













VLDB 2023獎項公布,清華、第四范式、NUS聯合論文獲最佳工業界論文獎
數據庫領域的國際頂級學術會議 VLDB 2023 在加拿大溫哥華落幕。VLDB 會議全稱 International Conference on Very Large Data Bases,是數據庫領域歷史悠久的三大頂級會議 (SIGMOD、VLDB、ICDE) 之一,每屆會議集中展示了當前數據庫研究的前沿方向、工業界的最新技術和各國的研發水平,吸引了全球頂級研究機構投稿。

該會議對系統創新性、完整性、實驗設計等方面都要求極高,VLDB 的論文接受率總體較低(約 18%),必須是貢獻很大的論文才有機會被錄用。今年的競爭更為激烈。據官方顯示,今年 VLDB 共有 9 篇論文脫穎而出,獲得了最佳論文獎項,其中不乏斯坦福、CMU、微軟研究院、VMware 研究院、Meta 等全球知名高校、研究機構、科技巨頭的身影。
其中由第四范式、清華大學以及新加坡國立大學聯合完成的 "FEBench: A Benchmark for Real-Time Relational Data Feature Extraction" 論文,獲得了最佳工業界論文 Runner Up 獎項。

該論文由第四范式、清華大學以及新加坡國立大學合作完成,提出了一個基于工業界真實場景積累的實時特征計算測試基準,用于評測基于機器學習的實時決策系統。

- 論文地址:https://github.com/decis-bench/febench/blob/main/report/febench.pdf
- 項目地址:https://github.com/decis-bench/febench
項目背景
