













70億LLaMA媲美5400億PaLM!MIT驚人研究用「博弈論」改進(jìn)大模型|ICLR 2024
遇到一個(gè)問題用不同表達(dá)方式prompt時(shí),大模型往往會(huì)給出兩種不同的答案。
比如,「秘魯?shù)氖锥际鞘裁础梗咐R是秘魯?shù)氖锥紗帷埂?/span>
對于這種回答不一致的問題,科學(xué)家們紛紛為大模型的「智商」擔(dān)憂起來。
正如了LeCun所言:
LLM確實(shí)比狗積累了更多的事實(shí)知識(shí)和語言能力。但是它們對物理世界的理解能力,以及推理規(guī)劃能力,遠(yuǎn)遠(yuǎn)不及狗。

那么,有沒有一種方式,能夠解開大模型幻覺,讓結(jié)果更加準(zhǔn)確、高效?
來自MIT的研究人員,將「博弈論」的思想引入大模型的改進(jìn)中。
他們共同設(shè)計(jì)了一個(gè)游戲,在游戲中,讓模型的兩種模式(生成式和判別式)相互對抗,努力找到它們可以達(dá)成一致的答案。
這個(gè)簡單的博弈過程,被稱為「共識(shí)博弈」(CONSENSUS GAME)。
也就是,讓模型自我對抗,以提升LLM準(zhǔn)確性和內(nèi)部一致性。

論文地址:https://openreview.net/pdf?id=n9xeGcI4Yg
具體來說,這是一種免訓(xùn)練,基于博弈論的語言模型解碼過程。
新方法將語言模型解碼,視為一種正則化的不完全信息序列信號博弈游戲——稱之為CONSENSUS GAME(共識(shí)博弈)。
其中,生成器(GENERATOR)試圖使用自然語言句子,向一個(gè)判別器(DISCRIMINATOR)傳達(dá)抽象的正確性參數(shù)。

然后,研究人員開發(fā)了計(jì)算程序,以尋找博弈的近似均衡,從而得到一種名為「均衡排序」(EQUILIBRIUM-RANKING)的解碼算法。
在多個(gè)基準(zhǔn)測試中,「均衡排序」策略在LLaMA-7B的表現(xiàn)中,明顯超越LLaMA-65B,并與PaLM540B相媲美。

最新論文已被ICLR 2024接收。

谷歌研究科學(xué)家Ahmad Beirami表示,「幾十年來,LLM對提示的響應(yīng)方式一直如出一轍。MIT研究人員提出了將博弈論引入這一過程的新穎想法,開創(chuàng)了一個(gè)全新的范式,這有可能帶來大量新的應(yīng)用」。
游戲,不再單純是衡量AI的標(biāo)準(zhǔn)
以往,通過機(jī)器學(xué)習(xí)在游戲競賽中的表現(xiàn),去判斷某個(gè)AI系統(tǒng)是否取得成功。
而這樣的案例,比比皆是。
1997年,IBM深藍(lán)計(jì)算機(jī)擊敗了國際象棋特級大師Garry Kasparov,創(chuàng)下了所謂的「思考機(jī)器」的里程碑。
19年后,谷歌DeepMind發(fā)明的AlphaGo,在圍棋比賽中一舉戰(zhàn)勝李世石。
五局比賽中獲勝四局,揭示了人類在某些領(lǐng)域已不再獨(dú)占鰲頭。
不僅如此,AI還在跳棋、雙人撲克,以及其他的「零和游戲」中超越了人類。
與以往不同的是,MIT團(tuán)隊(duì)而是選擇從另一個(gè)角度來看問題——用游戲去改進(jìn)人工智能。
對于AI研究人員來說,一款稱為「Diplomacy」的游戲,提出了一個(gè)更大的挑戰(zhàn)。

由Allan B. Calhamer于1959年設(shè)計(jì)的經(jīng)典桌游
與只有2個(gè)對手玩家的游戲不同,Diplomacy游戲有7個(gè)玩家參與,每個(gè)人的動(dòng)機(jī)都很難看透。
要想獲勝,玩家必須談判,締結(jié)合作關(guān)系,但不得不提防的是,任何時(shí)候任何人都可能遭到背叛。
這款游戲如此復(fù)雜,以至于2022年,Meta團(tuán)隊(duì)發(fā)布的Cicero在40局游戲后,達(dá)到「人類水平」時(shí),引發(fā)一陣轟動(dòng)。

論文地址:https://www.science.org/doi/10.1126/science.ade9097
盡管Cicero沒能戰(zhàn)勝世界冠軍,但它在與人類參與者的比賽中進(jìn)入了前10%,表現(xiàn)足夠優(yōu)秀。

現(xiàn)在,論文作者Athul Paul Jacob是MIT的博士生,曾在Meta實(shí)習(xí)期間參與了這次研究。
研究期間,Jacob對Cicero依賴語言模型,與其他玩家進(jìn)行對話的事實(shí)感到震驚。
他感受到了,尚未開發(fā)出的AI潛力。

