D視覺模態上,本文評估了在CIFAR-10和ImageNet數據集上的圖像分類任務,在PASCAL VOC以及COCO數據集上的目標檢測任務。
在3D視覺模態上評估了在ModelNet40數據集上的3D點云分類任務以及在ShapeNet數據集上的3D點云分割任務。
在文本模態評估了在GLUE 基準上的自然語言理解任務。在語音模態評估了在Speech Commands KWS dataset上的語音識別任務。
為了定量地評估不同二值化算法在這個軌道上的性能表現,本文將對應的全精度神經網絡的準確率作為了基線,并計算了所有任務上所有架構的平均相對準確率。
所有任務的相對準確率的二次均值作為該軌道的整體指標,計算公式如下:

其中和分別代表了二值化模型和全精度模型在第i個任務上的準確率。
網絡架構
在“網絡架構”這一軌道上,本文評估了多種神經網絡架構,包括主流的基于卷積神經網絡(CNN)的架構,基于Transformer的架構以及基于多層感知機(MLP)的架構。
具體來說,本文將標準的ResNet-18/20/34以及VGG作為了基于卷積神經網絡的評估架構,并將Faster-RCNN以及SSD300框架作為了目標檢測任務中的檢測器。
對于基于Transformer的架構使用了bi-attention機制二值化了BERT-Tiny4/Tiny6/Base模型以便于收斂。
同時也評估了多種基于多層感知機(MLP)的架構,包括了PointNetvanilla, 帶有EMA聚合器的PointNet, FSMN以及Deep-FSMN.
和“學習任務”軌道類似,在“網絡架構”軌道上,本文也使用了相似的整體指標,其計算公式如下:

擾動魯棒性
在部署時,二值化的擾動魯棒性對于應對某些場景(如感知設備損壞)至關重要,這在現實世界中邊緣設備的應用中是一個常見問題。
因此,本文同時也評估了二值化算法在CIFAR10-C 基準上的表現,用于評估二值化模型在2D視覺數據損壞情況下的魯棒性,其整體指標計算公式如下:

在這里

代表了擾動泛化差距,其中

和

分別表示在第i個擾動任務和相應的正常任務下,所有架構的準確性結果。

面向效率的二值化算法評估
在面向效率的二值化算法評估中,主要包括了“訓練開銷”,“理論復雜度”和“硬件推理”三個評測軌道。
其中“訓練開銷”軌道主要評估二值化算法的生產效率,而其余兩個軌道評估了二值化算法的部署效率。

訓練開銷
在“訓練開銷”軌道上,本文主要考慮了二值化算法所占用的訓練資源和對超參數的敏感性,這些因素影響單次訓練的消耗和整體調優過程。
為了評估調整二值化算法以達到最佳性能的難易程度,本文使用不同的超參數設置訓練二值化網絡,包括不同的學習率、學習率調度器、優化器甚至隨機種子,將二值化網絡和全精度網絡的訓練輪次對齊,并比較了它們的消耗和時間。
定量的整體指標的計算公式如下:

其中

表示單次訓練實例所花費的時間,

是使用不同超參數配置獲得的準確率。
理論復雜度
在“理論復雜度”這一軌道上,本文主要計算模型二值化前后模型的壓縮比合加速比,理論復雜度的總體指標的計算公式如下:
其中

和

分別代表了二值化算法的壓縮比和加速比,二值化參數由于只占據1個bit,相較于32位浮點數只占據1/32的存儲空間;
而二值化模型在推理過程中,僅包含1位權重乘以1位激活值的開銷,在具有64位指令大小的CPU上需要大約1/64的FLOPs(floating point operations per second),因此二值化算法的壓縮比和加速比的計算方式如下:

其中

和

分別是原始模型和二值化模型中保留的全精度參數的數量,

和

代表了模型的計算力。
硬件推理
由于二值化算法在硬件部署庫上尚未得到廣泛支持,目前僅有兩個常用推理庫 - Larq Compute Engine 和京東的 daBNN 提供了完整的流程以將二值化模型實際部署到 ARM 硬件上。
因此,本文主要依據這兩個推理庫,評估了二值化模型在邊緣場景下主流硬件上的 ARM CPU 推理性能,如華為麒麟,高通驍龍,蘋果 M1,聯發科天璣和樹莓派。
對于給定的二值化算法,使用不同推理庫和硬件下的存儲和推理時間節省作為評估指標,總體評估指標計算方式如下:

