













微軟用GPT-4V解讀視頻,看懂電影還能講給盲人聽,1小時不是問題
世界各地的人們每天都會創造大量視頻,包括用戶直播的內容、短視頻、電影、體育比賽、廣告等等。
視頻是一種多功能媒介,可以通過文本、視覺和音頻等多種模態傳遞信息和內容。如果可以開發出能學習多模態數據的方法,就能幫助人們設計出具備強大能力的認知機器 —— 它不會受限于經過人工調整的數據集,而是可以分析原生態的真實世界視頻。但是,在研究視頻理解時,多模態這種豐富的表征會帶來諸多挑戰,尤其是當視頻較長時。
理解長視頻是很復雜的任務,需要能分析多個片段的圖像和音頻序列的先進方法。不僅如此,另一大挑戰是提取不同來源的信息,比如分辨不同的說話人、識別人物以及保持敘述連貫性。此外,基于視頻中的證據回答問題也需要深入理解視頻的內容、語境和字幕。當分析的是直播或游戲視頻時,還存在實時處理動態環境的難題,這需要語義理解和長期策略規劃能力。
近段時間,大型預訓練視頻模型和視頻 - 語言模型帶來了巨大進步,它們在視頻內容上的推理能力已經顯現。但是,這些模型通常是用短視頻片段訓練的(比如 Kinetics 和 VATEX 中的 10 秒視頻)或預定義了動作類別(Something-Something v1 有 174 類)。由此造成的后果是,這些模型可能難以詳細理解真實世界視頻的復雜微妙。
為了讓模型能更全面地理解我們日常生活中遇到的視頻,我們需要能解決這些復雜挑戰的方法。
近日,微軟 Azure AI 為這些問題給出了自己的解答:MM-Vid。該團隊表示這種技術可以直接用于理解真實世界視頻。簡單來說,他們的方法涉及將長視頻分解成連貫敘述,然后再利用這些生成的故事來分析視頻。

- 論文地址:https://arxiv.org/pdf/2310.19773.pdf
- 項目地址:https://multimodal-vid.github.io/
