一統(tǒng)所有目標感知任務,華科&字節(jié)提出目標感知基礎模型GLEE
近年來,LLM 已經(jīng)一統(tǒng)所有文本任務,展現(xiàn)了基礎模型的強大潛力。一些視覺基礎模型如 CLIP 在多模態(tài)理解任務上同樣展現(xiàn)出了強大的泛化能力,其統(tǒng)一的視覺語言空間帶動了一系列多模態(tài)理解、生成、開放詞表等任務的發(fā)展。然而針對更細粒度的目標級別的感知任務,目前依然缺乏一個強大的基礎模型。

為了解決這個問題,來自華中科技大學和字節(jié)跳動的研究團隊提出了一個針對視覺目標的基礎模型 GLEE,一次性解決圖像和視頻中的幾乎所有目標感知任務。GLEE 支持根據(jù)任意開放詞表、目標的外觀位置描述、和多種交互方式進行目標檢測、分割、跟蹤,并在實現(xiàn)全能性的同時保持 SOTA 性能。
此外,GLEE 還構(gòu)建了統(tǒng)一優(yōu)化目標的訓練框架,從超過一千萬的多源數(shù)據(jù)中汲取知識,實現(xiàn)對新數(shù)據(jù)和任務的零樣本遷移。并驗證了多種數(shù)據(jù)之間相互促進的能力。模型和訓練代碼已全部開源。

- 論文標題:GLEE: General Object Foundation Model for Images and Videos at Scale
- 論文地址:https://arxiv.org/abs/2312.09158
- 代碼地址:https://github.com/FoundationVision/GLEE
- Demo 地址:https://huggingface.co/spaces/Junfeng5/GLEE_demo
- 視頻地址:https://www.bilibili.com/video/BV16w4m1R7ne/
1. GLEE 可以解決哪些任務?
