













生成與理解相互促進(jìn)!華科字節(jié)提出Liquid,揭示統(tǒng)一多模態(tài)模型尺度規(guī)律!
近年來(lái)大語(yǔ)言模型(LLM)的迅猛發(fā)展正推動(dòng)人工智能邁向多模態(tài)融合的新紀(jì)元。然而,現(xiàn)有主流多模態(tài)大模型(MLLM)依賴(lài)復(fù)雜的外部視覺(jué)模塊(如 CLIP 或擴(kuò)散模型),導(dǎo)致系統(tǒng)臃腫、擴(kuò)展受限,成為跨模態(tài)智能進(jìn)化的核心瓶頸。
為此,華中科技大學(xué)、字節(jié)跳動(dòng)與香港大學(xué)聯(lián)合團(tuán)隊(duì)提出了極簡(jiǎn)的統(tǒng)一多模態(tài)生成框架 ——Liquid。Liquid 摒棄了傳統(tǒng)的外部視覺(jué)模塊,轉(zhuǎn)而采用 VQGAN 作為圖像分詞器,將圖像編碼為離散的視覺(jué) token,使其與文本 token 共享同一詞表空間,使 LLM 無(wú)需任何結(jié)構(gòu)修改即可 “原生” 掌握視覺(jué)生成與理解能力,徹底擺脫對(duì)外部視覺(jué)組件的依賴(lài)。研究團(tuán)隊(duì)首次揭示了統(tǒng)一表征下的多模態(tài)能力遵循 LLM 的尺度定律,且視覺(jué)生成與理解任務(wù)可雙向互促,這一發(fā)現(xiàn)為通用多模態(tài)智能的架構(gòu)設(shè)計(jì)提供了新的范式。

- 論文標(biāo)題:Liquid: Language Models are Scalable and Unified Multi-modal Generators
- 論文鏈接:https://arxiv.org/abs/2412.04332
- 主頁(yè)鏈接:https://foundationvision.github.io/Liquid/
背景與貢獻(xiàn)
傳統(tǒng)多模態(tài)大模型(MLLM)普遍依賴(lài)外部視覺(jué)模塊(如 CLIP、擴(kuò)散模型)作為編碼器或解碼器,需通過(guò)特征投影層對(duì)齊視覺(jué)與文本特征,導(dǎo)致架構(gòu)復(fù)雜化。近期一些研究嘗試采用 VQVAE 替代傳統(tǒng)模塊,通過(guò)將原始像素映射為離散編碼,實(shí)現(xiàn)圖像與文本的統(tǒng)一表征。離散視覺(jué) token 可視為一種新 “語(yǔ)言”,將其擴(kuò)展至 LLM 的詞表中,使得視覺(jué)與文本能夠以相同的 “下一 token 預(yù)測(cè)” 范式聯(lián)合建模,無(wú)縫融合多模態(tài)信息。盡管早期工作(如 LWM、Chameleon)驗(yàn)證了該范式的潛力,但其從頭訓(xùn)練的方式計(jì)算成本高昂,而后續(xù)工作引入擴(kuò)散模型(如 Transfusion、Show-o)又導(dǎo)致訓(xùn)練目標(biāo)割裂,制約了模型效率與靈活性。
