













數據閉環!DrivingGaussian:逼真環視數據,駕駛場景重建SOTA
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
寫在前面&筆者的個人理解
北大王選計算機研究所的最新工作,提出了DrivingGaussian,一個高效、有效的動態自動駕駛場景框架。對于具有移動目標的復雜場景,首先使用增量靜態3D高斯對整個場景的靜態背景進行順序和漸進的建模。然后利用復合動態高斯圖來處理多個移動目標,分別重建每個目標,并恢復它們在場景中的準確位置和遮擋關系。我們進一步使用激光雷達先驗進行Gaussian splatting,以重建具有更大細節的場景并保持全景一致性。DrivingGaussian在驅動場景重建方面優于現有方法,能夠實現高保真度和多攝像機一致性的真實感環視視圖合成。
開源鏈接:https://pkuvdig.github.io/DrivingGaussian/
總結來說,DrivingGaussian的主要貢獻如下:
- 據我們所知,DrivingGaussian是第一個基于復合Gaussian splatting的大規模動態駕駛場景的表示和建模框架。
- 引入了兩個新模塊,包括增量靜態三維高斯圖和復合動態高斯圖。前者逐步重建靜態背景,而后者用高斯圖對多個動態目標進行建模。在LiDAR先驗的輔助下,該方法有助于在大規模駕駛場景中恢復完整的幾何圖形。
- 綜合實驗表明,DrivingGaussian在挑戰自動駕駛基準方面優于以前的方法,并能夠模擬各種下游任務的corner case。
聊一聊相關工作
NeRF用于邊界場景。用于新視圖合成的神經渲染的快速進展受到了極大的關注。神經輻射場(NeRF)利用多層感知器(MLP)和可微分體素渲染,可以從一組2D圖像和相應的相機姿態信息中重建3D場景并合成新的視圖。然而,NeRF僅限于有邊界的場景,需要中心目標和攝影機之間保持一致的距離。它也很難處理用輕微重疊和向外捕捉方法捕捉的場景。許多進步擴展了NeRF的功能,導致訓練速度、姿態優化、場景編輯和動態場景表示顯著提高。盡管如此,將NeRF應用于大規模無邊界場景,如自動駕駛情景,仍然是一個挑戰。
無邊界場景的NeRF。對于大規模無界場景,一些工作引入了NeRF的精細版本來對多尺度城市級靜態場景進行建模。然而,這些方法在假設場景保持靜態的情況下對場景進行建模,并在有效捕捉動態元素方面面臨挑戰。
同時,以前基于NeRF的方法高度依賴于精確的相機位姿。在沒有精確位姿的情況下,能夠從動態單目視頻中進行合成。然而,這些方法僅限于前向單目視點,并且在處理來自周圍多相機設置的輸入時遇到了挑戰。
由上述基于NeRF的方法合成的視圖的質量在具有多個動態目標和變化以及照明變化的場景中惡化,這是由于它們依賴于射線采樣。此外,激光雷達的利用僅限于提供輔助深度監督,其在重建中的潛在好處,如提供幾何先驗,尚未得到探索。
為了解決這些限制,我們使用復合Gaussian splatting來對無界動態場景進行建模,其中靜態背景隨著自車輛的移動而逐步重建,多個動態目標通過高斯圖建模并集成到整個場景中。激光雷達被用作高斯的初始化,提供了更準確的幾何形狀先驗和全面的場景描述,而不僅僅是作為圖像的深度監督。
3D Gaussian Splatting。最近的3DGaussian splatting(3D-GS)用許多3D高斯對靜態場景進行建模,在新的視圖合成和訓練速度方面實現了最佳結果。與之前的顯式場景表示(例如,網格、體素)相比,3D-GS可以用更少的參數對復雜形狀進行建模。與隱式神經渲染不同,3D-GS允許使用基于splat的光柵化進行快速渲染和可微分計算。
Dynamic 3D Gaussian Splatting。最初的3D-GS是用來表示靜態場景的,一些研究人員已經將其擴展到動態目標/場景。給定一組動態單目圖像,
在真實世界的自動駕駛場景中,數據采集平臺的高速移動會導致廣泛而復雜的背景變化,通常由稀疏視圖(例如2-4個視圖)捕獲。此外,具有強烈空間變化和遮擋的快速移動動態目標使情況進一步復雜化。總的來說,這些因素對現有方法提出了重大挑戰。
詳解DrivingGaussian
Composite Gaussian Splatting
3D-GS在純靜態場景中表現良好,但在涉及大規模靜態背景和多個動態目標的混合場景中具有顯著的局限性。如圖2所示,我們的目標是用無界靜態背景和動態目標的復合Gaussian splatting來表示周圍的大型駕駛場景。