MM-Vid 是近來處于 AI 社區關注中心的大型多模態模型(LMM)的新成員;而 LMM 中最具代表性的 GPT-4V 已經展現出了突破性的能力 —— 可以同時處理輸入的圖像和文本,執行多模態理解。為了實現視頻理解,MM-Vid 將 GPT-4V 與一些專用工具集成到了一起,實驗結果也證明了這種方法的有效性。圖 1 展示了 MM-Vid 能夠實現的多種能力。

MM-Vid 方法介紹
圖 2 展示了 MM-Vid 系統的工作流程。MM-Vid 以視頻文件為輸入,輸出一個描述該視頻內容的腳本。這種生成的腳本讓 LLM 可以實現多種視頻理解能力。

MM-Vid 包含四個模塊:多模態預處理、外部知識收集、視頻片段層面的視頻描述生成、腳本生成。
多模態預處理。對于輸入的視頻文件,預處理模塊首先使用已有的 ASR 工具從視頻中提取出轉錄文本。之后,將視頻切分成多個短視頻片段。此過程需要對視頻幀進行均勻采樣,使得每個片段由 10 幀組成。為了提升幀采樣的整體質量,研究者使用了 PySceneDetect 等成熟的場景檢測工具來幫助識別關鍵的場景邊界。
外部知識收集。在 GPT-4V 的輸入 prompt 中,研究者采用了集成外部知識的方法。該方法涉及收集可用的信息,比如視頻的元數據、標題、摘要和人物面部照片。在實驗中,研究者收集的元數據、標題和摘要來自 YouTube。
片段層面的視頻描述生成。在多模態預處理階段,輸入視頻會被切分為多個視頻片段。每個片段通常包含 10 幀,研究者的做法是使用 GPT-4V 來為每個片段生成視頻描述。通過將視頻幀與相關的文本 prompt 一起輸入到 GPT-4V 模型,便能得到捕獲了這些幀中描繪的視覺元素、動作和事件的詳細描述。
此外,研究者還探索了視覺 prompt 設計,即在 GPT-4V 的輸入中不僅提供人物的名字,還提供人物的面部照片。實驗結果表明這種視覺 prompt 設計有助于提升視頻描述的質量,尤其有助于更準確地識別人物。
使用 LLM 生成腳本。在為每個視頻片段生成描述之后,再使用 GPT-4 將這些片段層面的描述整合成一個連貫的腳本。該腳本是對整個視頻的全面描述,可被 GPT-4 用于解決各種視頻理解任務。
用于流輸入的 MM-Vid
