別用GPT-4直出文本摘要!MIT、哥大等發(fā)布全新「密度鏈」提示:實(shí)體密度是摘要質(zhì)量的關(guān)鍵
ChatGPT發(fā)布后,文本生成技術(shù)得到飛速發(fā)展,大量NLP任務(wù)都面臨被完全攻克的窘境,尤其是對(duì)于缺乏標(biāo)準(zhǔn)答案的「文本摘要」任務(wù)來(lái)說(shuō)更是如此。
但如何在摘要中包含「合理的信息量」仍然十分困難:一個(gè)好的摘要應(yīng)該是詳細(xì)的,以實(shí)體為中心的,而非實(shí)體密集且難以理解。
為了更好地理解信息量和可理解性之間的權(quán)衡,麻省理工學(xué)院、哥倫比亞大學(xué)等機(jī)構(gòu)的研究人員提出了一個(gè)全新的「密度鏈」(Chain of Dense)提示,可以在不增加摘要文本長(zhǎng)度的前提下,對(duì)GPT-4生成的實(shí)體稀疏(entity-sparse)摘要進(jìn)行迭代優(yōu)化,逐步添加缺失的重要實(shí)體。

論文鏈接:https://arxiv.org/pdf/2309.04269.pdf
開(kāi)源數(shù)據(jù):https://huggingface.co/datasets/griffin/chain_of_density
從實(shí)驗(yàn)結(jié)果來(lái)看,用CoD生成的摘要比由普通提示生成的GPT-4摘要更抽象(abstractive),表現(xiàn)出更多的融合性(fusion)以及更少的lead bias
在對(duì)100篇CNN DailyMail文章進(jìn)行人類(lèi)偏好研究后可以發(fā)現(xiàn),人類(lèi)也更傾向于選擇實(shí)體更密集的摘要結(jié)果,與人工編寫(xiě)摘要的實(shí)體密度相近。
研究人員開(kāi)源了500篇帶標(biāo)注的CoD摘要,以及5000篇無(wú)標(biāo)注的摘要數(shù)據(jù)。
迭代改進(jìn)文本摘要
提示(Prompt)
任務(wù)目標(biāo)是使用GPT-4生成一組具有「不同信息密度水平」的摘要,同時(shí)還要控制文本的長(zhǎng)度。
研究人員提出密度鏈(CoD,Chain of Density)提示來(lái)生成一個(gè)初始摘要,并逐漸使實(shí)體密度越來(lái)越大。
具體來(lái)說(shuō),在固定的迭代輪數(shù)下,識(shí)別出源文本中一組獨(dú)特的、顯著的實(shí)體,并融合到先前的摘要中而不增加文本長(zhǎng)度。

