作者 | 金色旭光
一、背景介紹
我是一名Python開發,就職于一家AI公司,負責開發迭代一個深度學習的模型訓練平臺。模型訓練平臺主要是給算法工程師訓練模型,開發語言是Python,Web框架為Fastapi。模型訓練使用Pytorch框架,封裝成Docker運行。我負責除Pytorch之外平臺功能開發,有一位算法工程師負責Pytorch開發,封裝成容器提供給我。
目前這個訓練平臺是單機版,支持多顯卡訓練,也就是所謂的單機多卡的訓練模式。隨著公司業務的發展,模型訓練需要的GPU越來越多。單臺服務器支持顯卡數量再多也會有一個上限,這時就需要能夠使用多臺GPU服務器上的多個顯卡,也就是多機多卡的訓練模式。
在這樣的背景下,我需要將單機的訓練平臺升級為分布式的訓練平臺。只有我一桿槍,一個配合的算法工程師,一個前端,一個測試。經過將近兩個月的開發,完成了這個任務。
開發過程遇到的非常多的問題,折磨了我一次又一次。好在最后基本都解決問題了。本篇就從需求說明、實現方案、踩坑經歷等方面來介紹這一段特殊而難得的開發經歷。
二、需求說明
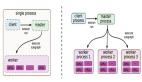
1.單機版架構
首先介紹一下單機版模型訓練平臺。模型訓練簡單來說就是用訓練容器讀取數據集,跑模型訓練,最終生成一個模型文件。
 圖片
圖片
模型訓練主要有兩個步驟:
- 準備數據集
- 啟動訓練容器跑訓練
單機版顧名思義數據集、訓練容器、生成的模型等所有流程都在一臺服務器上完成。
2.分布式版架構
分布式的訓練平臺是將訓練任務分發到多個訓練節點上,讓多臺服務器的GPU互相通信,算力統一起來使用。
 圖片
圖片
想要將這樣一個單機架構的平臺升級成分布式平臺需要實現的功能有三個:
- 每個訓練節點都要讀取全量的數據集,需要將數據集復制到各個訓練節點
- 多個訓練節點要支持跨節點的模型訓練
- 容器啟動命令要能夠下發到訓練節點
其中第2個功能Pytorch模型訓練框架已經支持了分布式的訓練模式,并且當前系統做分布式也是基于這個能力才有可能開發完成。
DistributedDataParallel(DDP)是一個支持多機多卡、分布式訓練的深度學習工程方法。Pytorch現已原生支持DDP,可以直接通過torch.distributed使用。
讓Pytorch訓練容器支持ddp是由算法工程師去完成的,對于我來說,只需要在訓練節點1和2上執行不同的容器啟動命令即可。
三、實現方案
針對實現功能1、3,技術方案設計如下:
1.數據集復制
因為數據集只能從主節點上傳到平臺,所以要想將數據集移動到訓練節點有兩個方案,分別是:NFS共享目錄、文件同步 。
NFS
NFS不用過多介紹了,就是本地掛載一塊遠端機器的目錄,將遠端目錄當做本地目錄使用。
優點:NFS 的優點是內核直接支持,部署簡單、運行穩定,協議簡單。
缺點:通過網絡讀取數據集,IO速度會成為數據加載的瓶頸。
NFS的缺點是網絡傳輸速度慢,我們的環境只有千兆帶寬,在模型訓練時通過千兆帶寬分布式進程通信會讓整體的訓練速度慢一個等級。最優解是IB網,IB網是轉為大規模數據中心設計的網絡架構,帶寬能達到50G,但是我們沒有,客戶大概率也用不上成本飆升的IB網。
文件同步
通過文件同步可以將數據集分發到訓練節點。比較了常規文件同步使用的技術,最后選擇了lsyncd這款工具。
rsync 是Linux系統上一款開源的快速的可實現全量及增量遠程數據同步備份的優秀工具。lysncd 是lua語言封裝了 inotify 和 rsync 工具,采用了 Linux 內核里的 inotify 事件觸發機制,然后通過rsync同步差異,達到實時的效果。
優點:支持斷點續傳;同步數據集,能夠滿足模型訓練需要的IO速度
缺點:同一份文件會復制出多份,存在冗余,增加存儲的壓力;文件同步是基于時間間隔或累計文件數據量,非嚴格意義的實時。
方案選擇
因為NFS的缺點比較致命,而lsyncd的缺點通過邏輯可以克服。所以數據集的最終解決辦法是使用lsyncd同步數據集,同時也需要將訓練節點生成的模型等文件同步到主服務上,即雙向同步(這里有坑,下文會說)
2.遠程執行命令
單機版運行時直接在本機通過命令啟動訓練容器,命令類似:
nvidia-docker run--gpus '"device=0"' -name train_container_1 7055fe2b9719分布式訓練需要選擇一臺服務器做主節點,多臺服務器做訓練節點,需要在不同的服務器上啟動多條命令。所以就需要一個能遠程執行命令的功能。
能夠遠程執行的技術選型還有:
- http 請求
- rpc 請求
- ssh 遠程執行
- socket 網絡
- 中間件發布訂閱
經過對比,最終選擇rpc來實現這個功能,理由如下:
