













最強的GPT-4V都考不過?基于大學考試的測試基準MMMU誕生了
目前最好的大型多模態模型 GPT-4V 與大學生誰更強?我們還不知道,但近日一個新的基準數據集 MMMU 以及基于其的基準測試或許能給我們提供一點線索,如下排行榜所示。

看起來,GPT-4V 在一些科目上已經強過掛科的大學生了。當然這個數據集的創造目的并不為了擊敗大學生,而是為了提供一個兼具深度與廣度的多模態 AI 測試基準,助力人工智能系統的開發,尤其是通用人工智能(Artificial General Intelligence,AGI)。
隨著大型語言模型(LLM)快速發展,人們對 AGI 這一頗具爭議的概念進行了廣泛討論。簡單來說,AGI 是指在大多數任務上都與人類相當或超越人類的人工智能系統。由于缺乏公認的可操作定義,人們一直都很難就 AGI 開展更加坦誠和建設性的討論。
為了解決這個問題,Morris 等人的論文《Levels of AGI: Operationalizing Progress on the Path to AGI》提出了一種兼顧通用性(廣度)和性能(深度)的 AGI 分級分類法。
在這種分類法中,第 3 級是專家 AGI,這是一個重要的里程碑。它表示 AI 系統在廣泛的任務上達到了「掌握專業知識的成年人類的 90%」,并由此可以在許多行業中達到「機器智能接替人類勞動力的替代門檻」,從而造成重大的失業風險和經濟混亂。因此,密切關注專家 AGI 的發展情況具有重要的學術和社會意義。
那么,該如何創造用于度量專家 AGI 的基準呢?
由于專家 AGI 的定義是基于與專業人士的比較,因此不同學科的大學水平考試就是一個很好的起點,因為這些考試本身的目的就是評估人類在相應學科的專業能力。MMLU 和 AGIEval 等基準已經成功采用了這一策略,但它們只考慮了基于文本的問題,而人類專家有能力解決多模態問題。
與此同時,能夠理解文本和圖像的大型多模態模型(LMM)已經朝著更通用的人工智能邁出了一大步。這些 LMM 能在現有的多模態基準測試上獲得穩定一致的優良表現。比如 CogVLM 在 VQA-v2 基準上的成績為 85%,在 ScienceQA-IMG 上為 92%,在 RefCOCO 上為 93%。
然而,大多數現有的多模態基準側重于常識 / 日常知識,而不是專家級的領域知識和高級推理。與這個目標最接近的基準是 ScienceQA。盡管 ScienceQA 覆蓋了多個學科(廣度),但其大部分問題都限于小學到初中水平,因此缺乏深度,不足以作為專家 AGI 的基準。
為此,IN.AI Research 等多所機構的一個研究團隊構建了一個新基準 MMMU,可用于評估 AI 在大學水平的多學科問題上的多模態理解和推理能力。

- 論文地址:https://arxiv.org/abs/2311.16502
- 項目網站:https://mmmu-benchmark.github.io/
- 數據集:https://huggingface.co/datasets/MMMU/MMMU
- 代碼:https://github.com/MMMU-Benchmark/MMMU
其中包含的問題來自大學考試、測驗和教科書,涉及六個常見學科:藝術與設計、商科、科學、健康與醫學、人文與社會科學、技術與工程。MMMU 包含 1.15 萬個精心選取的多模態問題,涵蓋 30 個不同的科目和 183 個子領域,因此滿足廣度目標。此外,MMMU 中許多問題都需要專家級的推理能力,比如使用傅立葉變換或均衡理論來推導問題的解,因此也滿足深度目標。