基于人工智能的決策系統目前已經在很多行業場景實現了廣泛的應用,其中大量的場景涉及到基于實時數據的計算,比如金融行業的反欺詐、零售行業的實時線上推薦等場景。機器學習驅動的實時決策系統一般會包含兩個最主要的計算環節,即特征和模型。其中,由于業務邏輯的多樣化和線上的低延遲、高并發的需求,特征計算往往成為整個決策系統的瓶頸,需要大量的工程化實踐來構建一個生產環境可用、穩定高效的實時特征計算平臺。如下圖 1 列舉了一個常見的反欺詐應用的實時特征計算場景。基于原始的刷卡流水記錄表格進行特征計算,生成新的特征(包含如最近 10 秒內最大 / 最小 / 平均刷卡金額等特征),進一步輸入下游模型,進行實時推理。
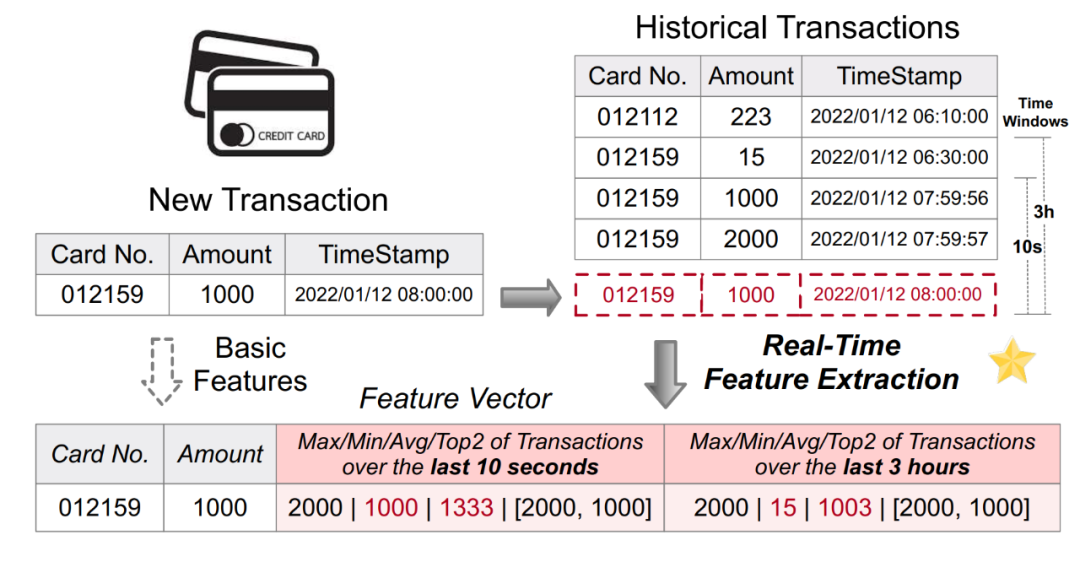
圖 1. 反欺詐應用中的實時特征計算
一般來說,實時特征計算平臺需要滿足如下兩個基本要求:
- 線上線下一致性:由于機器學習應用一般會分為線上和線上兩個流程,即基于歷史數據的訓練和基于實時數據的推理。因此確保線上線下的特征計算邏輯一致性,對于保證線上線下最終業務效果一致至關重要。
- 線上服務的高效性:線上服務針對實時數據和計算,滿足低延遲、高并發、高可用等需求。
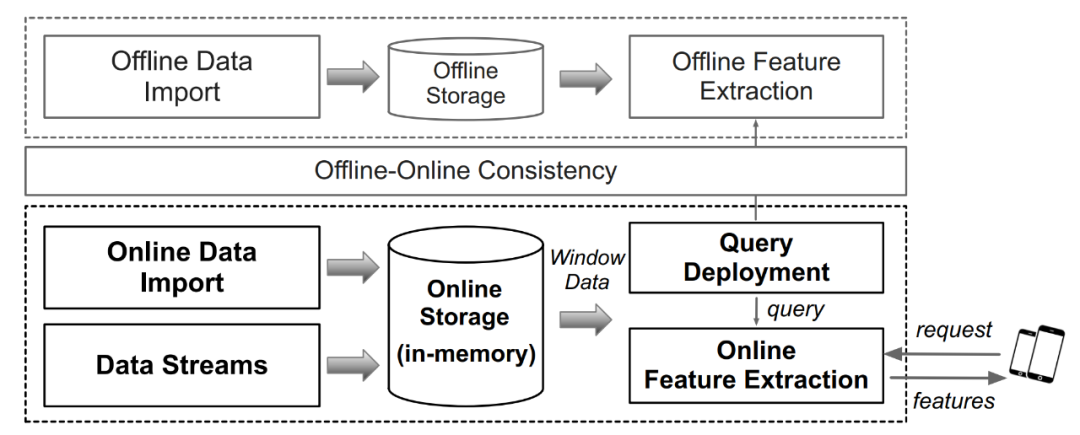
圖 2. 實時特征計算平臺架構及工作流程
如上圖 2 列舉了一個常見的實時特征計算平臺的架構。簡單來說主要包含了離線計算引擎和在線計算引擎,其中的關鍵點是保證離線和在線計算引擎的計算邏輯一致性。目前市面上有許多特征平臺可以滿足上述要求,構成一個完整的實時特征計算平臺,包括通用系統如 Flink,或者專用系統如 OpenMLDB、Tecton、Feast 等。但是,目前工業界缺少一個面向實時特征的專用基準來對這類系統的性能進行嚴謹科學的評估。針對該需求,本篇論文作者構建了 FEBench,一個實時特征計算基準測試,用于評估特征計算平臺的性能,分析系統的整體延遲、長尾延遲和并發性能等。