- rpc 可以同步響應
- rpc 基于IP地址調用,符合當前整體架構
- rpc 服務端方便記錄調用的日志
- 沒有中間件,組件少,技術簡單
Python 中rpc相關的庫有很多,如:
- python自帶的庫 xmlRPC
- google開源可跨語言的 grpc
- 第三方庫 zerorpc
- 第三方庫 jsonrpclib
經過比較選擇zerorpc,原因是靈活、輕量級、高性能。zerorpc的demo如下:
服務端:
import zerorpc
class HelloRPC(object):
def hello(self, name):
return "Hello, %s" % name
s = zerorpc.Server(HelloRPC())
s.bind("tcp://0.0.0.0:4242")
s.run()客戶端:
import zerorpc
c = zerorpc.Client()
c.connect("tcp://127.0.0.1:4242")
print(c.hello("RPC"))四、開發過程記錄
編碼時間大概5個星期左右,時間是蠻久,只怪咱只有一個人。進度流水賬如下:
1.部署lsyncd同步工具,讓數據集能夠從主節點同步到訓練節點
2.開發rpc的服務端和客戶端,訓練命令下發到選中的節點
3.通過rpc獲取訓練節點GPU信息,讓頁面支持選擇不同機器的GPU
4.調試遠程訓練單機單卡,調通數據集分發和訓練命令下發
5.和算法工程師確定多機多卡訓練容器的啟動命令
6.調試多機多卡訓練,發現ddp啟動會阻塞,解決問題花費一個星期
7.發現rpc有問題,替換zerorpc為grpc
8.數據集同步和執行訓練命令之間有先后依賴關系,解決同步問題
9.模型訓練、推理、驗證三個主要功能完成
經過5個星期的開發,最終完成了模型訓練的基本功能,包括模型訓練、模型驗證、模型推理。由于架構的變化應該可能潛在一些未發現的bug。對于bug來說,發現它是測試同事的工作,而是我的任務就是送它去見測試同事。所以,就轉測了。
五、遇到的問題
經過三輪的測試,在修復了很多bug之后,最終完成了分布式功能版本的開發。
在這兩個月中,我遇到了非常多問題,我登記在冊的問題是13個,實際上還有一些未上榜的,主要原因是從單節點到分布式涉及到存儲、通信等變化讓系統復雜。
限于篇幅挑選幾個講講,給后續使用相關技術的人一個避坑的提醒。
1.zerorpc 服務端不支持多線程并發請求
調研zerorpc時,我關注的點包括是否滿足功能要求、代碼復雜性、模塊的活躍度、github代碼提交時間等。從我關注點出發,zerorpc是比較完美符合我要求的,但是完成相關功能開發之后才發現zerorpc竟然不支持并發請求。真是廁所里跳高——過分。
現象:多個客戶端請求達到服務端,請求會變成串行執行
原因:zerorpc是基于協程庫gevent實現的并發,而我們的技術棧不是協程,這就導致zerorpc不支持并發操作。
解決辦法:rpc服務端肯定需要支持并發請求,將zerorpc換成了grpc。
之所以開始沒有選擇grpc,是因為grpc使用略復雜,需要先寫proto文件,編譯,再分別實現客戶端和服務端。但實事證明雖然繁瑣了一些,grpc還是值得信賴的。
2.數據集篩選報錯
數據集是決定模型質量的一個重要因素,所以對數據集會有合并、過濾、篩選等操作,每次操作都會生成一份新的數據集文件。
現象:測試發現篩選數據集時偶爾會報錯,大概篩選10次以上就會出現。
原因:非必現的問題是最頭疼的問題。這個問題我排查了3天,最后發現是lsyncd雙向同步的問題,也就是我在技術選型中提到的坑。
數據集篩選會生成一個新的文件夾,這個文件夾由主節點一邊生成一邊同步給訓練節點,而訓練節點在同步時間到來時也會給反向同步給主節點,這就會導致覆蓋掉主節點原本文件夾的目錄,從而破壞了原數據集。
解決辦法:根據規則關閉到從節點到主節點的同步,避免反向同步。
這個問題想要解決除非更換lsyncd工具,否則沒有完美的方法。可以嘗試使用git大文件同步方案來替換lsyncd,當然最好的方案還是基于IB網的NFS,既能滿足速度要求,又能避免冗余。
3.主節點異常退出,從節點不能退出
Pytorch實現多機多卡的分布式訓練時會啟動一個主節點和多個從節點。
現象:在多機多卡訓練時,主節點異常退出時,從節點不能正常退出。主節點可能是因為讀取數據集失敗或者GPU顯存不夠等原因退出,從節點會一直阻塞,并且顯示占用GPU顯存。
原因:在基于Pytorch的分布式中,使用nccl作為后端通信機制時,是沒有超時功能的。如果主服務阻塞,那么從服務會一直等待。
解決辦法:設置一個環境變量,NCCL_ASYNC_ERROR_HANDLING=1,然后給ddp進程組設置超時時間
