分割一切深度圖!港科技、南洋理工等開源「SAD」:根據幾何信息分割圖像
本月初,Meta推出的一款可以「分割一切」的模型Segment Anything Model (SAM) 已經引起了廣泛的關注。今天,我們向大家介紹一款名為「Segment Any RGBD(SAD)」的機器學習模型。與以往所有使用SAM的工具的不同之處在于,SAD讀入的圖片可以是經過渲染之后的深度圖,讓SAM直接根據幾何信息來分割圖像。該項目是由Visual Intelligence Lab@HKUST, HUST, MMLab@NTU, Smiles Lab@XJTU和NUS的同學完成的。如果大家覺得這個項目有意思的話,請大家多多star~
演示程序鏈接:https://huggingface.co/spaces/jcenaa/Semantic_Segment_AnyRGBD
代碼鏈接:https://github.com/Jun-CEN/SegmentAnyRGBD

簡介
人類可以從深度圖的可視化中自然地識別物體,所以研究人員首先通過顏色映射函數將深度圖([H,W])映射到RGB空間([H,W,3]),然后將渲染的深度圖像輸入 SAM。
與RGB圖像相比,渲染后的深度圖像忽略了紋理信息,而側重于幾何信息。
以往基于 SAM 的項目里SAM 的輸入圖像都是 RGB 圖像, 該團隊是第一個使用 SAM 直接利用渲染后的深度圖提取幾何信息的。
下圖顯示了具有不同顏色圖函數的深度圖具有不同的 SAM 結果。

模型流程圖如下圖所示,作者提供了兩種選擇,包括將 RGB 圖像或渲染的深度圖像輸入到 SAM進行分割,在每種模式下,用戶都可以獲得Semantic Mask(一種顏色代表一個類別)和帶有類別的 SAM Mask。

以輸入為深度圖為例子進行說明。首先通過顏色映射函數將深度圖([H,W])映射到RGB空間([H,W,3]),然后將渲染后的深度圖送入SAM進行分割。
同時使用OVSeg對RGB圖進行zero-shot語義分割,只需要輸入一系列候選類別的名稱即可完成類別識別。然后每一個SAM的mask的類別會根據當前mask里面的點的語義分割結果進行投票,選擇點數最多的類別當成當前mask的類別。
最終輸出可視化有兩種形式,一種是Semantic mask,即一種顏色對應一種類別;另一種是SAM mask with classes,即輸出的mask仍然是SAM的mask,并且每一個mask都有類別。并且可以根據深度圖將2D的結果投影到3D space進行可視化。
對比效果
作者將RGB送入SAM進行分割與將渲染后的深度圖送入SAM進行分割進行了對比。
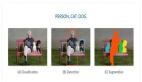
- RGB圖像主要表示紋理信息,而深度圖像包含幾何信息,因此RGB圖像比渲染的深度圖像色彩更豐富。在這種情況下,SAM 為 RGB 輸入提供的掩碼比深度輸入多得多,如下圖所示。

- 渲染的深度圖像減輕了 SAM 的過分割。例如,桌子在RGB圖像上被分割成四個部分,其中一個在語義結果中被分類為椅子(下圖中的黃色圓圈)。相比之下,桌子在深度圖像上被視為一個整體對象并被正確分類。人的頭部的一部分在RGB圖像上被分類為墻壁(下圖中的藍色圓圈),但在深度圖像上卻被很好地分類。
- 距離很近的兩個物體在深度圖上可能被分割為一個物體,比如紅圈中的椅子。在這種情況下,RGB 圖像中的紋理信息對于找出對象比較關鍵。
Demo


作者表示,希望SAD模型能夠帶來更多的啟發和創新,也期待著反饋和建議。讓我們一起探索這個神奇的機器學習世界吧!