GLEE 可以同時接受語義和視覺上的 prompt 作為輸入,因此,任意長度的開放詞表、目標屬性描述、目標位置描述都、交互式的 point,box,mask 都可以被作為 prompt 來指引 GLEE 檢測分割出任意目標。具體來說,開放世界的目標檢測、實例分割、文本描述的指代檢測與分割(referring expression comprehension and segmentation)以及交互式分割都可以被輕松實現(xiàn)。
此外,通過在超大規(guī)模的圖像數(shù)據(jù)上進行訓練,GLEE 學習到了更加有判別性的目標特征,直接對這些特征進行無參數(shù)的幀間匹配可以實現(xiàn)高質(zhì)量的跟蹤,從而將 GLEE 的能力完全擴展到視頻任務上。在視頻任務中 GLEE 可以實現(xiàn)開放世界的視頻實例分割(VIS),視頻目標分割(VOS),參考視頻實例分割(RVOS)以及交互式的視頻目標分割跟蹤。
2. GLEE 統(tǒng)一了哪些數(shù)據(jù)用來訓練?
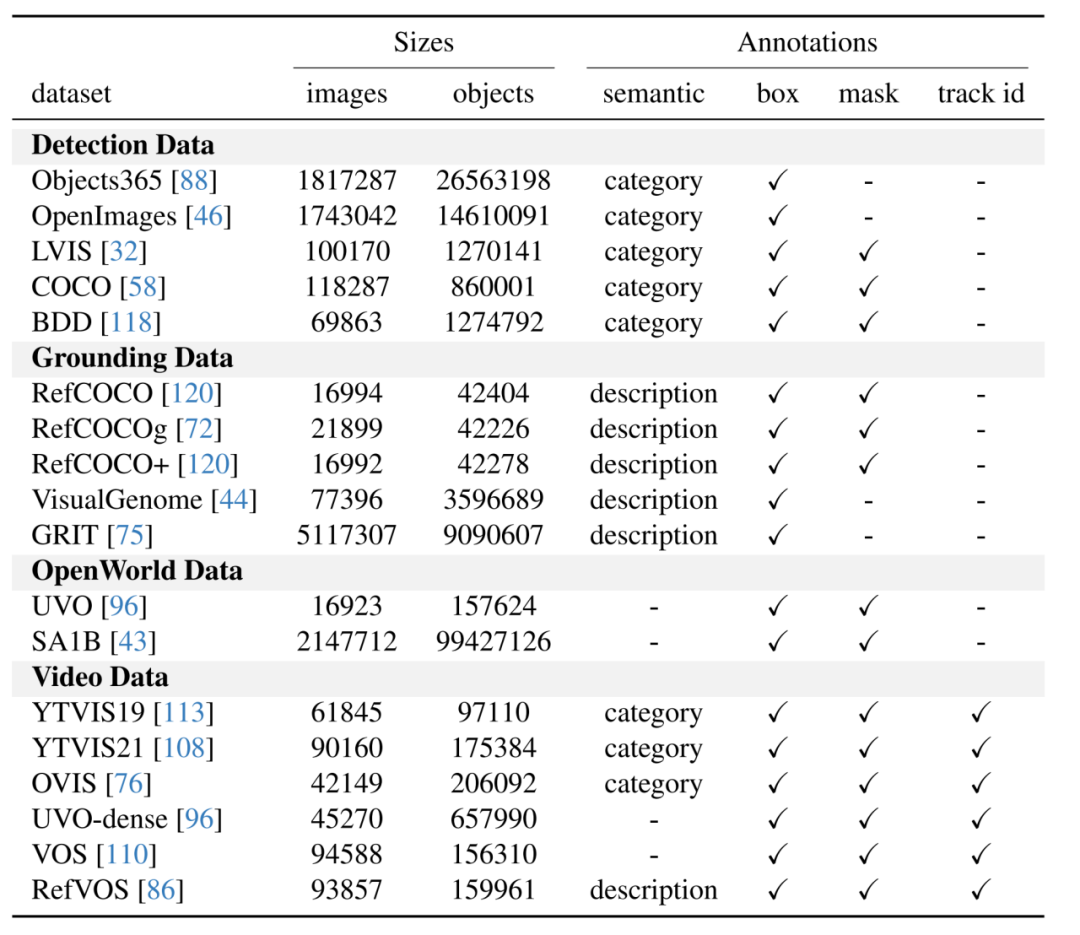
GLEE 使用了來自 16 個數(shù)據(jù)集的超過一千萬圖片數(shù)據(jù)進行訓練,充分利用了現(xiàn)有的標注數(shù)據(jù)和低成本的自動標注數(shù)據(jù)構(gòu)建了多樣化的訓練集,是 GLEE 獲得強大泛化性的根本原因。
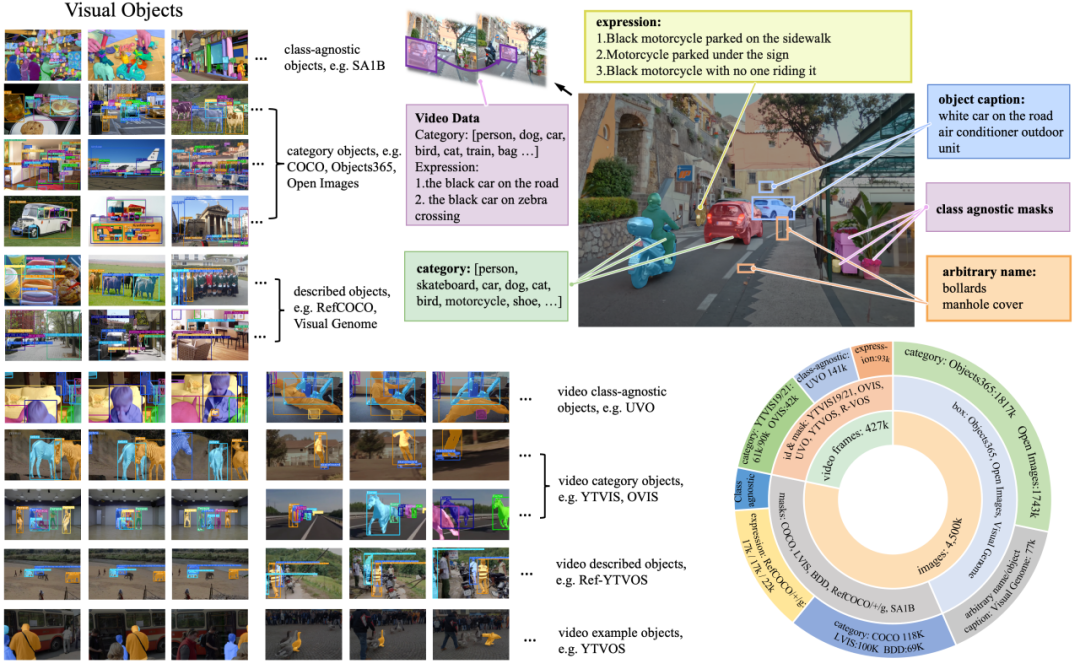
GLEE 使用的數(shù)據(jù)根據(jù)標注類型可以分為四大類:1)基于詞表的目標檢測數(shù)據(jù)集,如 COCO、Objects365。2)基于目標描述的 grounding 數(shù)據(jù)集,如 RefCOCO 系列、VisualGenome。3)無類語義信息的 open-world 數(shù)據(jù)集,如 SA1B、UVO。4)視頻數(shù)據(jù),如 YouTubeVIS、OVIS。GLEE 所使用的圖片超過 1 千萬,其中標注目標數(shù)量超過一億五千萬。