圖 3 展示了用于流輸入的 MM-Vid。
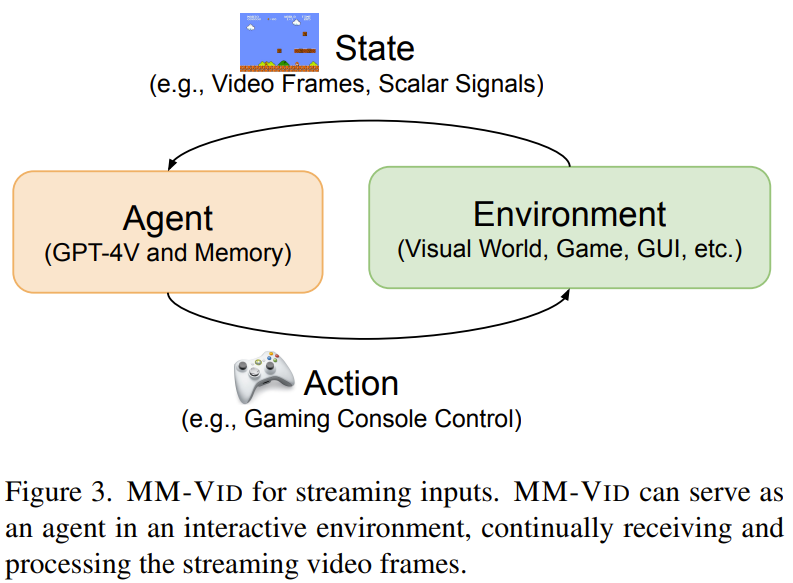
在這種情況下,MM-Vid 的運作模式是作為動態環境中的一個智能體(agent),其主要輸入為流視頻幀。該智能體會將持續輸入的流視頻幀視為狀態,其代表了在該環境中不斷揭示的持續性視覺信息。然后再由 GPT-4V 處理這些狀態,從而得到有信息依據的決策并生成響應。
通過持續分析流視頻幀,MM-Vid 可將原始視覺數據轉換成有意義的見解,進而為視頻游戲、具身智能體和 GUI 引導等應用提供有價值的幫助。
實驗
實驗設置
該團隊實現的 MM-Vid 基于 MM-React 代碼庫。他們使用的自動語音識別(ASR)工具是通過 Azure Cognitive Services API 使用的公開可用工具,場景檢測則是使用了 PySceneDetect。
MM-Vid 的功能
研究者在論文中展示了多個 MM-Vid 完整執行流程的示例。
下面是一個 MM-Vid 執行流程示例。

經過這些流程后,MM-Vid 生成的腳本總結了對視頻內容的理解。從而讓后續 LLM 可以基于此處理具體的任務。研究者討論過的具體任務包括:有根據的問答、多模態推理、理解長達一小時的視頻、多視頻情景分析、人物識別、說話人識別、音頻描述生成、自我調優、快速變化的短視頻。具體詳情請參閱原論文,但總體而言,MM-Vid 都展現出了很不錯的效果。
下面是一個說話人識別的示例。
應用于交互式環境
研究者也評估了 MM-Vid 應用于流輸入時的情況。MM-Vid 可作為交互式環境中的智能體,持續接收流視頻幀輸入。
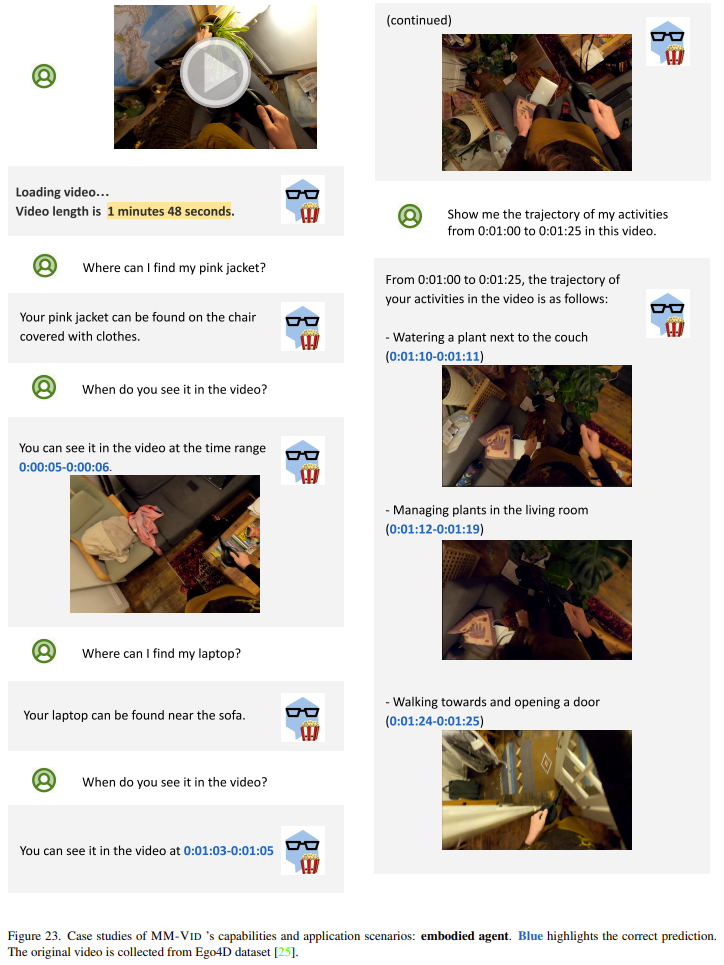
具身智能體。下圖展示了將 MM-Vid 應用于一段頭戴式相機拍攝的第一人稱視頻的情況。這段視頻來自 Ego4D 數據集,簡單展示了拍攝者在家居環境中的日常生活。值得注意的是,MM-Vid 理解這種視頻內容的能力得到了體現,并且還能輔助用戶完成一些實際任務。
