













AI讀心術震撼登頂會!模型翻譯腦電波,人類思想被投屏|NeurIPS 2023
我們今天的AI能做到哪些事情?
AI畫圖、AI作曲、AI生成視頻、AI寫小說、AI做主播......
然而,在最近的NeurIPS大會上,來自GrapheneX-UTS的研究人員帶來了更震撼的應用場景——AI讀心術BrainGPT!

論文地址:https://arxiv.org/pdf/2309.14030v2.pdf
如果AI能知道你心中所想,會發生什么事情?小編可不敢想象。
視頻里研究團隊為大家展示了AI讀心術的現場。
參加測試的人在心中默念一個文本段落,通過一套傳感器采樣腦電波,然后由一個名為DeWave的AI模型,將腦電波翻譯成語言,并投射到屏幕上。
整個過程有點科幻的味道了,尤其是背景音樂,讓小編莫名想到了《星際穿越》。
這項研究被選為今年NeurIPS會議的焦點論文(Spotlight ),研究團隊來自悉尼科技大學的GrapheneX-UTS(以人為本的人工智能中心)。
UTS計算機科學學院杰出教授,兼GrapheneX-UTS HAI中心主任Chin-Teng Lin教授表示,這項研究代表了將原始腦電波直接翻譯成語言的開創性努力,標志著該領域的重大突破。
「這是第一個將離散編碼技術納入腦到文本翻譯過程的方法,引入了一種創新的神經解碼方法,與大型語言模型的集成也為神經科學和人工智能開辟了新的領域。」

——還好還好,需要戴個頭套,AI才能「聽見」人類心里在想什么,這要是能隔空攝取意念可就麻煩了。
如果是小編參加這個測試,估計壓力挺大的,
——畢竟不知道默念文本和心里的想法是不是一回事,AI會不會把我腦袋里的其他想法也順道給讀出來?

小編不由得想起了霍金老前輩,也許在某個平行世界里,他老人家可以用上這樣的一套BrainGPT吧。
而小編我呢?還需要面對著電腦屏幕敲鍵盤嗎?不需要了!小編只需躺在床上,動動腦子,就把這班給上了。
在這項工作中,模型把腦電波信號分割成不同的單元,從中捕獲特定的特征和模式。
DeWave模型通過從大量腦電數據中學習,獲得了將腦電圖信號轉換為單詞和句子的能力。
除了可以幫助因疾病或受傷(中風、癱瘓等)而無法說話的人進行交流,BrainGPT還可以實現人與機器之間的無縫通信,例如仿生手臂或機器人的操作。
以前將大腦信號轉換為語言的技術,要么需要手術在大腦中植入電極(例如馬斯克的Neuralink),要么在MRI機器中掃描。
前者為侵入性,而后者體積大,價格昂貴,且難以在日常生活中使用。
另外,這些方法一般需要眼動追蹤等額外輔助工具,來幫助將大腦信號轉換為單詞級片段,而BrainGPT并沒有這個限制。