技術原理
FEBench 基準的構建主要包含三部分工作:數據集搜集、查詢生成、以及模板選擇。
數據集搜集
研究團隊總共收集了 118 個可以用于實時特征計算場景的數據集,這些數據集來自 Kaggle,Tianchi,UCI ML,KiltHub 等公開數據網站以及第四范式內部可公開數據,覆蓋了工業界的典型使用場景,如金融、零售、醫療、制造、交通等行業場景。研究小組進一步按照表格數量及數據集大小將收集到的數據集進行了歸類,如下圖 3 所示。
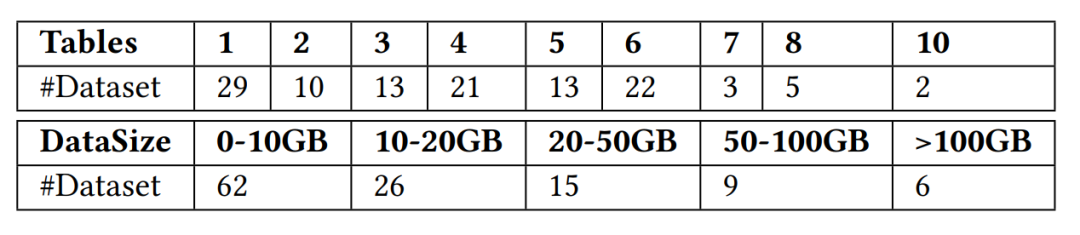
圖 3. FEBench 中數據集的表格數量及數據集大小
查詢生成
由于數據集數量較大,為每一個數據集人工生成特征抽取的計算邏輯工作量十分巨大,因此研究人員利用了如 AutoCross(參考論文:AutoCross: Automatic Feature Crossing for Tabular Data in Real-World Applications) 等自動機器學習技術,來為收集到的數據集自動化生成查詢。FEBench 的特征選擇和查詢生成過程包括以下四個步驟(如下圖 4 所示):
- 通過識別數據集中的主表(存儲流式數據)和輔助表(例如靜態 / 可追加 / 快照表),進行初始化。隨后,分析主表和輔助表中具有相似名稱或鍵關系的列,并枚舉列之間的一對一 / 一對多關系,這些關系對應不同的特征操作模式。
- 將列關系映射到特征操作符。
- 在提取所有候選特征后,利用 Beam 搜索算法迭代生成有效的特征集。
- 選擇的特征被轉換為語義上等效的 SQL 查詢。