首次生成的摘要是實(shí)體稀疏的,只關(guān)注1-3個(gè)初始實(shí)體;為了保持相同的文本長(zhǎng)度,同時(shí)增加涵蓋的實(shí)體數(shù)量,需要明確鼓勵(lì)抽象(abstraction)、融合(fusion)和壓縮(compression),而不是從之前的摘要中刪除有意義的內(nèi)容。
研究人員沒(méi)有規(guī)定實(shí)體的類(lèi)型,而是簡(jiǎn)單地將缺失實(shí)體(Missing Entity)定義為:
相關(guān)(Relevant):與主體故事相關(guān);
具體(Specific):描述性但簡(jiǎn)明扼要(5個(gè)字或以下);
新穎(Novel):沒(méi)有出現(xiàn)在之前的摘要中;
忠實(shí)(Faithful):存在于原文中;
任何地方(Anywhere):可以出現(xiàn)在文章中的任意位置。
在數(shù)據(jù)選擇上,研究人員從CNN/DailyMail摘要測(cè)試集中隨機(jī)抽取100篇文章來(lái)生成CoD摘要。
然后將CoD摘要統(tǒng)計(jì)數(shù)據(jù)與人工編寫(xiě)的條目(bullet-point)風(fēng)格的參考摘要以及GPT-4在常規(guī)提示下生成的摘要進(jìn)行對(duì)比,其中提示詞為「寫(xiě)一篇非常簡(jiǎn)短的文章摘要,不超過(guò)70個(gè)詞」(Write a VERY short summary of the Article. Do not exceed 70 words)。
預(yù)期token長(zhǎng)度設(shè)置為與CoD摘要的token長(zhǎng)度相匹配。
統(tǒng)計(jì)結(jié)果
直接統(tǒng)計(jì)指標(biāo)
使用NLTK計(jì)算token數(shù)量,使用Spacy2測(cè)量獨(dú)特的實(shí)體數(shù)量,并計(jì)算實(shí)體密度比率。
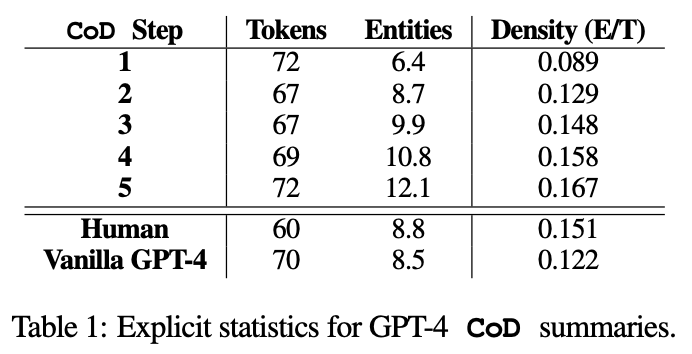
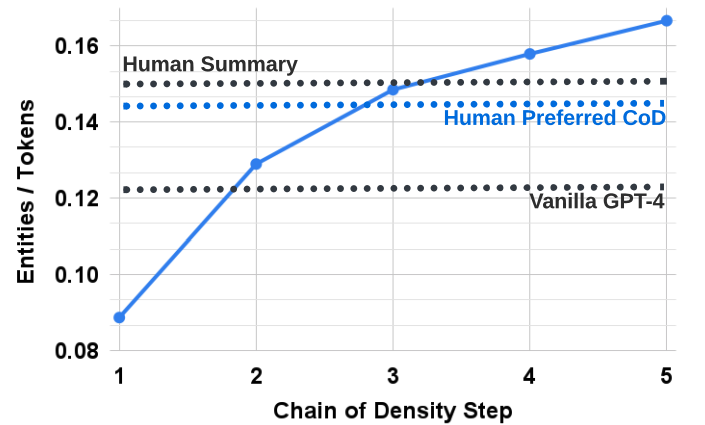
CoD提示很大程度上限制了生成摘要的預(yù)期token數(shù)量,可以看到,從第二步開(kāi)始從冗長(zhǎng)的初始摘要中逐漸刪除不必要的單詞,使得文本長(zhǎng)度平均減少5個(gè)token(72到67)。
實(shí)體密度也隨之上升,最開(kāi)始是0.089,低于人類(lèi)和GPT-4的結(jié)果(分別為0.151和0.122),而在5步操作后密度上升到0.167。
間接統(tǒng)計(jì)指標(biāo)
使用抽取密度(extractive density,即抽取片段的平均長(zhǎng)度的平方)來(lái)衡量文本的抽象性(abstractiveness),預(yù)期文本應(yīng)該隨CoD的迭代進(jìn)展而增加。
使用「摘要句子與源文本對(duì)齊數(shù)量」作為概念融合(fusion)指標(biāo),其中對(duì)齊算法使用「相對(duì)ROUGE增益」,將源句子與目標(biāo)句子對(duì)齊,直到額外添加的句子不會(huì)繼續(xù)提升相對(duì)ROUGE增益為止,預(yù)期融合應(yīng)該逐漸增加。
使用「摘要內(nèi)容在源文本中的位置」作為內(nèi)容分布(Content Distribution)指標(biāo),具體測(cè)量方法為所有對(duì)齊源句子的平均排序,預(yù)期CoD摘要最初表現(xiàn)出明顯的Lead Bias,后續(xù)逐漸開(kāi)始從文章的中間和結(jié)尾部分引入實(shí)體。
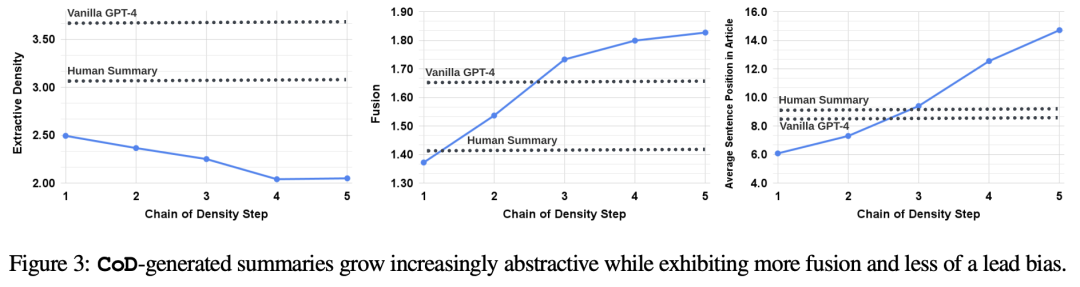
統(tǒng)計(jì)結(jié)果也驗(yàn)證了預(yù)期結(jié)果的正確性:抽象性隨著重寫(xiě)過(guò)程而逐漸增加、融合率上升、摘要開(kāi)始納入文章中間和結(jié)尾的內(nèi)容。
并且,所有CoD摘要都比手工編寫(xiě)和基線模型生成的摘要更加抽象。
實(shí)驗(yàn)結(jié)果
為了更好地理解CoD摘要的權(quán)衡,我們用GPT-4進(jìn)行了一項(xiàng)基于偏好的人體研究和一項(xiàng)基于評(píng)級(jí)的評(píng)估。
人類(lèi)偏好評(píng)估
研究人員主要以評(píng)估致密化(densification)對(duì)人類(lèi)整體質(zhì)量評(píng)估的影響。
具體來(lái)說(shuō),輸入100篇文章,可以得到「5個(gè)步驟*100=總計(jì)500個(gè)摘要」,向四位標(biāo)注人員隨機(jī)展示摘要結(jié)果,并根據(jù)原文忠實(shí)度(Essence)、清晰性(Clarity)、準(zhǔn)確性(Accuracy)、目的性(Purpose)、簡(jiǎn)潔性(Concise)和風(fēng)格(Style)對(duì)摘要進(jìn)行評(píng)估。

