













中文性能反超VLM頂流GPT-4V,阿里Qwen-VL超大杯限免!看圖秒寫編程視覺難題一眼辨出
最近,通義千問實火。
前段時間被網友玩瘋的全民舞王,讓「AI科目三」頻頻登上熱搜。
讓甄嬛、慈禧、馬斯克、貓主子和兵馬俑能跳舞那款AI,就藏在通義千問APP背后。

來源:深夜來點薯片

來源:深夜來點薯片
最強國產視覺語言模型了解一下
就在這幾天,通義千問團隊又對多模態(tài)大模型下手了——
再一次升級通義千問視覺語言模型Qwen-VL,繼Plus版本之后,又推出Max版本。
Qwen-VL是阿里在2023年8月推出的具備圖文理解能力的大模型,基于通義千問語言模型開發(fā)。升級后的Qwen-VL視覺水平大幅提升,對很多圖片的理解水平接近人類。
并且,還能夠支持百萬像素以上的高清分辨率圖,以及各種極端長寬比的圖片。
升級版模型限時免費,在通義千問官網和APP都可體驗,API也可免費調用。
評測結果顯示,Qwen-VL的升級版本在MMMU、MathVista等任務上遠超業(yè)界所有開源模型,在文檔分析(DocVQA)、中文圖像相關(MM-Bench-CN)等任務上超越GPT-4V,達到世界最佳水平。

在第三方權威評測上,Qwen-VL常常與GPT-4V、Gemini攜手占據(jù)業(yè)界三強,與其他競爭者拉開相當大的差距。

來源:OpenCompass
話不多說,小編立馬展開實測。
多模態(tài)基礎能力
首先,我們直接來了一道難度拉滿的題——一張小編十年前在雪鄉(xiāng)拍的照片。
Qwen-VL-Max不僅一眼認了出來,而且還配上了一段非常優(yōu)美的描寫:
房屋上覆蓋著厚厚的積雪,像是童話里的小木屋。太陽剛剛升起,給雪地和房屋染上了一層溫暖的色彩。遠處的山巒和森林也籠罩在淡黃色的晨光中,整個場景顯得寧靜而祥和。

而GPT-4V則表示,由于沒有具體的地標,因此無法給出確切的位置。

接下來,Qwen-VL-Max不僅數(shù)對了難倒GPT-4V的「數(shù)數(shù)幾個葫蘆娃」問題。

而且還通關了經典的計算機視覺難題——「吉娃娃與松餅」。

類似的「毛巾卷和沙皮狗」、「柯基屁股與土司」等等,也能順利答出。


甚至它還可以理解「給吉娃娃套上吐司」這樣惡搞的圖片。

對于在一張圖里分別辨認多個名人這類問題,Qwen-VL-Max同樣能夠立刻給出正確的回答。
比如剛剛當選ACM Fellow的圖靈三巨頭。

以及科技圈的一眾大佬。


同樣,它也可以精準識別出圖像中的文字,即便是手寫體也不在話下。

相比之下,GPT-4V卻未能識別對圖中毛筆寫的字,而是給出了「恭賀新禧大吉大利」。

有趣的是,Qwen-VL-Max還能根據(jù)自己對圖像的理解寫詩。
比如這首根據(jù)「權力的游戲」中的名場面作的中文詩,就頗有意境。

而根據(jù)同一個場景作出的英文詩,也很有韻致。

視覺Agent能力
除了基礎的描述和識別能力外,Qwen-VL-Max還具備視覺定位能力,可以針對畫面指定區(qū)域進行問答。
比如它能在一群貓貓中準確框出黑貓。

還能在吉娃娃和松餅中框出吉娃娃。

我們標出OpenAI聯(lián)創(chuàng)Karpathy帖子中的一個圖,問Qwen-VL-Max標出的部分是什么意思。

它立馬給出的正確回答:標出的部分是流程圖,展現(xiàn)了AlphaCodium的代碼生成過程。同時還給出了正確的描述。

關鍵信息提取處理
在實測中我們發(fā)現(xiàn),Qwen-VL-Max最顯著的進步之一,就是基于視覺完成復雜的推理。
這不僅限于描述內容,而是能理解復雜的表達形式。
比如,下面這道看似簡單初中幾何題,由于條件信息都被嵌入進了圖像里的,其實難倒了不少視覺模型:


