













7.7億參數,超越5400億PaLM!UW谷歌提出「分步蒸餾」,只需80%訓練數據|ACL 2023
大型語言模型雖然性能優異,可以用零樣本或少樣本提示解決新任務,但LLM在實際應用部署時卻很不實用,內存利用效率低,并且需要大量計算資源。
比如運行一個1750億參數的語言模型服務至少需要350GB的顯存,而目前最先進的語言模型大多已超過5000億參數量,很多研究團隊都沒有足夠的資源來運行,在現實應用中也無法滿足低延遲性能。
也有一些研究使用人工標注數據或使用LLM生成的標簽進行蒸餾來訓練較小的、任務專用的模型,不過微調和蒸餾需要大量的訓練數據才能實現與LLM相當的性能。
為了解決大模型的資源需求問題,華盛頓大學聯合谷歌提出了一種新的蒸餾機制「分步蒸餾」(Distilling Step-by-Step),蒸餾后的模型尺寸相比原模型來說非常小,但性能卻更好,并且微調和蒸餾過程中所需的訓練數據也更少。

論文鏈接:https://arxiv.org/abs/2305.02301
分布蒸餾機制把LLM中抽取出的預測理由(rationale)作為在多任務框架內訓練小模型的額外監督信息。

在4個NLP基準上進行實驗后,可以發現:
1. 與微調和蒸餾相比,該機制用更少的訓練樣本實現了更好的性能;
2. 相比少樣本提示LLM,該機制使用更小尺寸的模型實現了更好的性能;
3. 同時降低模型尺寸和數據量也可以實現優于LLM的性能。
實驗中,微調后770M的T5模型在基準測試中僅使用80%的可用數據就優于少樣本提示的540B的PaLM模型,而標準微調相同的T5模型即使使用100%的數據集也難以匹配。
蒸餾方法
分布蒸餾(distilling step by step)的關鍵思想是抽取出信息豐富且用自然語言描述的預測理由,即中間推理步驟,可以解釋輸入問題與模型輸出之間的聯系,然后再反過來用該數據以更高效的方式訓練小模型。
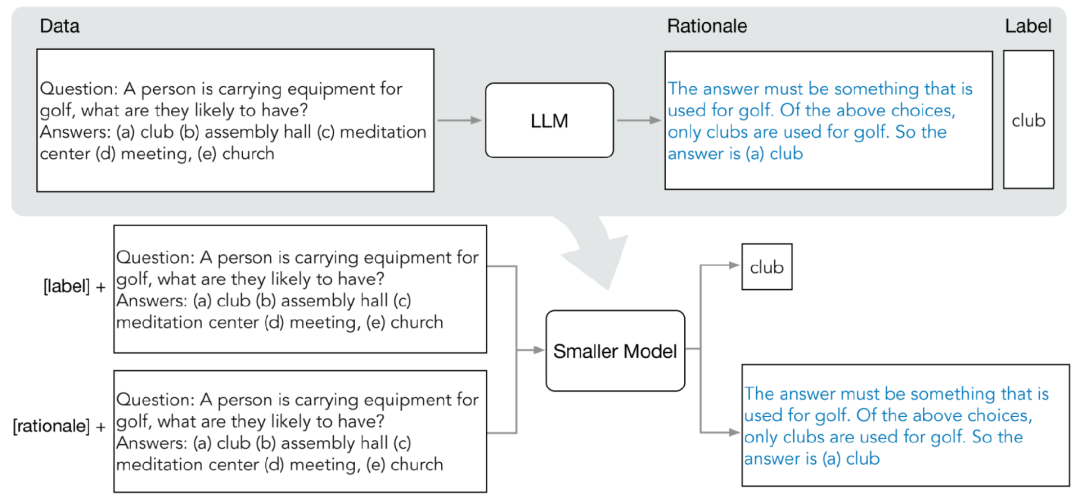
分布蒸餾主要由兩個階段組成:
1. 從LLM中抽取原理(rationale)
研究人員利用少樣本思維鏈(CoT)提示從LLM中提取預測中間步驟。
給定目標任務后,先在LLM輸入提示中準備幾個樣例,其中每個樣例由一個三元組組成,包含(輸入,原理,輸出)。