其中

是模型的推理時間,

是模型在不同設備上的存儲開銷。
評估及分析
BiBench從二值算法的準確性和效率兩方面,全面地評估了所選二值算法的性能表現。
二值算法的準確性分析
本文分別針對不同任務、針對不同模型架構、針對擾動魯棒性三個軌道,評估了各二值算法的準確率。上表匯報了基于相關性度量的模型準確率表現。
從學習任務的角度
模型準確率仍然是目前二值算法研究中最具挑戰性的難題。
BiBench將訓練流程和模型架構完全統一,以此來觀察不同二值算法的表現。
發現在大多數任務中,二值算法的準確率表現仍然是有限的。在大規模視覺數據集ImageNet和COCO上,二值模型的準確率往往是對應的全精度模型的不到80%。
而且,準確率的邊際效應在二值算法中已經出現,比如,在ImageNet數據集上,最先進的ReCU算法比最樸素的BNN算法準確率僅僅高了3%。
二值算法在不同數據模態下的表現差異很大。
二值算法在文本理解任務GLUE數據集上的精度降低非常嚴重,然而在點云分類的ModelNet40數據集上卻有與全精度模型相媲美的準確率表現。
這表明,二值化的研究中得到的經驗和啟迪,很難在不同模態的任務下直接移用。
總體來說,ReCU和ReActNet在各種不同的任務下都取得了較高的準確率表現,ReCU在4個獨立的任務中獲得了準確率的第一,而ReActNet獲得了總體準確率的第一。
兩個算法都在前向過程中采用了重參數化,在反向過程中采用了梯度近似的方法。
從網絡架構的角度
二值算法在CNN和MLP架構上的表現相比在Transformer架構上具有明顯的優勢。
由于二值算法在CNN架構相關的模型上已有廣泛的研究,一些先進的二值算法通常能達到相比于全精度模型78%~86%的準確性。
而MLP架構上的二值算法甚至能達到接近全精度模型的準確率表現(例如Bi-Real Net達到87.83%)。
與之形成鮮明對比的是,在二值化Transformer架構時卻受到了嚴重的精度降低,甚至沒有一個算法的整體相對準確率能夠超過70%。
這個好結果表明,相比于CNN和MLP架構的模型,Transformer架構由于其特殊的注意力機制,對二值化方法帶來了更嚴峻的挑戰,現有的對該機制的二值化方法還沒有徹底解決這個問題。
在“網絡架構”軌道上獲得冠軍的是FDA算法,它在CNN和Transformer架構上都獲得了最好的準確率成績。
關于任務和模型架構的這兩個軌道的結果表明,像FDA和ReActNet的二值算法具有一定的穩定性,這兩個算法都使用了逐通道的縮放參數和自定義的梯度近似方案。
從擾動魯棒性的角度
二值模型能夠達到與全精度模型同等的魯棒性。
令人驚訝的是,雖然二值模型表現出了相對有限的表征能力和比較明顯的準確率下降,但是在干擾數據集上,他們卻展現出了與全精度模型同等的魯棒性。
在CiFAR10-C數據集上,二值算法在常規2D損毀圖像上的表現接近于全精度模型,而且ReCU和XNOR-Net算法的表現甚至超過了全精度模型。
這個事實表明,二值模型幾乎不需要額外的訓練或監督,就能達到與全精度模型同等的魯棒性。
同時,各種二值化算法具有相似的魯棒性表現,因此可以將魯棒性視為二值模型的一般屬性,而不僅僅屬于特定算法。
二值算法的效率分析
BiBench分別從“訓練開銷”、“ 理論復雜度”、“ 硬件推理”三個軌道,全面評估了不同算法的效率。
訓練開銷

△ 圖 2: 不同算法的參數敏感性
本文以CIFAR10數據集上的ResNet18為代表,全面地評估了二值算法的訓練開銷。上圖和上表展示了不同二值算法的參數敏感性以及訓練時間。
二值化并不意味著敏感:現有的技術能夠穩定地訓練二值算法。
一個現有的共同的直覺是,由于二值算法高度的離散性帶來的表征能力有限和梯度近似的誤差,二值模型的訓練可能比全精度模型的訓練更加敏感。
但是,本文發現現有二值算法對于超參數的敏感性是兩極分化的,部分二值算法比全精度模型對于超參數具有更好的穩定性,而另一些二值算法則對超參數具有較大的性能波動。
對此,不同的二值技術有不同的原因。
本文總結出訓練過程穩定的二值算法通常具有以下這些共性:
(1) 基于學習或統計量的逐通道浮點縮放因子;
(2) 降低梯度誤差的梯度近似軟函數。
這些對于超參數穩定的二值算法可能并不能獲得比其他算法更好的模型準確率,但是它們能夠在模型生產階段簡化訓練/微調的過程,在單次訓練后獲得更可靠的準確性。
二值算法訓練過程對于超參數的偏好是很明顯的。
從圖2中所示的結果來看,Adam優化器、與全精度相同的初始學習率 (1x) 和余弦退火的學習率策略訓練得到的二值模型的表現能夠穩定地優于其他超參數訓練得到的模型。
受此啟發,本文使用了這組表現最好的超參數作為標準訓練流程的一部分設置。
梯度近似軟函數會增加大量的訓練時間。
對比每個二值算法的訓練開銷,本文發現,使用了自定義梯度近似技術的算法,例如Bi-Real和ReActNet算法,它們的訓練時間有顯著的增加,而 FDA的訓練時間甚至幾乎是全精度模型的5倍。
理論復雜度
不同的二值模型的算法的理論復雜度并沒有明顯的不同。
不同算法間壓縮率差異的主要原因在于每個模型的縮放因子的定義方式不同,例如,BNN 沒有縮放因子。
對于理論加速情況,二值算法間的主要區別來自兩個方面。首先,靜態的縮放因子的壓縮也提高了理論加速比。
其次,對于激活值實時的縮放和均值偏移會帶來額外的理論計算,例如ReActNet,能夠減少0.11×的加速。
但是總的來說,本文的實驗表明,各種二值化算法具有相似的理論推理效率。
硬件推理
相比于其他的軌道,“硬件推理”軌道能夠提供一些二值算法在真實世界部署的啟示。