相比之下,Qwen-VL-Max直接給出了正確解答。

上下滑動查看
再比如解釋下圖中的算法流程圖。

Qwen-VL-Max會清晰地給出整套流程的解釋,包括每一步之后需要進行的步驟。

小朋友的編程題,它也能正確地理解圖中的流程,轉換成Python程序。


import random
# 初始化變量
my_number = random.randint(1, 10)
guess = None
# 猜數(shù)字循環(huán)
while guess != my_number:
guess = int(input("Guess a number between 1 and 10: "))
if guess > my_number:
print("Too high!")
elif guess < my_number:
print("Too low!")
print("You got it!")直接給圖表,Qwen-VL-Max就能對之做出深入分析和解讀。
論文中多復雜的圖表,它都能瞬間幫我們整理成表格的形式,簡潔直觀。


下方的圖形推理題,它能準確推測出圖四應該是星星中有一個點的圖形。

文本信息識別處理
這次,迭代后的Qwen-VL-Plus/Max處理圖像中的文本的能力也顯著提升,尤其是中文和英文文本。
模型可以有效地從表格和文檔中提取信息,并將這些信息重新格式化。
比如,隨手拍一張鋪滿字的藥品說明書圖片上傳,要求它按規(guī)范格式輸出文字。

Qwen-VL-Max不僅可以準確識別出圖片中文字,還可以將圖中【】同步出來。

甚至下面這種寫滿筆記而且還存在遮蓋的掃描版文檔,也能識別出來。

Qwen-VL碾壓同級大模型,AI社區(qū)盛贊
通義千問在多種復雜視覺任務上的表現(xiàn)著實讓人驚艷,背后的技術架構是怎樣的?
早在去年8月,團隊就開源了基于Qwen-7B和ViT-G的Qwen-VL。

論文地址:https://arxiv.org/abs/2308.12966
不同于直接使用視覺語言下游任務數(shù)據(jù)集進行對齊,團隊在訓練初代Qwen-VL時設計了一種三階段的訓練方法。

階段一:預訓練——將視覺編碼器與凍結LLM對齊
因為訓練數(shù)據(jù)規(guī)模不足,可能導致任務泛化性能較差,所以使用大量的弱監(jiān)督圖像文本對數(shù)據(jù)(如LAION-5B)進行對齊。
與此同時,為了保留LLM的理解和生成能力,還需凍結LLM。
階段二:多任務預訓練——賦予Qwen-VL完成多樣下游任務的能力
讓LLM在視覺問答、圖像描述生成(Image Caption)、OCR、視覺定位(Visual Grounding)等各種任務上完成預訓練。
這里,直接用文字坐標表示位置,因此LLM能夠自然地輸出關注元素的位置信息。
階段三:監(jiān)督微調——將視覺語言模型與人類偏好對齊
收集并構造了一組多樣化的SFT樣本,對視覺語言模型進行了初步的對齊處理。
可以看到,在主流多模態(tài)任務評測和多模態(tài)聊天能力評測中,Qwen-VL都取得同期遠超同等規(guī)模通用模型的表現(xiàn)。

Qwen-VL模型開源后,在AI社區(qū)受到了廣泛的好評和推薦。
有網友感慨道,人工智能的下一次進化來了!Qwen-VL模型巧妙地融合了視覺+文本推理,推進了多模態(tài)人工智能發(fā)展。

還有網友表示,通義千問團隊的工作非常出色和認真,尤其是新發(fā)布的版本,絕對優(yōu)秀。

當然,全新迭代后的Qwen-VL-Plus性能更是大幅提升,網友紛紛開啟測試。
比如有人發(fā)現(xiàn)Qwen-VL-Plus竟通過了自己的「蘑菇測試」(識別圖片中某個特定種類的蘑菇),他表示「這是第二個開源VLM模型通過這項測試」。

還有人將Qwen-VL-Plus與ChatGPT進行了對比,通義千問模型的回答更加讓人印象深刻。

AI下一個爆點:多模態(tài)視覺語言模型
2023,是大語言模型的爆發(fā)年。
在LLM之后,下一個爆發(fā)的賽道會在哪里?
很多人認為,是多模態(tài)。能否實現(xiàn)AGI,或許關鍵就在這里。
「多模態(tài)模型將成為AI時代下一爆點」這個論斷,也得到了業(yè)界眾多AI大佬的背書。
OpenAI開發(fā)者關系主管Logan Kilpatrick曾在AI Engineer峰會上表示,「2024年將是多模態(tài)模型年」。
最近HuggingFace的研究工程師在Latent Space播客采訪中更進一步預測,2年內所有的LLM都將變成LMM。

Meta公共政策專家對2024年AI預測,稱「LMM將不斷涌現(xiàn),并在多模態(tài)評估、多模態(tài)安全、多模態(tài)這個、多模態(tài)那個的爭論中取代LLM。此外,LMM是邁向真正通用人工智能助手的墊腳石」。