輸入提示后,LLM能夠模仿三元組演示以生成其他新問題的預測原理,例如,在常識問答案任務中,給定輸入問題:
「Sammy想要去人群所在的地方。他會去哪里?答案選項:(a)人口稠密地區,(B)賽道,(c)沙漠,(d)公寓,(e)路障」
(Sammy wanted to go to where the people are. Where might he go? Answer Choices: (a) populated areas, (b) race track, (c) desert, (d) apartment, (e) roadblock)
通過逐步提煉后,LLM可以給出問題的正確答案「(a)人口稠密地區」,并且提供回答問題的理由「答案必須是一個有很多人的地方,在上述選擇中,只有人口稠密的地區有很多人。」
通過在提示中提供與基本原理配對的CoT示例,上下文學習能力可以讓LLM為沒見過的問題類型生成相應的回答理由。
2. 訓練小模型
通過將訓練過程構建為多任務問題,將預測理由抽取出來,并將其納入訓練小模型中。
除了標準標簽預測任務之外,研究人員還使用新的理由生成任務來訓練小模型,使得模型能夠學習生成用于預測的中間推理步驟,并且引導模型更好地預測結果標簽。
通過在輸入提示中加入任務前綴「label」和「rationale」來區分標簽預測和理由生成任務。
實驗結果
在實驗中,研究人員選擇5400億參數量的PaLM模型作為LLM基線,使用T5模型作為任務相關的下游小模型。
然后在三個不同的NLP任務中對四個基準數據集進行了實驗:用于自然語言推理的e-SNLI和ANLI、常識問答的CQA,以及用于算術數學應用題的SVAMP.
更少的訓練數據
與標準微調相比,分步蒸餾方法使用更少的訓練數據即實現了更好的性能。
在e-SNLI數據集上,當使用完整數據集的12.5%時就實現了比標準微調更好的性能,在ANLI、CQA和SVAMP上分別只需要75%、25%和20%的訓練數據。
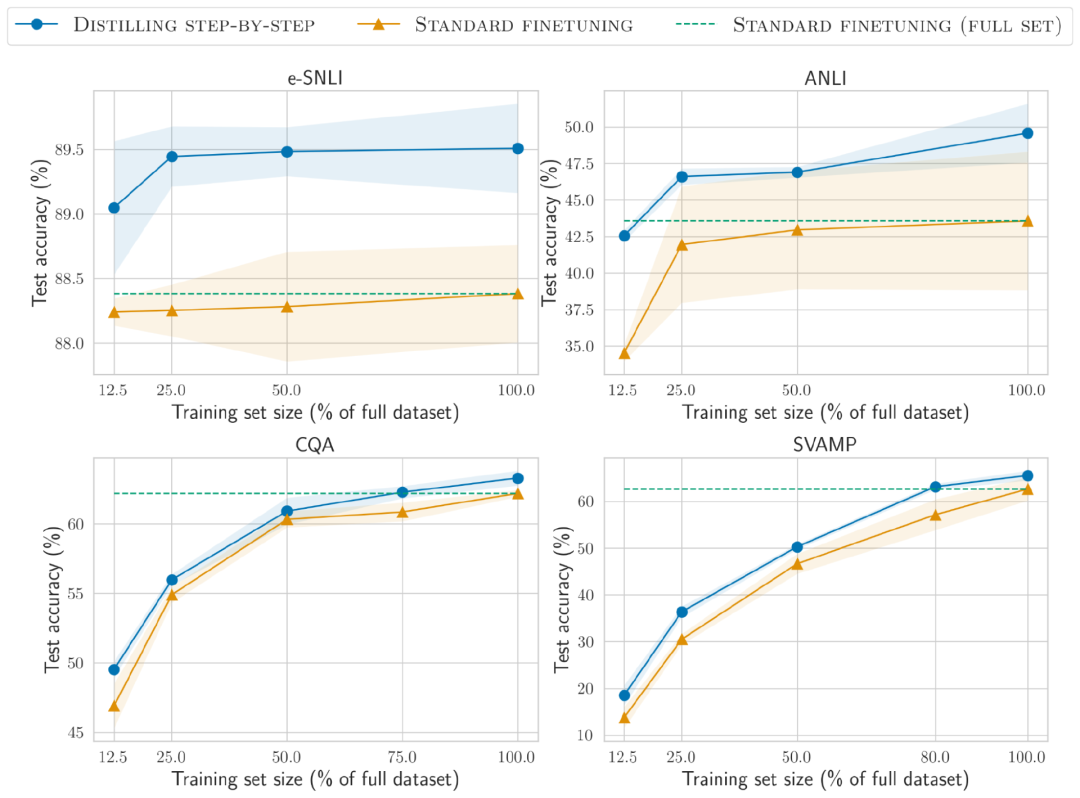
與使用220M T5模型對不同大小的人工標記數據集進行標準微調相比,在所有數據集上,分布蒸餾使用更少的訓練示例優于在完整數據集上訓練的標準微調。
更小的部署模型尺寸
與少樣本CoT提示的LLM相比,分布蒸餾得到的模型尺寸要小得多,但性能卻更好。
在e-SNLI數據集上,使用220M的T5模型實現了比540B的PaLM更好的性能;在ANLI上,使用770M的T5模型實現了比540B的PaLM更好的性能,模型尺寸僅為1/700
更小的模型、更少的數據
在模型尺寸和訓練數據同時降低的情況下,也實現了超越少樣本PaLM的性能。
在ANLI上,使用770M T5模型超越了540B PaLM的性能,只使用了完整數據集的80%

并且可以觀察到,即使使用100%的完整數據集,標準微調也無法趕上PaLM的性能,表明分步蒸餾可以同時減少模型尺寸和訓練數據量實現超越LLM的性能。

