本文提出 Liquid,一種將現(xiàn)有 LLM 直接擴(kuò)展為統(tǒng)一多模態(tài)大模型的框架。Liquid 通過(guò) VQVAE 將圖像編碼為離散視覺(jué) token,使圖像與文本共享同一詞匯空間,無(wú)需修改 LLM 結(jié)構(gòu)即可實(shí)現(xiàn)視覺(jué)理解與生成。研究發(fā)現(xiàn),現(xiàn)有 LLM 因其強(qiáng)大的語(yǔ)義理解與生成能力,是理想的多模態(tài)擴(kuò)展起點(diǎn)。相比從頭訓(xùn)練的 Chameleon,Liquid 節(jié)省 100 倍訓(xùn)練成本,同時(shí)實(shí)現(xiàn)更強(qiáng)的多模態(tài)能力。團(tuán)隊(duì)進(jìn)一步探索了從 0.5B 到 32B 六種不同規(guī)模 LLM 的擴(kuò)展性能,覆蓋多種模型家族,并揭示三大核心特性:
a. 尺度規(guī)律統(tǒng)一性:視覺(jué)生成任務(wù)中驗(yàn)證損失與生成質(zhì)量遵循與語(yǔ)言任務(wù)一致的縮放規(guī)律;
b. 規(guī)模化解耦效應(yīng):多模態(tài)訓(xùn)練下受損的語(yǔ)言能力隨模型規(guī)模擴(kuò)大而逐漸恢復(fù),表明大模型具備多任務(wù)無(wú)縫處理能力;
c. 跨任務(wù)互惠性:視覺(jué)理解與生成任務(wù)通過(guò)共享表征空間實(shí)現(xiàn)雙向促進(jìn),驗(yàn)證統(tǒng)一建模的聯(lián)合優(yōu)化優(yōu)勢(shì)。
極簡(jiǎn)多模態(tài)架構(gòu) Liquid
Liquid 采用了將圖像與文本以完全相同的方式對(duì)待的一致處理框架。基于 VQVAE 的圖像分詞器將輸入圖像轉(zhuǎn)換為離散編碼,這些編碼與文本編碼共享相同的詞匯表和嵌入空間。圖像 token 與文本 token 混合后,輸入到 LLM 中,并以 “next token prediction” 的形式進(jìn)行訓(xùn)練。

圖像分詞器:對(duì)于圖像分詞器采用與 Chameleon 相同的 VQGAN 作為圖像分詞器,將 512×512 的圖像編碼為 1024 個(gè)離散 token,嵌入到大小為 8192 的碼本中。這些離散圖像 token 被附加到 BPE 分詞器生成的文本碼本中,擴(kuò)展了 LLM 的詞表,使其語(yǔ)言空間升級(jí)為包含視覺(jué)與語(yǔ)言元素的多模態(tài)空間。
架構(gòu)設(shè)計(jì):Liquid 基于現(xiàn)有 LLM 構(gòu)建,本文以 GEMMA-7B 為基礎(chǔ)模型,驗(yàn)證其在多模態(tài)理解、圖像生成及純文本任務(wù)中的性能。通過(guò)對(duì) LLAMA-3、GEMMA-2 和 Qwen2.5 系列模型(規(guī)模從 0.5B 到 32B)的縮放實(shí)驗(yàn),全面研究了其多模態(tài)擴(kuò)展行為。Liquid 未對(duì) LLM 結(jié)構(gòu)進(jìn)行任何修改,僅添加了 8192 個(gè)可學(xué)習(xí)的圖像 token 嵌入,保留了原始的 “下一 token 預(yù)測(cè)” 訓(xùn)練目標(biāo)及交叉熵?fù)p失。