import torch.distributed as dist
dist.init_process_group(
…
backend="nccl",
timeout=timedelta(secnotallow=60)
)六、一種解決疑難問題的套路
遇到的這么多問題,如果全都是靠蠻力解決,那我頭上的頭發也保不住了。在這個過程中,我使用自己總結的一種解決疑難雜癥的思路去分析問題,解決問題,我把它叫做解決疑難問題的套路。
解決疑難問題的套路包含了分析和解決,簡單來說分為三步:問題的現象是什么?已知內容是什么?列出合理的猜測。
下面分別介紹每一步做什么。
1.問題的現象
想要解決一個問題首先要非常清楚問題是什么,所以第一步就是要搞清楚問題的現象是什么。以主節點異常退出,從節點不能退出為例,這個問題的現象就是當主節點訓練容器exit之后,從節點繼續運行,不會退出。
有時看到的還不一定是真正的現象,需要稍作分析判斷,找出真正的現象,否則可能會南轅北轍。
2.已知的內容
在知道問題的現象之后,列出已經掌握肯定的、準確無誤的線索。這些線索是解決問題的基礎、靈感、出發點。比如可以是一些計算機基礎知識,也可以是在這個場景下反復實驗得到的結論。以主節點異常退出,從節點不能退出為例,已知的內容是主節點和訓練節點之間網絡肯定是互通的,排除網絡不達的可能。
列出已知內容,能夠收縮猜想的范圍,排除疑點,減少可能性。
3.列出合理的猜測
在了解現象知道肯定的線索的之后,就能做出合理的猜測。最后一步就是匯總前面掌握的情況,從現象出發,根據已知的線索,列出可能產生問題的原因。以主節點異常退出,從節點不能退出為例,可能的原因包括:
(1)訓練節點容器沒有捕獲到退出信號;
(2)NCCL主從進程沒有斷開,一直阻塞;
(3)NCCL主從進程斷開,程序沒有捕獲異常。
最后逐一驗證猜想,這個過程中可能解決問題,可能發現新的線索。如果不能解決問題,再來一輪,基于上一輪的掌握的新線索做出合理的猜想,驗證所有的猜想。掌握的線索越來越多,問題的范圍越來越小,最終一定抓住這個bug。
貼一個問題的解決過程,如下。

七、收獲
經過這一段時間的開發,接觸到很多新知識,收獲也還不錯。
1.學習模型訓練框架Pytorch dpp
學習了Pytorch的實現,了解了模型訓練過程,了解Pytorch ddp的原理,學習了一個進程等待的巧妙方法。
@contextmanager
def torch_distributed_zero_first(local_rank: int):
# Decorator to make all processes in distributed training wait for each local_master to do something
if local_rank not in [-1, 0]:
dist.barrier(device_ids=[local_rank])
yield
if local_rank == 0:
dist.barrier(device_ids=[0])
# 使用該裝飾器下載資源
with torch_distributed_zero_first(LOCAL_RANK):
weights = attempt_download(weights) # download if not found locallydist.barrier 是PyTorch 的分布式通信庫,會阻塞等待,所有注冊進程都到齊了才會通過。
從語法上來說:使用上下文管理器加yield關鍵字實現一個裝飾器;從功能上來說:讓所有子進程等待,放過主進程做一些操作,等主進程操作完成才會放行所有進程。用于只有主進程才能操作的場景。
2.做復雜的技術方案
該技術方案是我做過最復雜的技術方案,有架構設計、技術選型、技術優劣對比、潛在問題、解決辦法等。總結出一個寫技術方案的模板:
(1)關鍵技術分析
(2)要實現的功能
(3)技術難點
(4)實現方案
(5)優劣對比
(6)最佳方案理由
(7)遺留問題解決辦法
3.技術選型
技術選型是一個比較困難的工作,我在選擇的rpc框架zerorpc和文件同步工具lsyncd一定程度上都存在問題。zerorpc不能并發、lsyncd存在雙向同步的問題。
技術選項要從幾個點出發:
(1)是否能夠滿足業務邏輯
(2)是否符合當前技術棧
(3)技術復雜性不能過高
(4)是否有明顯的缺陷
像是zerorpc框架就有明顯的缺陷,在查閱資料的時候也見過有些文章提到zerorpc是基于協程的并發,但當時并沒有仔細思考,直到碰見并發請求才發現問題。
4.個人感受
一個人開發一個項目,我最大的感受就是太爽了。這種感覺就像自己在蓋一個大別墅,圖紙設計是我做,搬磚砌墻我能搞定,最后造出一個完全屬于自己審美風格的別墅。