極其有限的推理庫導致了幾乎固定的二值化部署范式。
在調查了現有開源推理框架之后,本文發現能夠支持二值模型在真實硬件上部署的推理庫非常少。只有Larq和daBNN擁有完整的二值化算法部署流程,它們主要支持在ARM設備上進行部署。
首先驗證這兩個推理庫的部署能力,結果呈現在表4中。兩個推理庫都支持逐通道的浮點縮放因子,并強制將它融合進BN層,此外,二者都不支持動態激活縮放。
它們唯一的區別是,Larq能支持激活值基于固定值的偏移。
由于推理庫的部署限制,能夠實際部署的二值算法是有限的。XNOR++使用的縮放因子是不能部署的,XNOR的激活動態縮放也是不支持的。
除了ReActNet所使用的激活均值偏移會增加少量的計算量,其他能夠部署的二值算法,大多具有幾乎完全相同的推理表現。
也就是說,二值算法必須能夠滿足固定的部署范式才能夠使用現有的推理庫成功部署,并且它們在硬件上具有幾乎相同的表現。

△ 圖3: 二值算法在算力越低的硬件芯片上能夠達到越高的推理加速比
為邊緣而生:芯片的算力越低,二值化模型的加速比越高。
BiBench部署和評估了十幾個芯片上的二值化模型,并比較了每個芯片上二值化算法的平均加速比。
圖3中呈現了一個反直覺的規律:芯片的算力性能越高,二值化模型的加速比越低。
通過進一步觀察,本文發現這主要是因為多線程計算。性能更好的芯片在運行浮點計算時使用了更多線程的并行,能夠帶來顯著的浮點運算加速。
因此,相比之下,二值化模型的加速并不明顯。
這意味著二值化技術真正發揮作用的場景,是在算力性能和成本較低的邊緣芯片上,而二值化所帶來的極限壓縮和加速可以促進人工智能模型在此類邊緣芯片上的運行。
關于二值算法設計的一些建議
基于上述的驗證和分析,本文試圖從現有的二值技術中,總結一些準確高效的二值算法的設計范式:
(1) 軟量化近似是二值化的一個必要的技術。它不會影響模型在硬件推理時的高效性,所有在準確率軌道上表現優秀的算法都采用了這個技術,包括Bi-Real、ReActNet和ReCU。
(2) 逐通道縮放因子是考慮可部署性的唯一選擇。在任務和架構兩軌道上的準確率結果說明了浮點縮放因子的優勢,而現有推理庫在硬件上的實際部署能力又限制了縮放因子必須是逐通道的形式。
(3) 對激活值的均值偏移是一個有助于準確率提升的可選項。本文結果表明這項技術有助于ReActNet準確率的提升,并且幾乎沒有額外的計算開銷。
需要強調的是,雖然BiBench所包含的六個軌道能夠幫助找到一些二值網絡設計的基本原則,但是沒有哪個算法能在所有場景下都具有優勢。
未來的二值化算法研究應側重于打破生產與部署之間的互相限制。二值算法應遵循可部署的原則進行設計,而推理庫應當盡可能地支持先進的更高精度的二值算法。
總結
本文提出了一個全面的多功能的二值算法基準框架BiBench,深入地研究了二值算法的最基本的問題。
BiBench覆蓋了8種模型二值化算法、13種網絡架構、9個深度學習數據集,14種真實世界的硬件,以及多種超參數設置。
此外,BiBench針對一些關鍵的特性專門設計了評測的軌道,例如在不同條件下的算法準確性以及在真實硬件上部署時的高效性。
更重要的是,通過整理、總結和分析實驗結果,BiBench希望能夠建立一些經驗性的設計范式,其中包含設計準確有效的二值化方法的幾個關鍵考慮因素。
研究人員希望,BiBench能夠通過系統性的研究反映模型二值領域的現實需求,促進算法的公平比較,并作為在更廣泛和更實際的背景下應用模型二值化的基礎。