MMMU 還具備了兩個特有挑戰(圖 1):一是其涵蓋多種圖像格式,從照片和繪畫等視覺場景到圖表和表格,可用于測試 LMM 的感知能力;二是 MMMU 具有文本和圖像混合交織的輸入。對于這個基準,AI 模型需要把圖像和文本放在一起理解,這往往需要回憶深度的學科知識并根據理解和知識來執行復雜推理。
該團隊不僅提出了基準,也基于新基準評估了一些模型,其中包括 14 個開源 LMM 和 GPT-4V。他們從中得到了一些有趣的結論。
此外,他們還分析了 GPT-4V 的 150 個錯誤案例,結果發現 35% 的錯誤與感知有關,29% 的錯誤源自缺乏知識、26% 則是由于推理過程的缺陷。這些發現表明 MMMU 是有難度的,可用于助力進一步的研究發展。
MMMU 基準
MMMU 概況
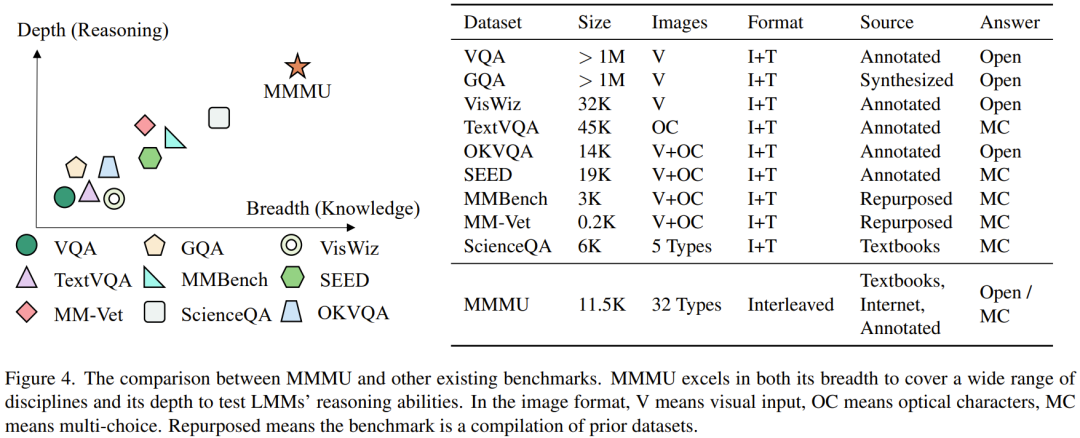
MMMU 是 Massive Multi-discipline Multimodal Understanding and Reasoning 的縮寫,即大規模多學科多模態理解和推理。其構建目標是評估基礎模型在廣泛多樣的任務上的專家級多模態理解能力。MMMU 涉及 6 個學科的 30 個科目。圖 2 給出了每個學科的一個 MMMU 樣本。

圖 3 詳細給出了所覆蓋的科目及相關統計數據。

該基準中的問題是人工收集的,收集者是來自不同學科的 50 位大學生,數據來源包括網絡資源、教科書和課程材料。
如表 1 所示,MMMU 中共有 1.15 萬個問題,并分成了三個子集:少樣本開發集、驗證集和測試集。