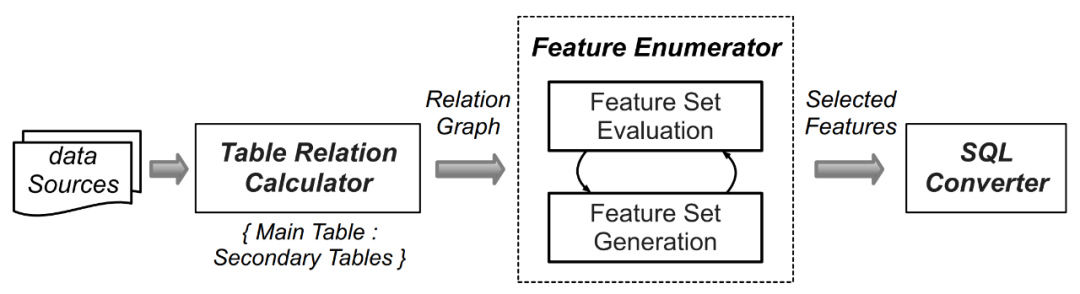
圖 4. FEBench 中查詢的生成流程
模板選擇
在為每一個數據集生成查詢以后,研究人員進一步使用聚類算法選取代表性的查詢作為查詢模板,來減少對相似任務的冗余測試。對于收集到的 118 個數據集和特征查詢,采用 DBSCAN 對這些查詢進行聚類,步驟如下:
- 將每個查詢的特征劃分為五個部分:輸出列數、查詢操作符總數、復雜運算符的出現頻率、嵌套子查詢層數以及時間窗口中最大元組的數量。由于特征工程查詢通常涉及時間窗口,查詢復雜性不受批處理數據規模的影響,因此數據集大小沒有作為聚類特征之一。
- 使用邏輯回歸模型評估查詢特征與查詢執行特性的關系,特征作為模型輸入,特征查詢的執行時間為模型輸出。使用每個特征的回歸權重作為其聚類權重,以考慮不同特征對聚類結果的重要性。
- 基于加權查詢特征,使用 DBSCAN 算法將特征查詢劃分為多個聚類。
如下圖 5 可視化了 118 個數據集在各個考量指標下的分布。其中圖(a)展示了統計性質的指標,包括輸出列數,查詢操作符總數和嵌套子查詢層數;圖(b)展示了與查詢執行時間相關性最高的指標,包括聚合操作個數,嵌套子查詢層數和時間窗口個數。
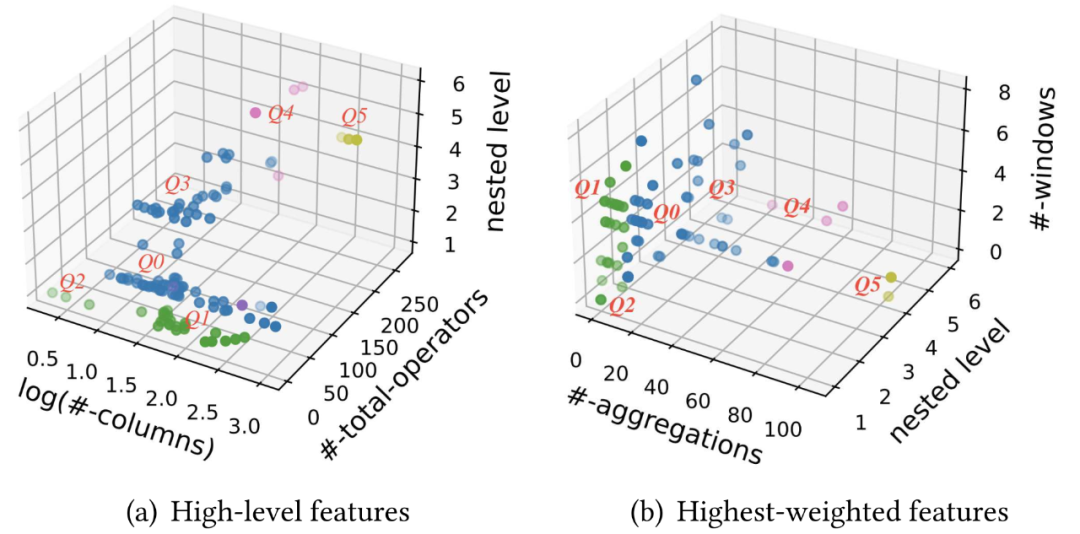
圖 5. 118 個特征查詢通過聚類分析得到 6 個集群,生成查詢模板(Q0-5)
最終,根據聚類結果,將 118 個特征查詢分為 6 個集群。對于每個集群,選擇質心附近的查詢作為候選模板。此外,考慮到不同應用場景下的人工智能應用可能有不同的特征工程需求,圍繞每個集群的質心,嘗試選擇來自不同場景的查詢,以更好地覆蓋不同的特征工程場景。最終,從 118 個特征查詢中選擇了 6 個查詢模板,適用于不同場景,包括交通、醫療保健、能源、銷售,以及金融交易。這 6 個查詢模板最終構成了 FEBench 最為核心的數據集和查詢,用于進行實時特征計算平臺的性能測試。
