拋棄自回歸,連接一致性Diffusion和LLM!UCSD上交新作熱度緊追AF 3
DeepMind新發(fā)布的AlphaFold 3是科技圈今天的絕對(duì)大熱門(mén),成為了Hacker News等許多科技媒體的頭版頭條。
 圖片
圖片
Hacker News熱榜上緊隨其后的則是今年2月發(fā)布的論文「一致性大語(yǔ)言模型」。
 圖片
圖片
到底是什么樣的成果,竟然可以頂著AlphaFold 3的熱度出圈?
這篇論文不僅切中了大語(yǔ)言模型推理速度慢的痛點(diǎn),而且實(shí)現(xiàn)了性能大幅度提升。
 圖片
圖片
CLLM在多個(gè)下游任務(wù)上都取得了2-3倍的加速,且推理過(guò)程沒(méi)有引入額外成本。在GSM8K和Spider兩個(gè)任務(wù)中,相比今年1月剛發(fā)布的Medusa 2都有了明顯提升。
 圖片
圖片
論文的兩位共同一作都是一年級(jí)博士生,分別是來(lái)自上海交通大學(xué)的寇思麒和來(lái)自加州大學(xué)圣地亞哥分校的胡嵐翔,他們的指導(dǎo)老師是交大的鄧志杰教授和UCSD的張昊教授,后者也是Vicuna/vLLM/Chatbot Arena等項(xiàng)目的作者。
目前這篇論文已經(jīng)被ICML 2024會(huì)議接收,所用代碼已在GitHub上開(kāi)源,可以在HuggingFace倉(cāng)庫(kù)上看到模型多個(gè)版本的權(quán)重。
 圖片
圖片
 圖片
圖片
https://github.com/hao-ai-lab/Consistency_LLM
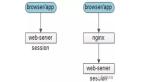
LLM苦推理速度久矣
以GPT和Llama家族為代表的大語(yǔ)言模型雖然可以出色地完成人類語(yǔ)言任務(wù),但代價(jià)也是巨大的。
除了參數(shù)量大,推理速度慢、token吞吐量低也是經(jīng)常被人詬病的問(wèn)題,尤其是對(duì)于上下文信息較多的任務(wù),因此大語(yǔ)言模型的部署和在現(xiàn)實(shí)中的應(yīng)用十分受限。
Reddit上經(jīng)常有開(kāi)發(fā)者詢問(wèn)減少LLM推理時(shí)間的方法,有人曾經(jīng)發(fā)帖,在64G GPU內(nèi)存、4塊英偉達(dá)T4芯片上用langchain部署7B的Llama 2模型后,需要10秒鐘回答較小的查詢,較大的查詢則需要3分鐘。

為了提高推理速度和token吞吐量,研究者們想了很多方法,比如去年很流行的vLLM推理框架,就是通過(guò)改進(jìn)注意力算法來(lái)提高語(yǔ)言模型的效率。
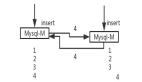
CLLM的思路則放在了解碼上,使用更適合并行的Jacobi算法替代傳統(tǒng)的自回歸方法。
Jacobi解碼算法
自回歸解碼算法在運(yùn)行時(shí),每次只能基于已知序列生成1個(gè)token,這種基于時(shí)間序列的算法對(duì)GPT之類的大模型非常不友好,要想實(shí)現(xiàn)并行化的推理,就必須修改模型架構(gòu)或者添加額外的構(gòu)件。
 圖片
圖片
這篇研究則提出,使用Jacobi解碼算法取代傳統(tǒng)的自回歸,每一次解碼可以同時(shí)生成序列后n個(gè)token。
Jacobi解碼源自用于求解非線性方程的Jacobi和Gauss-Seidel定點(diǎn)迭代,并被證明與使用貪婪解碼的自回歸生成相同。
給定一個(gè)初始序列時(shí),首先生成n個(gè)隨機(jī)token作為起始點(diǎn),之后將這n個(gè)token的優(yōu)化問(wèn)題看作n個(gè)非線性方程組,里面含有的n個(gè)變量可以基于Jacobi迭代并行求解。
每一次Jacobi迭代可以預(yù)測(cè)出一個(gè)或多個(gè)正確的token,進(jìn)行多輪迭代直至收斂,就完成了n個(gè)token的預(yù)測(cè),迭代的過(guò)程形成Jacobi軌跡。
 圖片
圖片
本篇文章所用Jacobi算法的靈感追溯至2021年的一篇論文,用求解非線性方程組加速神經(jīng)網(wǎng)絡(luò)計(jì)算。
 圖片
圖片
論文地址:https://arxiv.org/pdf/2002.03629
以及張昊組的另一篇論文lookahead decoding:
 圖片
圖片
論文地址:https://arxiv.org/pdf/2402.02057
一致性語(yǔ)言模型
使用Jacobi算法解碼時(shí),大語(yǔ)言模型的推理過(guò)程可以被歸納為——一致地將雅可比軌跡 ?? 上的任何點(diǎn) ?? 映射到固定點(diǎn) ??? ,而這個(gè)訓(xùn)練目標(biāo)和一致性模型非常相似。
「一致性模型」最初由ICML 2023的一篇論文提出,作者是四位大名鼎鼎的OpenAI研究科學(xué)家:Ilya Sutskever、宋飏、Mark Chen以及DALLE3的作者之一Prafulla Dhariwal。
 圖片
圖片
論文地址:https://arxiv.org/pdf/2303.01469
因此,這項(xiàng)研究提出在目標(biāo)語(yǔ)言模型的基礎(chǔ)上,聯(lián)合兩種損失函數(shù)來(lái)調(diào)整CLLM——一致性損失(consistency loss)保證同時(shí)預(yù)測(cè)多個(gè)token,自回歸損失防止CLLM偏離目標(biāo)語(yǔ)言模型,保證生成質(zhì)量的同時(shí)提升效率。
 圖片
圖片
實(shí)驗(yàn)結(jié)果也比較理想,CLLM方法確實(shí)可以在接近目標(biāo)模型生成效果的同時(shí),大幅加快生成速度,從原有的約40 token/s提升至超過(guò)120 token/s。
 圖片
圖片
 圖片
圖片
除了推理性能的提升,這種解碼方法也在更抽象的層次上提升了LLM的能力。
由于不再是逐個(gè)生成token而是同時(shí)預(yù)測(cè)序列后面的n個(gè)token,CLLM似乎理解了一個(gè)重要的語(yǔ)言概念——詞語(yǔ)搭配。
它會(huì)更頻繁地生成固定的詞組和術(shù)語(yǔ),比如「與...交談」,或者編程語(yǔ)言中「if...else...」這樣的常用語(yǔ)法結(jié)構(gòu),這似乎也更符合人類使用語(yǔ)言的習(xí)慣。
參考資料:
https://hao-ai-lab.github.io/blogs/cllm/
https://news.ycombinator.com/item?id=40302201
https://www.reddit.com/r/MachineLearning/comments/15851sr/d_how_do_i_reduce_llm_inferencing_time/