數(shù)據(jù)準(zhǔn)備:為保留現(xiàn)有 LLM 的語(yǔ)言能力,從公開(kāi)數(shù)據(jù)集中采樣了 30M 文本數(shù)據(jù)(包括 DCLM、SlimPajama 和 Starcoderdata),總計(jì)約 600 億文本 token。對(duì)于圖文對(duì)數(shù)據(jù),使用 JourneyDB 和內(nèi)部圖文數(shù)據(jù),構(gòu)建了 30M 高質(zhì)量圖像數(shù)據(jù),總計(jì) 300 億圖像 token。所有數(shù)據(jù)用于混合多模態(tài)預(yù)訓(xùn)練,使模型快速獲得圖像生成能力的同時(shí)保留語(yǔ)言能力。此外,其中 20% 的圖文數(shù)據(jù)用于訓(xùn)練圖像描述任務(wù),以增強(qiáng)視覺(jué)理解能力。
訓(xùn)練流程:使用總計(jì) 60M 數(shù)據(jù)進(jìn)行繼續(xù)訓(xùn)練。對(duì)于多模態(tài)訓(xùn)練數(shù)據(jù),輸入格式定義為:[bos] {text token} [boi] {image token} [eoi][eos] ,其中 [bos] 和 [eos] 為原始文本分詞器的序列開(kāi)始與結(jié)束標(biāo)記,[boi] 和 [eoi] 為新增的圖像 token 起始與結(jié)束標(biāo)記。在縮放實(shí)驗(yàn)中,針對(duì)每個(gè)模型規(guī)模,分別使用 30M 純文本數(shù)據(jù)、30M 文本到圖像數(shù)據(jù)及 60M 混合數(shù)據(jù)訓(xùn)練三個(gè)獨(dú)立版本,并評(píng)估其在一系列任務(wù)中的性能。
統(tǒng)一多模態(tài)模型尺度規(guī)律探索
文章探索了規(guī)模從 0.5B 到 32B 的 6 種 LLM 在混合模態(tài)訓(xùn)練后的視覺(jué)生成性能。隨著模型規(guī)模和訓(xùn)練迭代次數(shù)的增加,驗(yàn)證損失平穩(wěn)下降,而 token 準(zhǔn)確率和 VQA 分?jǐn)?shù)持續(xù)上升。在相同的訓(xùn)練 FLOPs 下,較小模型能夠更快地達(dá)到較低的驗(yàn)證損失和較高的 VQA 分?jǐn)?shù),但較大模型最終能夠?qū)崿F(xiàn)更高的評(píng)估指標(biāo)。這可能是因?yàn)檩^小模型能夠快速完成更多訓(xùn)練步驟,從而更快地適應(yīng)視覺(jué)信息,但其上限較低,難以實(shí)現(xiàn)高質(zhì)量的視覺(jué)生成結(jié)果。