Athul Paul Jacob幫助設(shè)計(jì)了「共識(shí)博弈」——為LLM提供了一種提高其準(zhǔn)確性和可靠性的方法
于是,他便提出,如果將重點(diǎn)轉(zhuǎn)移到,利用游戲來提高LLM的性能上會(huì)怎樣?
1000場比賽,讓LLM自我對抗
為了追尋這一問題的答案,2023年Jacob與麻省理工學(xué)院的Yikang Shen、Gabriele Farina,以及導(dǎo)師Jacob Andreas一起研究,什么可以促進(jìn)「共識(shí)博弈」。
這一思想的核心是,將兩個(gè)人之間的對話想象成一個(gè)合作游戲。
當(dāng)聽者理解說話者想要傳達(dá)的東西時(shí),就成功了。
尤其是,「共識(shí)博弈」的目的是,旨在協(xié)調(diào)LLM的兩個(gè)系統(tǒng)——生成器和辨別器。
眾所周知,生成器負(fù)責(zé)處理生成性問題,而辨別器負(fù)責(zé)處理辨別性問題。

經(jīng)過幾個(gè)月的研究,他們終于將這一原則,構(gòu)建成了一場完整的比賽。
首先,生成器收到一個(gè)問題——可以來自人類,也可以來自預(yù)存在的名單中,比如「奧巴馬出生在哪里」。
然后,生成器會(huì)得到一些候選響應(yīng),比如火奴魯魯(Honolulu)、芝加哥(Chicago)、內(nèi)羅畢(Nairobi)。
同樣,這些響應(yīng)的選項(xiàng),可以來自人類、列表,或是由語言模型本身執(zhí)行搜索。
但在回答之前,生成器會(huì)先根據(jù)一次公平的隨機(jī)擲幣的結(jié)果,被指示生成正確或錯(cuò)誤的答復(fù)。

如果結(jié)果為正面,那么生成器就會(huì)嘗試給出正確的答案。
然后,生成器將原始問題,及其選擇的回答,一并發(fā)送給判別器。
如果判別器判定生成器,是有意地發(fā)送了正確的回答,作為一種激勵(lì),它們每人得到一分。
而如果結(jié)果為反面,生成器就會(huì)給出它認(rèn)為是錯(cuò)誤的答案,那判別器看出它故意給了錯(cuò)誤答案,它們將在分別得到一分。
這就體現(xiàn)了策略的核心點(diǎn),即通過激勵(lì),讓它們達(dá)成一致。
在這個(gè)博弈過程開始時(shí),生成器和判別器都有自己對答案的「先驗(yàn)信念」。
這些「信念」以概率分布的形式體現(xiàn),比如,生成器基于從互聯(lián)網(wǎng)獲取的信息,可能會(huì)認(rèn)為:
奧巴馬出生在火奴魯魯?shù)母怕适?0%,芝加哥10%,內(nèi)羅畢5%,其他地方5%。
當(dāng)然判別器,也會(huì)有不同概率分布的「先驗(yàn)信念」。
雖然兩個(gè)「玩家」會(huì)因達(dá)成一致而獲得獎(jiǎng)勵(lì),但如果偏離自己「先驗(yàn)信念」太多時(shí),也會(huì)被扣分。
這樣一來,可以鼓勵(lì)「玩家」將從互聯(lián)網(wǎng)獲取的知識(shí),融入到回答中,從而讓模型更加準(zhǔn)確。
如果沒有這種機(jī)制,它們可能會(huì)就一個(gè)完全錯(cuò)誤的答案(如Delhi)上達(dá)成一致,卻仍然獲得分?jǐn)?shù)。
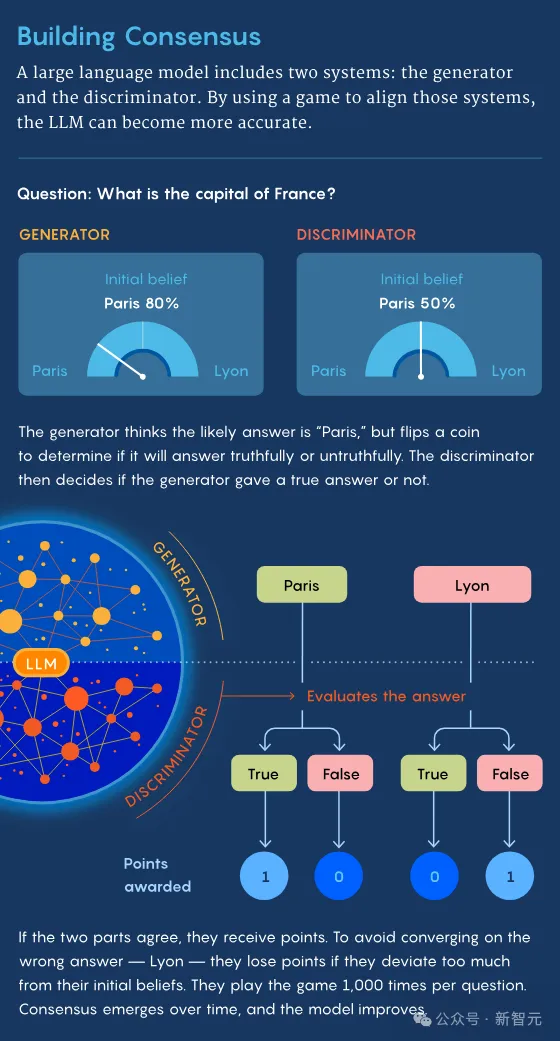
對于每個(gè)問題,這兩個(gè)系統(tǒng)相互之間進(jìn)行了大約1000場比賽。
在無數(shù)次迭代的過程中,雙方都了解了對方的「信念」,并相應(yīng)地修改了自己的戰(zhàn)略。
最終,生成器和判別器開始達(dá)成更多共識(shí),因?yàn)樗鼈冎饾u進(jìn)入了一種稱為「納什均衡」(Nash equilibrium)的狀態(tài)。
這可以說是博弈論的核心概念。
「納什均衡」代表了游戲中的一種平衡狀態(tài),在這點(diǎn)上,任何玩家都無法通過改變策略,來改善個(gè)人結(jié)果。
比如,在石頭剪刀布游戲中,當(dāng)玩家選擇三個(gè)選項(xiàng)的概率正好都是1/3時(shí),才能獲得最佳結(jié)果,任何其他策略都會(huì)導(dǎo)致更糟糕的結(jié)果。
在「共識(shí)博弈」中,「納什均衡」可以通過多種方式實(shí)現(xiàn)。
比如,判別器可能會(huì)觀察到,每當(dāng)生成器將奧巴馬的出生地回答為「火奴魯魯」時(shí),它就會(huì)得分。
經(jīng)過多輪博弈,生成器和判別器會(huì)學(xué)習(xí)到,繼續(xù)這種作答方式會(huì)得到獎(jiǎng)勵(lì),而沒有動(dòng)機(jī)改變策略。
這種一致的作答方式,就代表了對于該問題的一種可能的「納什均衡」。
70B參數(shù)Llama,媲美5400億參數(shù)PaLM
除此之外,還可能存在其他「納什均衡」的解。
MIT團(tuán)隊(duì)還依賴于一種改進(jìn)的「納什均衡」形式,結(jié)合了玩家們的「先驗(yàn)信念」,有助于讓回答結(jié)果更加貼近現(xiàn)實(shí)。
為了測試「共識(shí)博弈」的效果,研究團(tuán)隊(duì)在一些中等參數(shù)規(guī)模的語言模型(70億-130億參數(shù))上進(jìn)行了一系列標(biāo)準(zhǔn)問題測試。
經(jīng)過訓(xùn)練后的這些模型,正確答案的比例明顯高于未經(jīng)訓(xùn)練的模型,甚至高于一些擁有高達(dá)5400億參數(shù)的大型模型PaLM。
這不僅提高了模型的答案準(zhǔn)確性,也增強(qiáng)了模型的內(nèi)部一致性。