從票選結(jié)果來(lái)看,第二個(gè)CoD步驟獲得了最高評(píng)價(jià),再結(jié)合之前平均密度的實(shí)驗(yàn)結(jié)果,可以大體推斷出人類(lèi)更傾向于選擇實(shí)體密度約為15%的文本摘要,顯著高于GPT-4生成的摘要(實(shí)體密度0.122)。

自動(dòng)評(píng)估指標(biāo)
最近一些工作已經(jīng)證明了GPT-4的評(píng)估與人類(lèi)評(píng)估結(jié)果之間的相關(guān)性非常高,甚至有可能在部分標(biāo)注任務(wù)上比眾包工作者的表現(xiàn)還要好。
作為人工評(píng)估的補(bǔ)充,研究人員提出使用GPT-4從5個(gè)方面對(duì)CoD摘要(1-5)進(jìn)行評(píng)級(jí):信息量(Informative)、質(zhì)量(Quality)、連貫性(Coherence)、歸因(Attributable)和整體性(Overall)。
使用的指令模版為:
Article: {{Article}}
Summary: {{Summary}}
Please rate the summary (1=worst to 5=best) with respect to {{Dimension}}.
{{Definition}}
其中各個(gè)指標(biāo)的定義為:
信息量:信息量豐富的摘要可以抓住文章中的重要信息,并準(zhǔn)確簡(jiǎn)潔地呈現(xiàn)出來(lái)。(An informative summary captures the important information in the article and presents it accurately and concisely.)
質(zhì)量:高質(zhì)量的摘要是可理解的。(A high quality summary is comprehensible and understandable.)
連貫性:連貫一致的摘要結(jié)構(gòu)嚴(yán)謹(jǐn),組織有序。(A coherent summary is well-structured and well-organized.)
歸因:摘要中的所有信息是否完全歸因文章?(Is all the information in the
summary fully attributable to the Article?)
總體偏好:一個(gè)好的摘要應(yīng)該以簡(jiǎn)潔、邏輯和連貫的方式傳達(dá)文章的主要觀點(diǎn)。(A good summary should convey the main ideas in the Article in a concise, logical, and coherent fashion.)
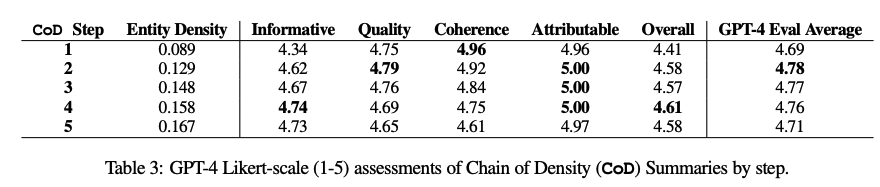
實(shí)驗(yàn)結(jié)果表明,致密化與信息量相關(guān),但得分在第4步時(shí)達(dá)到峰值(4.74);質(zhì)量和連貫性的下降更快;所有摘要均被視為歸因自源文章;總體得分傾向于更密集和更翔實(shí)的總結(jié),第4步得分最高。平均而言,第一個(gè)和最后一個(gè)CoD步驟最不受青睞,而中間三個(gè)步驟很接近(分別為4.78、4.77和4.76)。
定性分析
摘要的連貫性/可讀性和信息量之間在迭代的過(guò)程中需要權(quán)衡。

上面例子中展示了兩個(gè)CoD步驟,分別包含更細(xì)節(jié)的內(nèi)容和更粗略的內(nèi)容。
平均而言,中間步驟的CoD摘要可以更好地實(shí)現(xiàn)平衡,但如何精確定義和量化這種平衡目前還沒(méi)有工作。