基準評測( OpenMLDB vs Flink)
研究人員在兩個典型的工業界系統 Flink(通用的批處理和流處理一致性計算平臺)及 OpenMLDB(專用實時特征計算平臺)上部署了 FEBench 進行測試,并分析了兩個系統各自的優缺點以及背后的原因。實驗展示了 Flink 和 OpenMLDB 由于架構設計不同帶來的性能差異,并由此說明了 FEBench 分析目標系統的能力。其評測的主要結論如下。
- Flink 比 OpenMLDB 在延遲上慢兩個數量級(圖 6)。研究人員分析,其造成差距的主要原因在于兩者系統架構的不同實現方式,其中 OpenMLDB 作為實時特征計算的專用系統,包含了基于內存的雙層跳表等專門針對時序數據優化的數據結構,最終相比較于 Flink,在特征計算場景上有明顯的性能優勢。當然 Flink 作為通用系統,在可適用場景上比 OpenMLDB 更為廣泛。
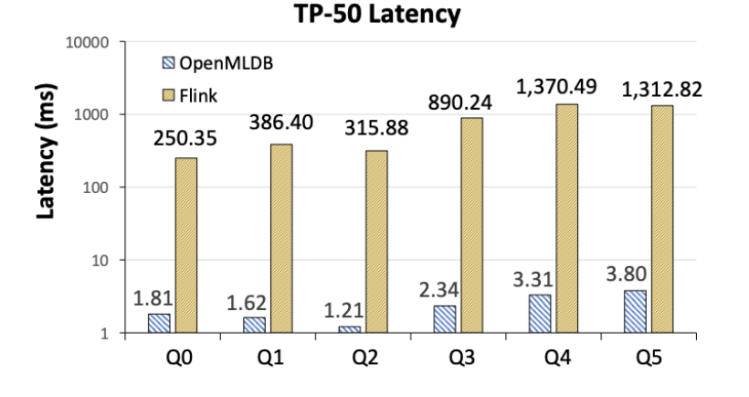
圖 6. OpenMLDB 與 Flink 的 TP-50 延遲對比
- OpenMLDB 表現出明顯的長尾延遲問題,而 Flink 的尾延遲更穩定(圖 7)。注意,以下數字顯示均為歸一化到 OpenMLDB 和 Flink 各自的 TP-50 下的延遲性能,并不代表絕對性能的比較。
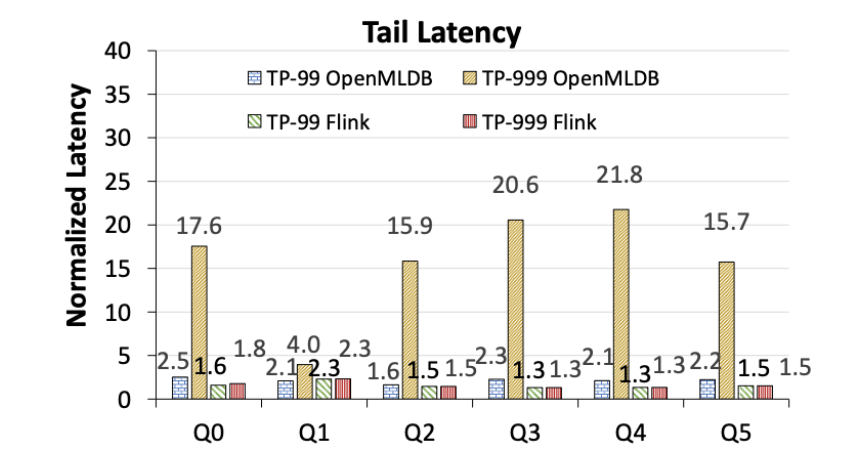
圖 7. OpenMLDB 與 Flink 的尾延遲對比(歸一化到各自的 TP-50 延遲)