對此,圖靈獎巨頭LeCun也表示贊同。

過去一年中,許多人見證了多模態(tài)大模型發(fā)展的重要里程碑。
從LLaVa、Imagebind、Flamingo,到GPT-4V、Gemini等大模型誕生,徹底改變了AI系統(tǒng)理解多種形式的數(shù)據(jù),并與之交互的方式。
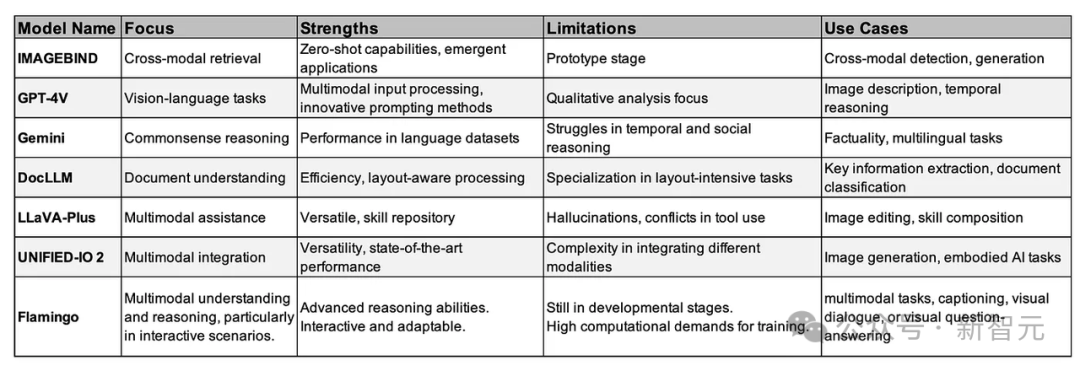
在多模態(tài)大模型賽道上,國內頭部科技公司阿里也在一直布局探索。
2021年推出M6系列預訓練-微調模式,到2022年發(fā)布圖文模態(tài)任務統(tǒng)一的通用模型OFA系列,再到OFA-Sys的系統(tǒng)化AI學習的嘗試。
2023年通義千問大模型問世后,8月底阿里團隊基于Qwen-7B打造的視覺理解大模型Qwen-VL正式開源。
11月,阿里又開源了音頻理解大模型Qwen-Audio,同時還升級了Qwen-VL,使之具備通用OCR、視覺推理、中文文本理解基礎能力,還能處理各種分辨率和規(guī)格的圖像。緊接著,就是Qwen-VL-Max的推出。

通義千問團隊表示,他們一直以來都把開發(fā)與人類一樣能聽、能看、能理解、能溝通的「通用AI模型」作為目標。
所有多模態(tài)大模型的迭代更新,最重要的價值就在于與落地應用相融合,重塑各個行業(yè)。
LMM已成為AI企業(yè)關注的重點發(fā)展趨勢,其泛化能力是形成完備的商業(yè)模式的關鍵能力之一。
而最先迎來革新的行業(yè),便是機器人領域。LMM將推動未來家用服務機器人更進一步走進人類生活。
經過過去一年大模型的持續(xù)發(fā)酵,讓許多人看到AI+機器人的廣闊應用前景,這也是為什么許多AI大佬將2024年稱之為「機器人元年」的原因。

比如,谷歌DeepMind團隊升級的RT-2機器人由全新的「視覺語言動作」模型的加持,多了一個動作模態(tài),表現(xiàn)出驚人的學習能力和理解力。

多模態(tài)大模型Gemini發(fā)布后,谷歌DeepMind的首席執(zhí)行官Hassabis同樣表示,「團隊正在研究如何將Gemini與機器人技術相結合,與世界進行物理互動」。
LMM還可以通過醫(yī)學影像分析幫助醫(yī)生診斷疾病,并幫助醫(yī)生解讀醫(yī)學圖像和報告以更快地進行診斷。
前幾天,世界衛(wèi)生組織(WHO)還發(fā)布了全新指南,概述了多模態(tài)大模型在醫(yī)療衛(wèi)生領域的五大應用場景:診斷和臨床護理、患者自主使用、文書和行政工作、醫(yī)療和護理教育、科學研究和藥物研發(fā)。

另外,在教育領域,LMM的應用也是比比皆是。
比如GPT-4加持的可汗學院AI機器人Khanmio能夠為學生提供個性化輔導,還有專注數(shù)學的WolframAlpha能夠生成可視化的解題步驟。
未來,多模態(tài)大模型通過結合文本、圖像和音頻,能夠創(chuàng)造更加身臨其境的學習體驗。

多模態(tài)大模型無縫集成了文本、圖像、音頻不同的模態(tài),將會為醫(yī)療保健、教育、藝術和個性化推薦領域的變革性應用打開了大門。
綜上,我們可以得到這樣一個結論——LMM是人工智能的未來,更是邁向人工通用智能的墊腳石。
顯然,阿里正在走一條非常正確的路。






