另外,在TruthfulQA(生成)的結(jié)果上,具有ER-G的LLaMA-13B優(yōu)于或與所有基線持平。

研究人員在GSM8K測試集上,對不同方法的平均準(zhǔn)確率進(jìn)行了評估和對比。
除了greedy外,都是對20個(gè)候選回答進(jìn)行了采樣。
基于「均衡排序」的方法,其性能與多數(shù)投票基線相當(dāng),或者稍微好一些。

一般來說,任何LLM都可以通過與自身進(jìn)行「共識(shí)博弈」從中獲益。
最重要的是,研究人員成,只需在一臺(tái)筆記本上,進(jìn)行的1000輪「共識(shí)博弈」僅需幾毫秒的時(shí)間,計(jì)算代價(jià)很小。
Omidshafiei表示,「這種方法非常高效,不需要對基礎(chǔ)語言模型進(jìn)行訓(xùn)練或修改」。
下一步,大小模型一起游戲
在「共識(shí)博弈」取得初步成功后,Jacob現(xiàn)在正在探索將博弈論,應(yīng)用到LLM研究中的其他方式。
在這個(gè)基礎(chǔ)上,他現(xiàn)在又提出了一種新的方法,暫稱為「集成博弈」(ensemble game)。
在「集成博弈」中,有一個(gè)主模型(primary LLM),與若干個(gè)小型模型進(jìn)行博弈互動(dòng)。
這些小型模型中,至少有一個(gè)扮演「盟友」角色,至少有一個(gè)扮演「對手」角色。
問題出現(xiàn)時(shí),比如法國首都是什么,如果主模型與「盟友」模型給出相同答案,主模型會(huì)獲得分?jǐn)?shù)。
如果與「對手」模型給出不同答案,也會(huì)獲得分?jǐn)?shù)。
通過這種與小模型的博弈互動(dòng),并不需要對主模型進(jìn)行額外訓(xùn)練或改變參數(shù),就可以進(jìn)一步提升主模型的性能表現(xiàn)。
這種將大模型與多個(gè)小模型集成互動(dòng)的新范式,讓大模型可以借鑒小模型的優(yōu)點(diǎn)。
同時(shí)還能相互制約,從而提高整體的準(zhǔn)確性和一致性。
在未來,它將為提升LLM性能開辟了一種全新的思路和方法。

