少樣本開發集中每個科目包含 5 個問題;驗證集則包含大約 900 個問題,可用于超參數選擇;測試集則有 1.05 萬個問題。MMMU 的設計目標是衡量 LMM 的三項基本技能:感知、知識和推理。
數據的收集和整理過程
數據收集。第一步,他們瀏覽了常見的大學專業,然后確定要將哪些學科包含進該基準中。他們選擇的原則是該學科需要經常采用視覺輸入來提供有價值的信息。基于這個原則,他們去掉了法學和語言學等一些學科,因為這些學科中很難找到足夠多的相關多模態問題。最后,他們從 6 個不同學科中選擇了 30 個科目。
第二步,他們招募了 50 位這些專業的大學生,讓他們作為標注者來幫助收集問題。他們會從專業教科書和網絡資源收集多模態問題,并在有必要時根據自己的專業知識創建新問題。考慮到基礎模型的數據污染問題,標注者會選擇沒有立即可用答案的問題,例如那些答案在不同的文檔中或教科書末尾的問題。這個過程中,他們得到了 1.3 萬個問題。
為了進一步控制數據質量,他們又執行了兩個數據清理步驟。第一步,他們使用了詞匯重疊和來源網址相似度來識別潛在的重復問題。然后他們對這些重復項進行了審查,并清除了所有重復項。第二步則是把這些問題分配給該論文的參與作者,讓他們幫助進行格式和拼寫檢查。最后,該團隊對這些問題進行了難度分級:非常簡單、簡單、中等、困難。其中大約 10% 的問題屬于非常簡單;由于太過簡單,不符合該基準的設計原則,因此被排除在外。
圖 4 給出了 MMMU 與已有基準的差異。
實驗
該團隊基于 MMMU 對多種 LLM 和 LMM 進行了評估。每一種類型都兼顧了閉源和開源模型。評估采用了零樣本設置,以評估模型在沒有微調或少樣本演示的情況下生成準確答案的能力。所有實驗均基于 NVIDIA A100 GPU。
主要結果
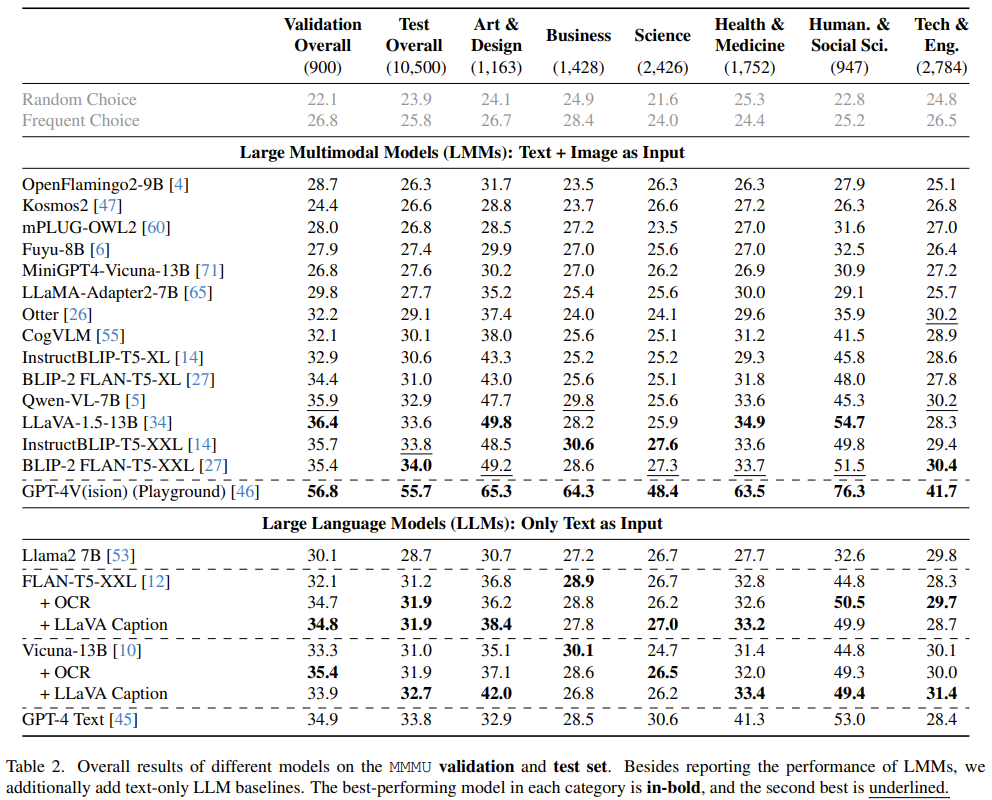
表 2 給出了在 MMMU 基準上不同 LLM 和 LMM 的結果比較。
他們得到了一些重要發現:
- MMMU 難度很大,就連 GPT-4V 的準確度也只有 55.7%,這說明 AI 技術還有很大的改進空間。
- 開源 LMM 和 GPT-4V 的性能差距很大。BLIP2-FLAN-T5-XXL 和 LLaVA-1.5 等表現最好的開源模型也只有 34% 左右的準確度。
- 具備光學字符識別(OCR)或生成字幕的 LLM 沒有看到顯著的提升,這說明 MMMU 需要模型更深度地將圖像和文本放在一起理解。
- 在藝術與設計以及人文與社會科學等視覺數據不太復雜的學科中,模型表現出的性能更高。相比之下,商科、科學、健康與醫學以及技術與工程等領域具有更復雜的視覺數據并需要復雜的推理,因此 AI 模型的性能也相對較低。
但該團隊也指出,MMMU 并不足以對專家 AGI 進行充分的測試,這是受定義限制的,因為模型的 MMMU 性能與「掌握專業知識的成年人類的 90%」之間不存在直接的映射關系,而且大學考試也并非 AGI 理應解決的唯一任務。但他們也認為專家 AGI 有必要在 MMMU 基準上取得好成績,這樣才能體現其掌握知識的廣度和深度以及專家級的理解和推理能力。
對圖像類型和難度的分析
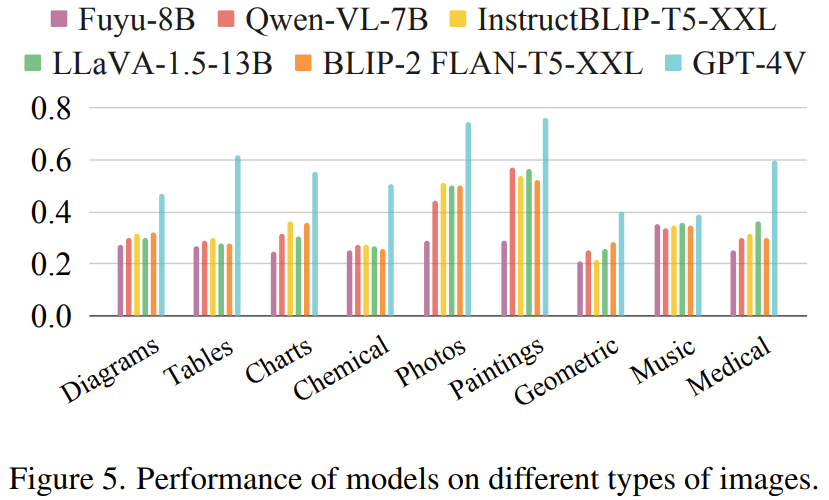
不同的圖像類型。圖 5 比較了在常用的圖像類型上,不同模型的性能。可以看到,在所有類型上,GPT-4V 始終大幅優于其它模型。在照片和繪畫等訓練中更常見的類型上,開源模型的表現相對較好。但是,對于幾何形狀、樂譜和化學結構等更不常見的圖像類別,所有模型的分數都非常低(有些接近于隨機亂猜)。這表明現有模型在這些圖像類型上的泛化性能不佳。
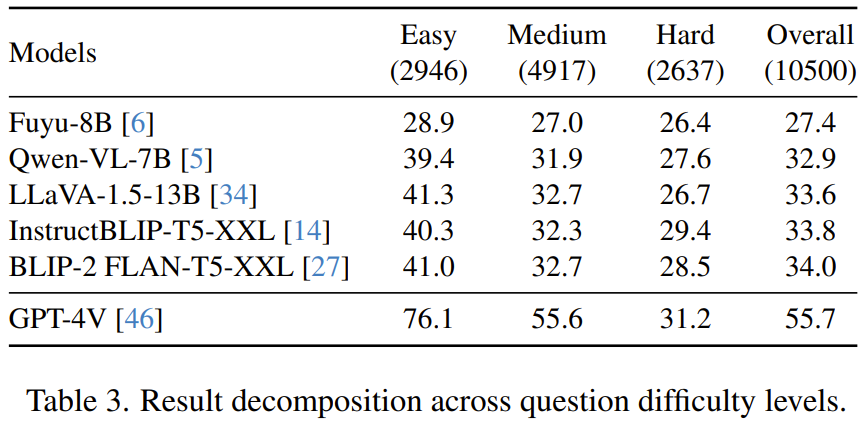
不同難度。表 3 比較了所選模型在三個難度層級上的性能。在「容易」類別中,GPT-4V 的表現顯著優于開源模型,成功率達到了 76.1%。對于「中等」難度類別,差距縮小了,但 GPT-4V 依然領先,為 55.6%。到了「困難」級別,模型的差距進一步變小,這表明隨著任務復雜性的提升,GPT-4V 等更先進模型的優勢會逐漸消失。這可能表明當前模型在處理專家級高難度查詢方面存在局限,即便最先進模型也是如此。
錯誤分析與未來研究
該團隊還深度分析了 GPT-4V 的錯誤,這有助于理解其運作能力和局限。該分析不僅能識別模型當前的缺點,還可以幫助改進未來的設計和訓練。他們從 GPT-4V 的預測中隨機采樣的 150 個錯誤實例,然后請專家級標注者分析了這些實例,這些專家根據自己的知識找到了這些錯誤預測的根本原因。圖 6 給出了這些錯誤的分布情況。