這項研究測試了29名參與者。因為腦電波因人而異,所以BrainGPT所表現出的解碼技術更強大、適應性也更強。
當然,比起向大腦植入電極,通過這種外部設備接收到的腦電圖信號會更嘈雜,——不過從翻譯結果來看,準確率也很不錯。
BrainGPT在BLEU-1的翻譯準確率得分,目前約為40%。
(BLEU分數是一個介于0和1之間的數字,用于衡量機器翻譯文本與一組高質量參考翻譯的相似性。)
研究人員認為這套系統將來有望把準確率做到接近90%,——這將是與傳統語言翻譯,或語音識別程序相當的水平。
論文作者認為,目前的模型更擅長匹配動詞,而涉及到名詞時可能不夠精確。這是因為當大腦處理這些單詞時,語義上相似的單詞可能會產生相似的腦電波模式。
論文細節
論文引入了一個新的框架——DeWave,它將離散編碼序列集成到開放詞匯的腦電圖到文本的翻譯任務中。
DeWave使用量化變分編碼器來派生離散的編碼,并將其與預先訓練的語言模型對齊。
這種離散表示有兩個優點:1)通過引入文本-腦電對比對齊訓練,實現了無標記原始波的平移;2)通過不變的離散編碼,減輕了腦電波個體差異引起的干擾。
利用離散編碼,DeWave是第一個實現原始腦電波到文本翻譯的工作,同時引入了自監督波編碼模型,和基于對比學習的腦電到文本對齊,以提高編碼能力。
DeWave模型在使用ZuCo數據集的測試中,BLEU-1分數達到了41.35,Rouge-F分數達到了33.71,比之前的基線分別高出了3.06%和6.34%
另外,論文首次在沒有單詞級順序標記(例如,眼睛注視)的情況下,進行了整個腦電圖信號周期的翻譯測試,分別獲得了20.5(BLEU-1)和29.5(Rouge-1)。
研究方法
DeWave的整個過程如下圖所示,原始EEG特征被矢量化為嵌入的序列,并送到離散的編碼中,語言模型基于離散的編碼表示形式生成翻譯輸出。
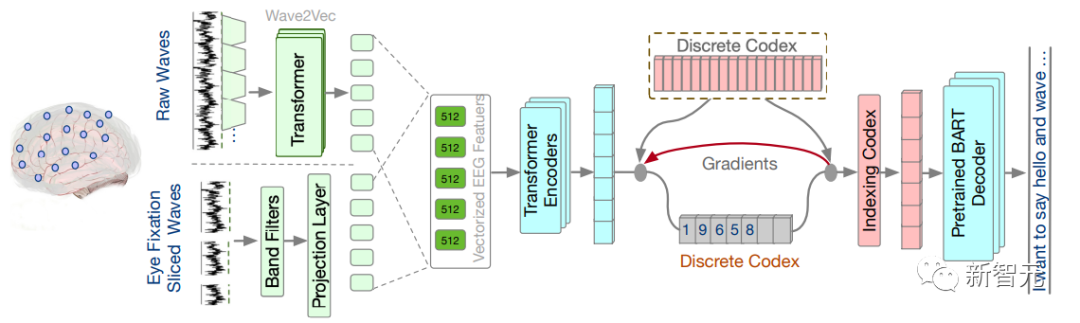
DeWave模型結構涉及將詞級腦電圖特征,或原始腦電圖波矢量化為嵌入,然后將矢量化的特征編碼為一個潛在變量,該變量通過索引轉換為離散的編碼。最后,預先訓練的BART模型將這種離散的編碼表示轉換為文本。
給定一系列單詞級腦電圖特征E,目的是解碼相應的開放詞匯文本標記W。這些腦電圖文本對(E、W)是在自然閱讀期間收集的,
這里設置兩個訓練任務:(1)單詞級腦電圖到文本翻譯,其中腦電圖特征序列E被分割,并根據序列W中的每個單詞的標記,進行重新排序;
(2)原始腦電波到文本翻譯,其中腦電特征序列E直接矢量化為嵌入序列進行翻譯,沒有任何事件標記。
離散編碼
DeWave是第一個將離散編碼引入EEG信號表示的工作。
離散表示有利于詞級腦電圖特征和原始腦電波轉換。將離散編碼引入腦電波可以帶來兩個方面的優勢:
第一點,腦電圖特征在不同人類受試者之間具有很強的數據分布差異。同時,由于數據收集的費用,數據集只能包含來自少數人類受試者的樣本,這嚴重削弱了基于腦電圖的深度學習模型的泛化能力。
而通過引入離散編碼,可以在很大程度上緩解輸入方差。
第二點,編碼包含較少的時間屬性,可以緩解事件標記(如眼睛注視)和語言輸出之間的順序不匹配問題。
腦電圖矢量化
為了得到帶有事件標記的單詞級腦電圖特征,首先根據注釋中給出的單詞序列的眼動追蹤標記,將腦電波切片。
這里計算了4個頻段濾波器的統計結果(Theta波段(5-7Hz)、Alpha波段(8-13Hz)、Beta波段(12-30Hz)和Gamma波段(30Hz-)),得到每個片段的統計頻率特征。
需要注意的是,盡管不同的片段可能具有不同的腦電圖窗口大小,但統計結果是相同的(嵌入大小840)。
應用多頭Transformer層將嵌入投影到大小為512的特征序列中。
使用自監督腦電波編碼器,將原始腦電信號轉換為一系列嵌入:
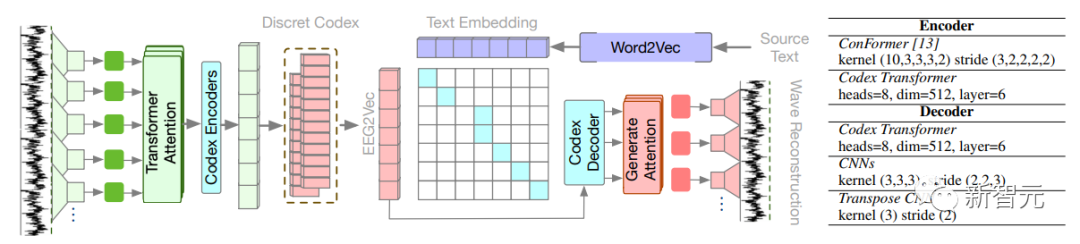
上圖展示了原始波的自監督預訓練過程。左邊的子圖詳細介紹了通過對比學習,利用自我重建和文本對齊來引導編碼器的策略。
這里有兩個指導原則:一個是自我重建,訓練編碼器能力的同時,也從離散編碼中重建原始波形;
另一個是文本對齊,編碼在語義上與詞向量對齊。
在結構方面,采用了基于一致性的多層編碼器,這個編碼器具有專門設計的超參數。
一維卷積層用來處理腦電波以生成嵌入序列,然后將腦電通道融合為每個周期的唯一嵌入。這里將雙向Transformer注意力層應用于序列以捕獲時間關系。
通過這種方式,該模型不僅可以學習重建腦電圖信號,還可以學習與相應文本嵌入一致的信號的魯棒表示。
這種跨模態學習可以彌合腦電圖信號和文本語義內容之間的差距,并改善翻譯系統。
實驗結果
DeWave利用ZuCo 1.0和2.0進行實驗。該數據集同時記錄了正常閱讀(NR)和特定任務閱讀(TSR)任務期間的文本和腦電圖語料庫。
腦電波是用128通道系統,在500Hz的采樣率下通過0.1Hz至100Hz的頻帶濾波器收集的。不過在降噪之后,只有105個通道用于翻譯。
實驗中根據眼睛注視對腦電波進行切片,并計算頻率特征。對于原始腦電波,信號被歸一化為0-1的值范圍以進行解碼。
閱讀任務的數據分別分為訓練(80%)、發展(10%)和測試(10%),句子數量分別為10874、1387和1387個,沒有交集。
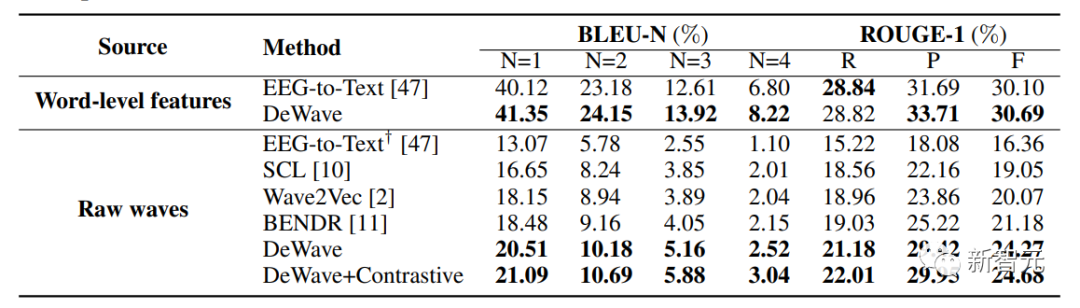
這里使用NLP指標BLEU和ROUGE評估翻譯性能,如上表所示。
對于單詞級腦電圖特征,將結果與腦電圖轉文本進行比較,以保持一致的語言模型。
在缺乏原始腦電波的方法的情況下,通過使用200毫秒的時間窗口和100毫秒的重疊,將整個腦電波分割成序列嵌入,來建立基線(腦電圖到文本)。
實驗中將最初為語音識別開發的Wave2Vec改編為腦電波,并將其與DeWave進行比較。
此外,實驗還采用無監督的原始腦電波分類方法BENDR和SCL,使用SSL預訓練和特征提取進行比較,強調了離散編碼的影響。
因為跨學科性能對于實際應用至關重要,所以這里進一步提供了與基線方法,和具有代表性的元學習方法MAML的比較。