3. GLEE 如何構(gòu)成?
GLEE 包括圖像編碼器、文本編碼器、視覺提示器和目標檢測器,如圖所示。文本編碼器處理與任務相關的任意描述,包括目標類別詞表、目標任何形式的名稱、關于目標的標題和指代表達。視覺提示器將用戶輸入(如交互式分割中的點、邊界框或涂鴉)編碼成目標對象的相應視覺表示。然后,這些信息被整合到一個檢測器中,根據(jù)文本和視覺輸入從圖像中提取對象。
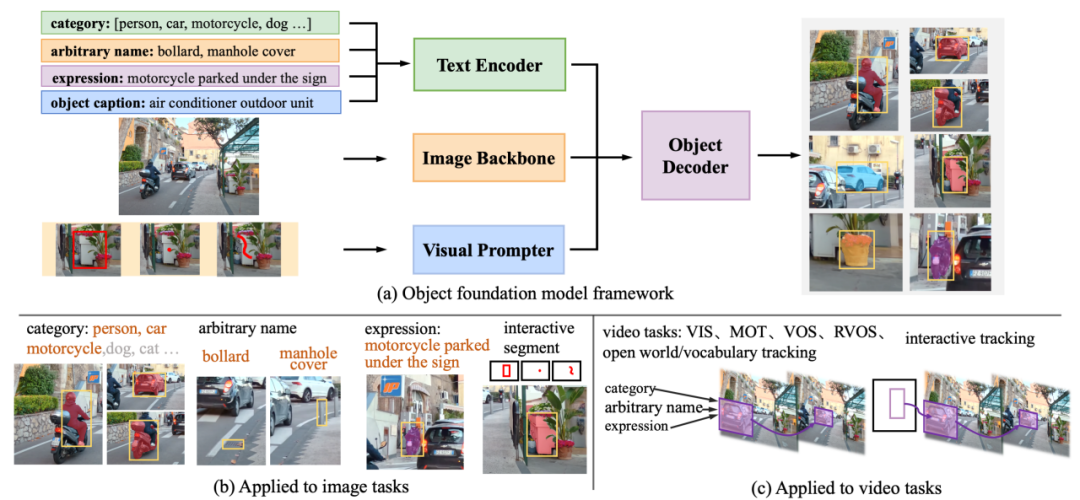
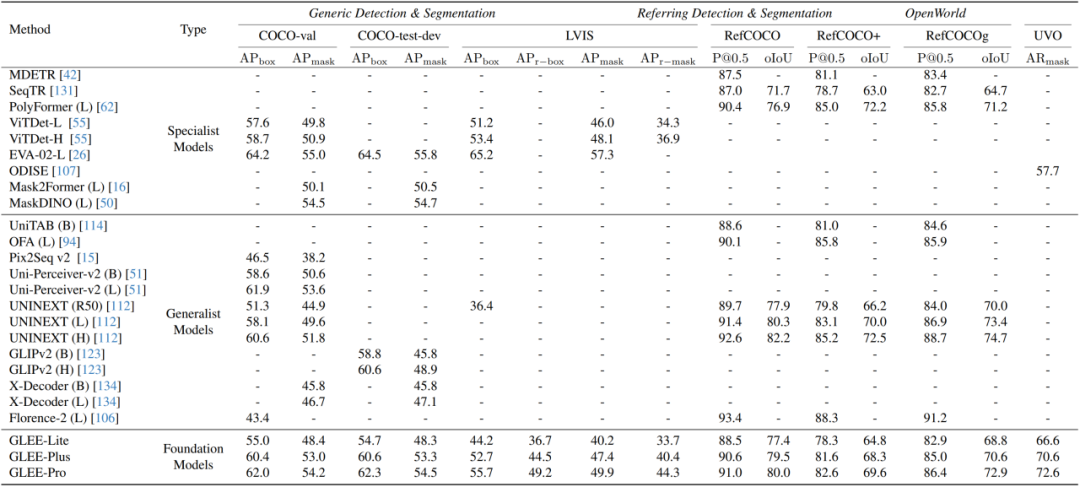
4. 在目標感知任務上的全能性和泛化能力
該研究展示了 GLEE 模型作為一個目標感知基礎模型的普適性和有效性,它可以直接應用于各種以目標為中心的任務,同時確保最先進的性能,無需進行微調(diào)。
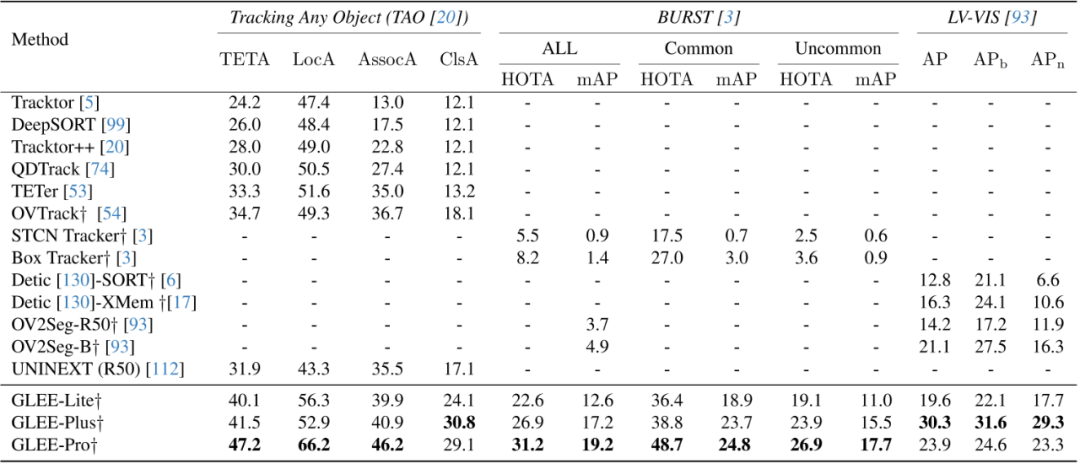