感知錯誤(35%):GPT-4V 的錯誤中很大一部分是感知錯誤,這又可以進一步分為兩種類型:基本感知錯誤和特定領域的感知錯誤。如圖 7 所示,當模型能準確處理和理解給定信息,但無法解讀基本的視覺信息時,就會出現基本感知錯誤。而特定領域的感知錯誤則是由缺乏知識所致。當分析根本原因時,研究者將此類錯誤歸類為缺乏知識。此外,GPT-4V 經常表現出對文本的偏好,也就是以文本信息優先,視覺輸入在后。

缺乏知識(29%):如前所述,對于 GPT-4V 模型,特定領域的感知錯誤的一個基本根本原因就是缺乏專業知識。類似地,缺乏專業知識還可能導致推理出現問題。
推理錯誤(26%):在一些實例中,模型正確解讀了文本和圖像,也找到了相關知識,但卻未能成功應用邏輯和數學推理技能來進行準確的推導。
其它錯誤:其它錯誤還包括文本理解錯誤(6%)、拒絕問答(3%)、注釋錯誤(2%)、答案提取錯誤(1%)。這些錯誤的原因也多種多樣,比如復雜文本的解讀難度大、響應生成的限制、數據注釋不準確以及從較長輸出中提取精確答案存在問題。
更多詳細內容,請閱讀原文。






