為了探究視覺(jué)生成能力是否影響語(yǔ)言能力,文章比較了在不同規(guī)模下,使用 30M 純語(yǔ)言數(shù)據(jù)訓(xùn)練和 60M 多模態(tài)混合數(shù)據(jù)訓(xùn)練的模型在語(yǔ)言任務(wù)上的表現(xiàn)。較小模型在混合任務(wù)訓(xùn)練時(shí)存在權(quán)衡現(xiàn)象:多模態(tài)混合訓(xùn)練后 1B 模型語(yǔ)言任務(wù)下降 8.8%,7B 模型下降 1.9%。然而,隨著模型規(guī)模的增加,這種權(quán)衡逐漸消失,32B 模型實(shí)現(xiàn)幾乎零沖突共生(語(yǔ)言能力保留率 99.2%),這表明較大模型具備足夠的能力,能夠同時(shí)處理視覺(jué)和語(yǔ)言空間的生成任務(wù)。

理解與生成相互促進(jìn)
為探究 Liquid 統(tǒng)一范式中理解與生成任務(wù)的交互關(guān)系,研究團(tuán)隊(duì)設(shè)計(jì)了一組消融實(shí)驗(yàn):以 10M 純文本 + 10M 視覺(jué)生成 + 10M 視覺(jué)理解數(shù)據(jù)(總計(jì) 30M)作為基線,分別額外增加 10M 生成或理解數(shù)據(jù)進(jìn)行對(duì)比訓(xùn)練。實(shí)驗(yàn)發(fā)現(xiàn),增加理解數(shù)據(jù)可使生成任務(wù)性能顯著提升,反之增加生成數(shù)據(jù)亦能增強(qiáng)理解能力。這一突破性現(xiàn)象表明,當(dāng)視覺(jué)理解與生成共享統(tǒng)一模態(tài)空間時(shí),兩者的優(yōu)化目標(biāo)具備同源性 —— 均依賴(lài)語(yǔ)言與視覺(jué)信息的深度對(duì)齊與交互,從而形成跨任務(wù)協(xié)同效應(yīng)。該發(fā)現(xiàn)不僅驗(yàn)證了多模態(tài)任務(wù)聯(lián)合優(yōu)化的可行性,更揭示了 LLM 作為通用生成器的本質(zhì)潛力:單一模態(tài)空間下的跨任務(wù)互惠可大幅降低訓(xùn)練成本,推動(dòng)多模態(tài)能力高效進(jìn)化。

模型性能
視覺(jué)生成實(shí)驗(yàn)效果
在 GenAI-Bench 評(píng)測(cè)中,Liquid 在基礎(chǔ)與高級(jí)文本提示下的綜合得分均超越所有自回歸模型,其生成的圖像與文本語(yǔ)義一致性顯著領(lǐng)先。更值得關(guān)注的是,Liquid 以遠(yuǎn)少于擴(kuò)散模型的數(shù)據(jù)量(如 SD v2.1、SD-XL),實(shí)現(xiàn)了與之匹敵甚至更優(yōu)的性能,驗(yàn)證了基于 LLM 的跨模態(tài)學(xué)習(xí)在語(yǔ)義關(guān)聯(lián)捕捉與訓(xùn)練效率上的雙重優(yōu)勢(shì)。
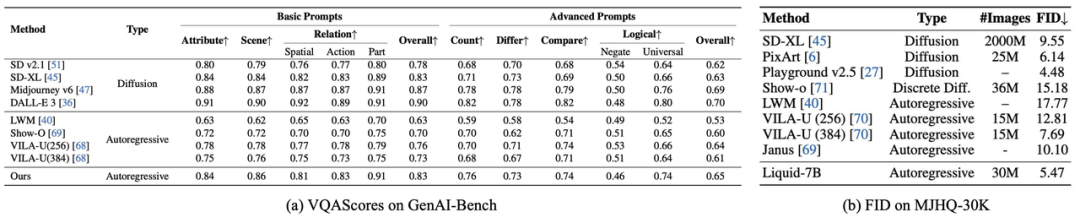