研究人員對上述的性能結果進行了進一步的深入分析:
- 微架構指標分析:根據執行時間進行拆解分析,包括指令完成、錯誤分支預測、后端依賴和前端依賴等指標。不同查詢模板的性能瓶頸在微觀結構層面上有所不同。如下圖 8 所示,Q0-Q2 的性能瓶頸主要在前端依賴,占整個運行時間的 45% 以上,這種情況下執行的操作相對簡單,大部分時間花在處理用戶請求和特征提取指令的切換上面。而對于 Q3-Q5,后端依賴(緩存失效等)和指令運行(更多復雜指令)成為更主要的因素。OpenMLDB 的針對性優化使得它在性能上更加出色。
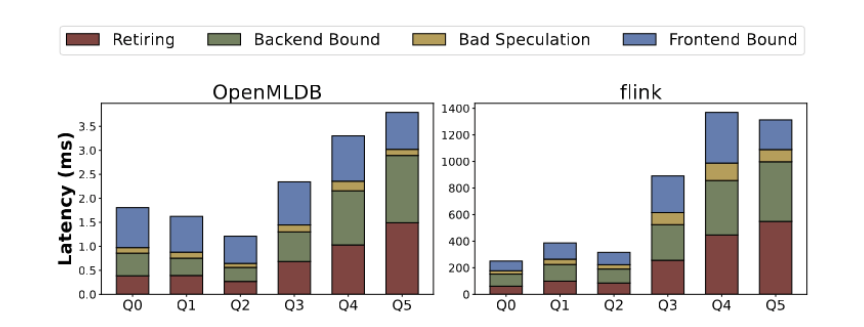
圖 8. OpenMLDB 與 Flink 的微架構指標分析
- 執行計劃分析:以 Q0 為例,下圖 9 比較了 Flink 和 OpenMLDB 的執行計劃差異。Flink 中的計算運算符花費最多的時間,而 OpenMLDB 通過優化窗口處理和使用自定義聚合函數等優化技術減少了執行延遲。
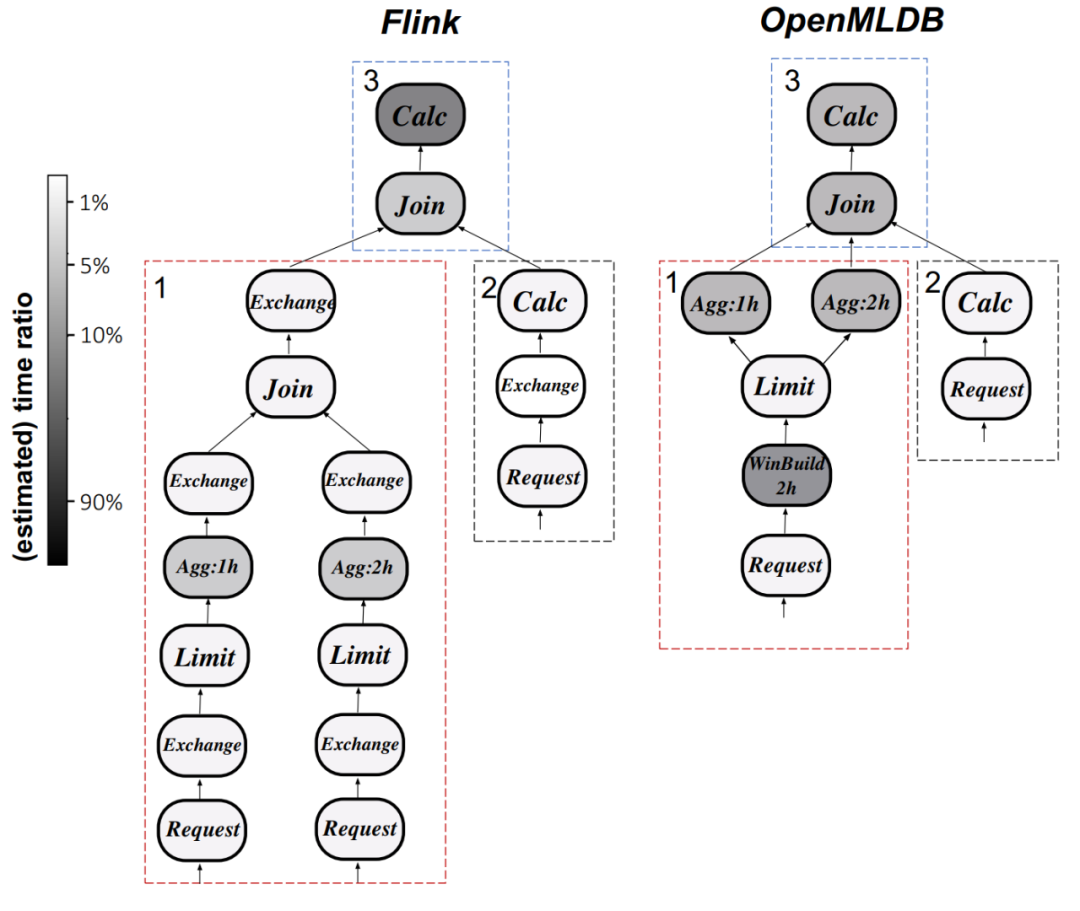
圖 9. OpenMLDB 與 Flink 的執行計劃(Q0)對比
如果用戶期望復現以上實驗結果,或者在本地系統上進行基準測試(論文作者也鼓勵將測試結果在社區提交共享),可以訪問 FEBench 的項目主頁,獲得更多信息。
- FEBench 項目:https://github.com/decis-bench/febench
- Flink 項目:https://github.com/apache/flink
- OpenMLDB 項目:https://github.com/4paradigm/OpenMLDB



