此外,該研究在一些開放詞匯表的視頻任務中驗證了 GLEE 的零樣本泛化能力。在 TAO、BURST、LV-VIS 這三個開放詞匯表的跟蹤數(shù)據(jù)集上,GLEE 在未經(jīng)過訓練和微調(diào)的情況下,取得了令人驚嘆的最先進(SOTA)性能,這證明了 GLEE 在大規(guī)模聯(lián)合訓練中學習到的通用對象感知能力和強大的泛化能力。
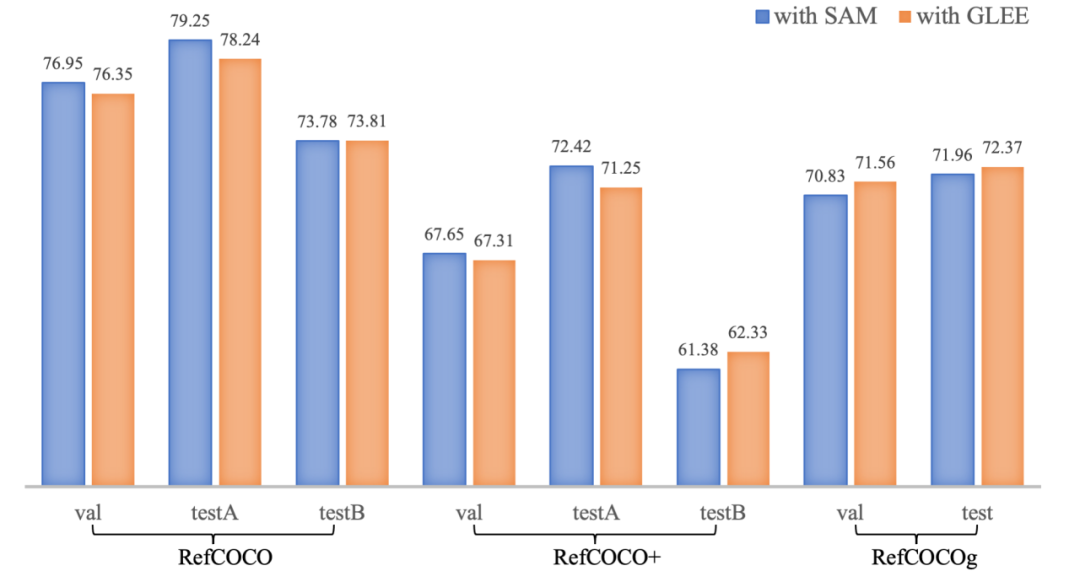
5. 作為基礎模型的潛力
作為基礎模型,該研究用預訓練且凍結(jié)的 GLEE-Plus 替換了 LISA 的中使用的 SAM backbone,并將 GLEE 的 Object Query 輸入到 LLAVA 中,移除了 LISA 的解碼器。該研究直接將輸出的 SEG 標記與 GLEE 特征圖進行點積運算以生成 Mask。在進行相同步數(shù)的訓練后,修改后的 LISA-GLEE 取得了與原版 LISA 使用 SAM 相媲美的結(jié)果,這證明了 GLEE 的表示具有多功能性,并且在為其他模型服務時的有效性。