增量靜態3D高斯。駕駛場景的靜態背景由于其大規模、長持續時間以及隨著自車輛運動和多相機變換的變化而帶來的挑戰。隨著自我載體的移動,靜態背景經常發生時間上的變化。由于透視原理,從遠離光流的時間步長預先融入遠處的街道場景可能會導致尺度混亂,導致令人不快的偽影和模糊。為了解決這個問題,我們通過引入增量靜態3D高斯來增強3D-GS,利用車輛運動帶來的視角變化和相鄰幀之間的時間關系,如圖3所示。

具體來說,我們首先基于LiDAR先驗提供的深度范圍,將靜態場景均勻地劃分為N個bin。這些bin按時間順序排列,其中每個bin來自一個或多個時間步長的多目圖像。對于第一個bin內的場景,我們使用LiDAR先驗初始化高斯模型(類似地適用于SfM點):
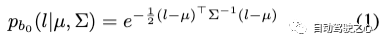
對于隨后的bin,我們使用來自前一個bin的高斯作為位置先驗,并根據相鄰bin的重疊區域對齊相鄰bin。每個bin的3D中心可以定義為:
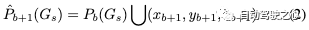
迭代地,我們將后續bin中的場景合并到先前構建的高斯模型中,并將多個周圍幀作為監督。增量靜態高斯模型Gs可以定義為:
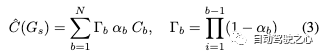
請注意,在靜態高斯模型的增量構建過程中,前后相機對同一場景的采樣可能存在差異。為了解決這個問題,我們在3D高斯投影期間使用加權平均來盡可能準確地重建場景的顏色:

復合動態高斯圖。自動駕駛環境高度復雜,涉及多個動態目標和時間變化。如圖3所示,由于自車輛和動態目標的運動,通常從有限的視圖(例如2-4視圖)觀察目標。高速還導致動態目標的顯著空間變化,這使得使用固定的高斯表示它們具有挑戰性。
為了應對這些挑戰,我們引入了復合動態高斯圖,可以在大規模、長期的駕駛場景中構建多個動態目標。我們首先從靜態背景中分解動態前景目標,使用數據集提供的邊界框來構建動態高斯圖。動態目標通過其目標ID和相應的出現時間戳來識別。此外,Segment Anything模型用于基于邊界框范圍的動態目標的精確像素提取。
然后,我們將動態高斯圖構建為:
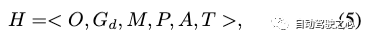
在這里,我們分別為每個動態目標計算高斯。使用變換矩陣mo,我們將目標o的坐標系變換為靜態背景所在的世界坐標:

在優化了動態高斯圖中的所有節點后,我們使用復合高斯圖將動態目標和靜態背景相結合。根據邊界框的位置和方向,按時間順序將每個節點的高斯分布連接到靜態高斯場中。在多個動態目標之間發生遮擋的情況下,我們根據與攝影機中心的距離調整不透明度:根據光傳播原理,距離越近的目標不透明度越高:
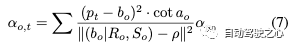
最后,包括靜態背景和多個動態目標的復合高斯場可以公式化為:

LiDAR Prior with surrounding views
基元3D-GS試圖通過structure-from-motion(SfM)來初始化高斯。然而,用于自動駕駛的無邊界城市場景包含許多多尺度背景和前景。盡管如此,它們只是通過極其稀疏的視圖才能瞥見,導致幾何結構的錯誤和不完整恢復。
為了為高斯提供更好的初始化,我們在3D高斯之前引入了激光雷達,以獲得更好的幾何形狀,并在環視視圖配準中保持多相機的一致性。在每個時間步長,給定從移動平臺和多幀激光雷達掃描Lt收集的一組多相機圖像。我們的目標是使用激光雷達圖像多模態數據最小化多相機配準誤差,并獲得準確的點位置和幾何先驗。
我們首先合并多幀激光雷達掃描,以獲得場景的完整點云,并從每個圖像中單獨提取圖像特征。接下來,我們將激光雷達點投影到環視的圖像上。對于每個激光雷達點,我們將其坐標變換到相機坐標系,并通過投影將其與相機圖像平面的2D像素匹配:

值得注意的是,來自激光雷達的點可能被投影到多個圖像的多個像素上。因此,我們選擇到圖像平面的歐幾里得距離最短的點,并將其保留為投影點,指定顏色。
與以往的三維重建工作類似,我們將密集束平差(DBA)擴展到多相機設置,并獲得更新的激光雷達點。實驗結果證明,在與周圍的多目對準之前用激光雷達進行初始化有助于為高斯模型提供更精確的幾何先驗。
Global Rendering via Gaussian Splatting
本文采用可微3DGaussian splatting渲染器,并將全局復合3D高斯投影到2D中,其中協方差矩陣由下式給出:

復合高斯場將全局3D高斯投影到多個2D平面上,并在每個時間步長使用環視視圖進行監督。在全局渲染過程中,下一個時間步長的高斯最初對當前圖像不可見,隨后與相應全局圖像的監督相結合。
我們的方法的損失函數由三個部分組成。接下來,我們首先將tile結構相似性(TSSIM)引入Gaussian Splatting,它測量渲染的tile與對應的GT之間的相似性。

我們還引入了用于減少3D高斯中異常值的魯棒損失,其可以定義為:

通過監督激光雷達的預期高斯位置,進一步利用激光雷達損失,獲得更好的幾何結構和邊緣形狀:
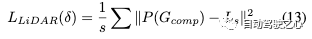
實驗結果
如表1所示,我們的方法在很大程度上優于Instant-NGP,后者使用基于哈希的NeRF進行新的視圖合成。Mip-NeRF和MipNeRF360是針對無界戶外場景設計的兩種方法。我們的方法在所有評估指標中也顯著超過了它們。

KITTI-360單視圖合成的比較。為了進一步驗證我們的方法在單目駕駛場景設置上的有效性,我們對KITTI-360數據集進行了實驗,并將其與現有的SOTA方法進行了比較。如表2所示,我們的方法在單目駕駛場景中表現出最佳性能,大大超過了現有方法。補充材料中提供了更多的結果和視頻。

消融實驗
Gaussians的初始化先驗。通過對比實驗分析了不同先驗和初始化方法對高斯模型的影響。原始3D-GS提供了兩種初始化模式:隨機生成點和COLMAP計算的SfM點。我們還提供了另外兩種初始化方法:從預先訓練的NeRF模型導出的點云和使用LiDAR先驗生成的點。
同時,為了分析點云數量的影響,我們將激光雷達下采樣到600K,并應用自適應濾波(1M)來控制生成的激光雷達點的數量。我們還為隨機生成的點(600K和1M)設置了不同的最大閾值。這里,SfM-600K±20K表示COLMAP計算的點數,NeRF-1M±20K代表預訓練的NeRF模型生成的總點數,LiDAR-2M±20K代表LiDAR點的原始數量。

如表3所示,隨機生成的點會導致最差的結果,因為它們缺乏任何幾何先驗。由于點稀疏和無法容忍的結構誤差,用SfM點初始化也不能充分恢復場景的精確幾何結構。利用從預先訓練的NeRF模型生成的點云提供了相對準確的幾何先驗,但仍存在明顯的異常值。對于用LiDAR先驗初始化的模型,盡管下采樣會導致一些局部區域的幾何信息丟失,但它仍然保留了相對準確的結構先驗,從而超過了SfM(圖5)。我們還可以觀察到,實驗結果不會隨著激光雷達點數量的增加而線性變化。我們推斷這是因為過密的點存儲了冗余特征,干擾了高斯模型的優化。

每個模塊的有效性。我們分析了每個提出的模塊對最終性能的貢獻。如表4所示,復合動態高斯圖模塊在重建動態駕駛場景中發揮著至關重要的作用,而增量靜態3D高斯圖模塊能夠實現高質量的大規模背景重建。這兩個新穎的模塊顯著提高了復雜駕駛場景的建模質量。關于所提出的損失函數,結果表明,和都顯著提高了渲染質量,增強了紋理細節并消除了偽影。在LiDAR先驗的幫助下,幫助高斯獲得更好的幾何先驗。實驗結果還表明,即使沒有激光雷達先驗,DrivingGaussian也能很好地執行,對各種初始化方法表現出強大的魯棒性。

Corner Case仿真
進一步展示了我們在真實駕駛場景中模擬Corner Case的方法的有效性。如圖6所示,我們可以將任意動態對象插入重建的高斯場中。模擬場景主要具有時間一致性,并在多個傳感器之間表現出良好的傳感器間一致性。我們的方法能夠對自動駕駛場景進行可控的模擬和編輯,促進安全自動駕駛系統的研究。

總結
本文提出了DrivingGaussian,這是一種基于所提出的復合高斯Splatting的用于表示大規模動態自動駕駛場景的新框架。DrivingGaussian使用增量靜態3D高斯逐步對靜態背景進行建模,并使用復合動態高斯圖捕獲多個運動目標。我們進一步利用激光雷達先驗來獲得精確的幾何結構和多視圖一致性。DrivingGaussian在兩個著名的驅動數據集上實現了最先進的性能,允許高質量的周圍視圖合成和動態場景重建。

原文鏈接:https://mp.weixin.qq.com/s/pGwIbrgvmbScyNKNbZLE1w






