上表展示了18 名人類受試者的平均表現,指標越低越好。我們可以看出DeWave模型在兩種設置(直接測試和使用MAML)中都顯示出卓越的性能。
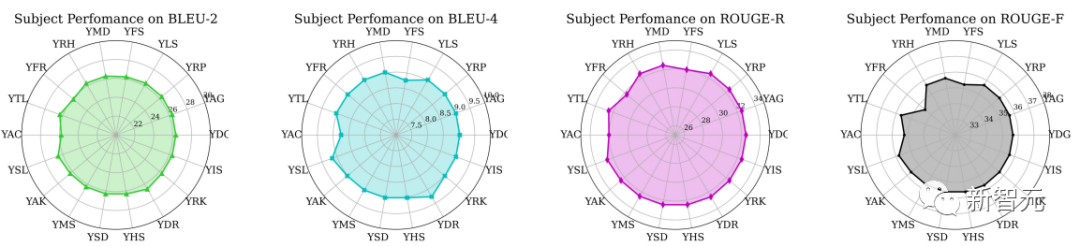
為了進一步說明不同受試者的表現差異,這里僅使用受試者YAG的數據來訓練模型,并測試所有其他受試者的指標。
結果如上圖所示,我們可以從雷達圖中看出,對于不同受試者,模型的表現比較穩定。
