在 MJHQ-30K 評(píng)測(cè)中,Liquid 以 FID=5.47 刷新自回歸模型上限,不僅大幅領(lǐng)先同類(lèi)方法,更超越多數(shù)知名擴(kuò)散模型(僅次 Playground v2.5),證明 LLM 在圖像美學(xué)質(zhì)量上可與頂尖生成模型抗衡。
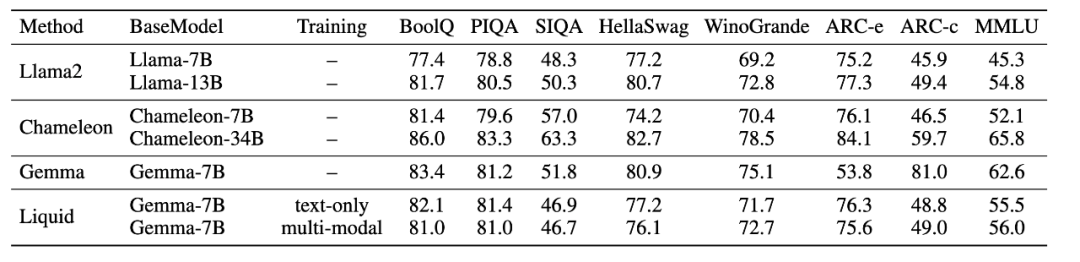
語(yǔ)言能力保留
在一些經(jīng)典的語(yǔ)言能力評(píng)估 benchmark 上,Liquid 在大多數(shù)任務(wù)中超越了成熟的 LLAMA2 和經(jīng)過(guò)大規(guī)模混合預(yù)訓(xùn)練的多模態(tài)語(yǔ)言模型 Chameleon,展示了其未退化的語(yǔ)言能力。與 Chameleon 相比,Liquid 基于已具備優(yōu)秀語(yǔ)言能力的豐富現(xiàn)有 LLM 進(jìn)行訓(xùn)練,在擴(kuò)展視覺(jué)生成與理解能力的同時(shí),成功保留了語(yǔ)言能力,證明 Liquid 可以將視覺(jué)生成與理解能力擴(kuò)展到任何結(jié)構(gòu)和規(guī)模的 LLM 中。
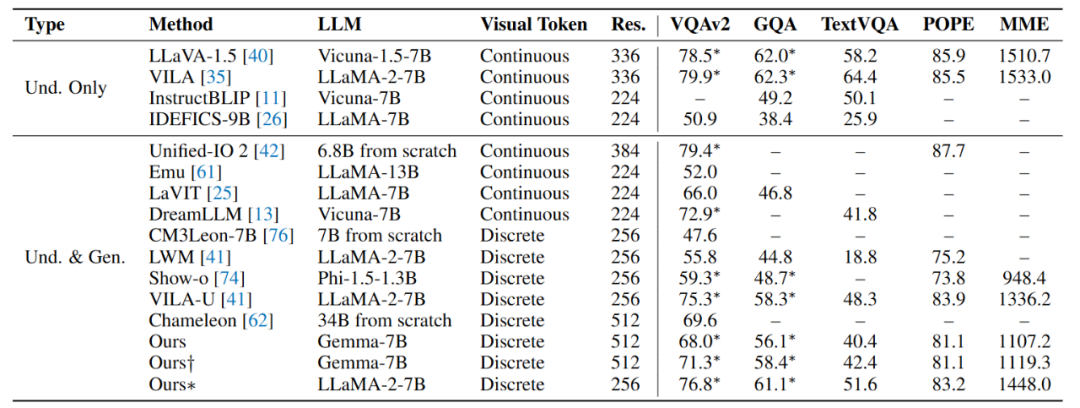
視覺(jué)理解能力
在視覺(jué)理解任務(wù)中,Liquid 性能顯著超越采用標(biāo)準(zhǔn) VQVAE 的同類(lèi)模型(如 LWM、Chameleon、Show-o)。盡管其表現(xiàn)仍略遜于依賴(lài)連續(xù)視覺(jué) token 的主流模型(如 LLaVA),但研究團(tuán)隊(duì)通過(guò)引入 Unitok 圖像分詞器(融入圖文特征對(duì)齊訓(xùn)練,* 標(biāo)結(jié)果),使模型理解能力大幅提升,逼近 LLaVA 水平。這驗(yàn)證了基于離散編碼的多模態(tài)大模型具有擺脫 CLIP 編碼器的潛力。
總結(jié)
綜上所述,本文提出了 Liquid,一種極簡(jiǎn)的統(tǒng)一多模態(tài)生成與理解任務(wù)框架。與依賴(lài)外部視覺(jué)模塊的傳統(tǒng)方法相比,Liquid 通過(guò)視覺(jué)離散編碼直接復(fù)用現(xiàn)有大語(yǔ)言模型處理視覺(jué)信息,實(shí)現(xiàn)了圖像生成與理解的無(wú)縫融合。實(shí)驗(yàn)驗(yàn)證了語(yǔ)言模型在視覺(jué)生成任務(wù)中可以在保留語(yǔ)言能力的情況下媲美主流擴(kuò)散模型,并且發(fā)現(xiàn)多模態(tài)任務(wù)的統(tǒng)一帶來(lái)的語(yǔ)言和視覺(jué)能力的削弱,會(huì)隨著模型規(guī)模的增加而逐漸消失。此外,原文還揭示了多模態(tài)任務(wù)間的互惠關(guān)系和更多的尺度現(xiàn)象,為大規(guī)模預(yù)訓(xùn)練提供了新的思路。






