玩視頻游戲。下面的視頻示例是將 MM-Vid 用于視頻游戲《超級瑪麗》。實驗中,智能體會持續地以三幀視頻作為輸入的狀態,然后計算下一個可能的控制動作。結果表明,這個智能體能夠理解這種特定的視頻游戲動態,并能生成可以有效玩游戲的合理動作控制。
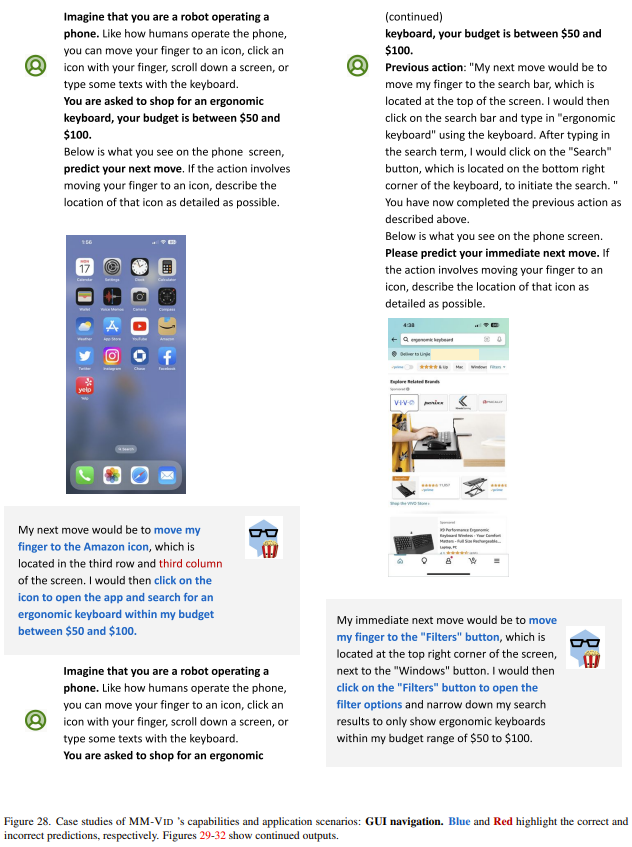
GUI 導引。下圖給出了一個示例。這里,智能體持續接收的輸入是 iPhone 屏幕截圖和之前的用戶動作。結果發現,該智能體可以有效預測用戶使用手機時的下一步可能動作,比如點擊正確的購物應用,然后搜索感興趣的商品,最后下單購買。這些結果表明 MM-Vid 能與圖形用戶界面進行有效的交互,能通過數字接口實現無縫且智能化的用戶導引。
用戶研究
研究者探索 MM-Vid 幫助盲人或弱視者的潛力。音頻描述(AD)能在視頻的音軌中增加音頻敘述,這能提供主視頻音軌中沒有提供的重要視覺詳情。這樣的描述能為視覺障礙人士傳達關鍵的視覺內容。
為了評估 MM-Vid 在生成音頻描述方面的有效性,研究者進行了一場用戶研究。他們邀請了 9 位參與者參與評估。其中 4 位參與者失明或視力低下,其余 5 名視力正常。所有參與者聽力都正常。
下面的視頻是 MM-Vid 的音頻描述應用示例:
結果如圖 5 所示,對于以李克特量表計量的參與者總體滿意度(0 = 不滿意到 10 = 非常滿意),MM-Vid 生成的音頻描述平均比人工給出的音頻描述低 2 分。
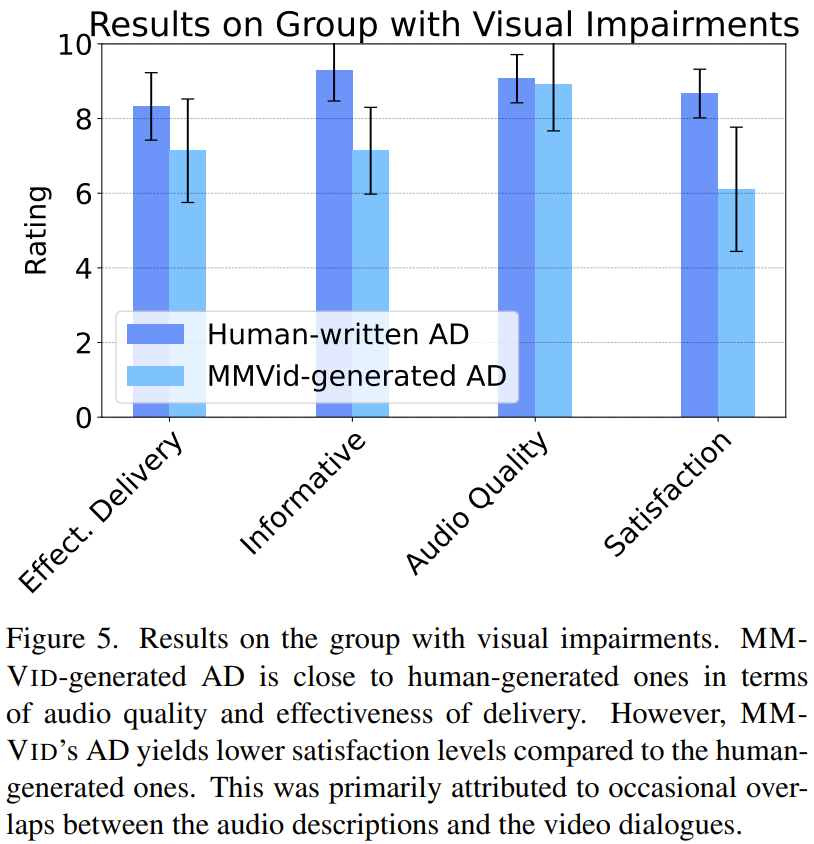
在聽 MM-Vid 生成的音頻描述時,參與者提出的困難包括:1)音頻描述與原始視頻中的對話偶爾重疊,2)由于 GPT-4V 的幻覺問題而出現錯誤描述。盡管總體滿意度有差異,但所有參與者都認同這一點:MM-Vid 生成的音頻描述是一種成本高效且可擴展的解決方案。因此,對于無法被專業人士描述成音頻的大量視頻來說,就可以使用 MM-Vid 這樣的工具來處理它們,從而造福視覺障礙社區。






























