一文揭開 NVIDIA CUDA 神秘面紗
Hello folks,我是 Luga,今天我們繼續來聊一下人工智能生態相關技術 - 用于加速構建 AI 核心算力的 GPU 編程框架 - CUDA 。
CUDA,作為現代圖形處理器(GPU)的計算單元,在高性能計算領域扮演著日益重要的角色。通過將復雜的計算任務分解為數千個線程并行執行,CUDA 顯著提升了計算速度,為人工智能、科學計算、高性能計算等領域帶來了革命性的變革。

CUDA 到底是什么 ?
毋庸置疑,你一定聽說過 CUDA,并了解這玩意與 NVIDIA GPU 密切相關。然而,關于 CUDA 的具體定義和功能,許多人仍然心存疑惑,一臉懵逼。CUDA 是一個與 GPU 進行通信的庫嗎?
如果是,它屬于 C++ 還是 Python 庫?或者,CUDA 實際上是一個用于 GPU 的編譯器?了解這些問題有助于更好地掌握 CUDA 的核心特性及其在 GPU 加速中的作用。
CUDA,全稱為 “ Compute Unified Device Architecture ”,即“計算統一設備架構”,是 NVIDIA 推出的一套強大并行計算平臺和編程模型框架,為開發人員提供了加速計算密集型應用的完整解決方案。CUDA 包含運行時內核、設備驅動程序、優化庫、開發工具和豐富的 API 組合,使得開發人員能夠在支持 CUDA 的 GPU 上運行代碼,大幅提升應用程序的性能。這一平臺尤為適合用于處理大規模并行任務,如深度學習、科學計算以及圖像處理等領域。
通常而言,“CUDA” 不僅指平臺本身,也可指為充分利用 NVIDIA GPU 的計算能力而編寫的代碼,這些代碼多采用 C++ 和 Python 等語言編寫,以充分發揮 GPU 加速的優勢。借助 CUDA,開發人員能夠更加輕松地將復雜的計算任務轉移至 GPU 運行,極大提升應用程序的運行效率。
因此,總結起來,我們可以得出如下結論:
CUDA 不僅僅是一個簡單的庫,它是一個完整的平臺,為開發者提供了利用 GPU 進行高效并行計算的全方位支持。這個平臺的核心組件包括:
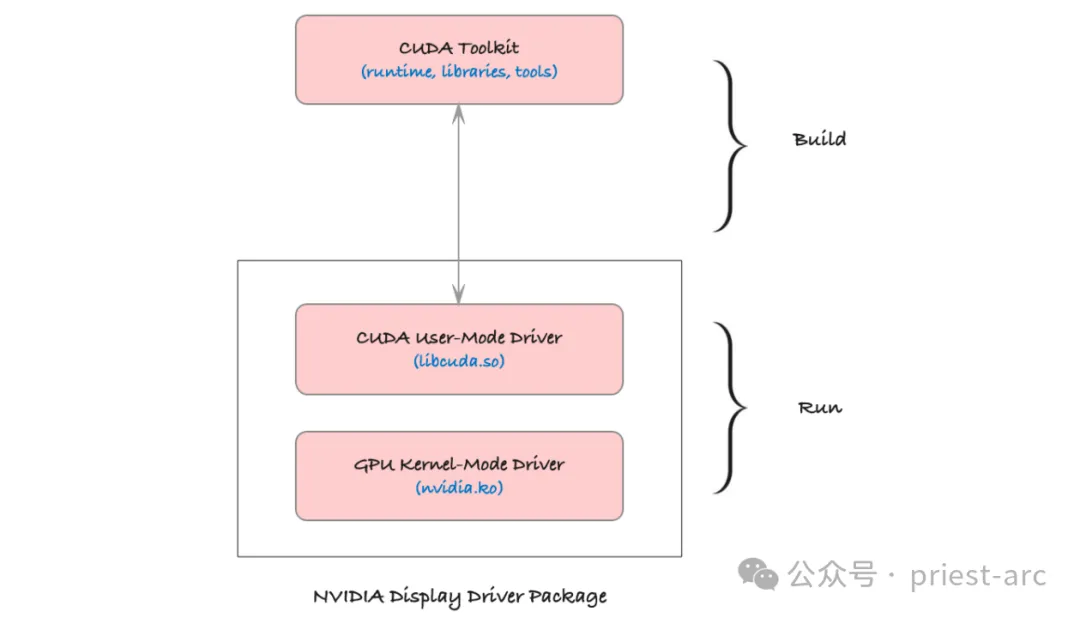
- CUDA C/C++:這是 CUDA 為并行編程所擴展的 C++ 語言,專為在 GPU 上編寫并行代碼而設計。開發者可以使用熟悉的 C++ 語法結構,通過特定的編程模型定義 GPU 任務,讓代碼更高效地在多線程環境中執行。
- CUDA 驅動程序:這一組件連接操作系統與 GPU,提供底層硬件訪問接口。驅動程序的主要作用是管理 CPU 與 GPU 之間的數據傳輸,并協調它們的計算資源。它確保了硬件和操作系統的兼容性,是 CUDA 代碼高效運行的基礎。
- CUDA 運行時庫(cudart):運行時庫為開發者提供了豐富的 API,便于管理 GPU 內存、啟動 GPU 內核(即并行任務)、同步線程等。它簡化了開發者的工作流程,使得在 GPU 上運行并行程序的流程更加流暢和高效。
- CUDA 工具鏈(ctk):包括編譯器、鏈接器、調試器等工具,這些工具用于將 CUDA 代碼編譯成 GPU 可執行的二進制指令。工具鏈中的編譯器將 C++ 代碼和 CUDA 內核代碼一同處理,使其適應 GPU 的架構;而調試器和分析工具幫助開發者優化性能和排查問題。
相關的環境變量可參考如下:
- $CUDA_HOME是系統CUDA的路徑,看起來像/usr/local/cuda,它可能鏈接到特定版本/usr/local/cuda-X.X。
- $LD_LIBRARY_PATH是一個幫助應用程序查找鏈接庫的變量。您可能想要包含$CUDA_HOME/lib的路徑。
- $PATH應該包含一個通往$CUDA_HOME/bin的路徑。
借助這一完整的開發平臺,開發者能夠充分挖掘 NVIDIA GPU 的計算潛力,將復雜的并行計算任務高效地分配至 GPU 上執行,從而實現應用程序性能的極大提升。
CUDA 是如何工作的 ?
現代 GPU 由數千個小型計算單元組成,這些單元被稱為 CUDA 核心。CUDA 核心能夠高效并行工作,使 GPU 能夠快速處理那些可以分解為多個小型獨立操作的任務。這種架構使得 GPU 不僅適用于圖形渲染任務,也適用于計算密集型的科學計算和機器學習等非圖形任務。
作為 NVIDIA 提供的一個計算平臺和編程模型,CUDA 專門為 GPU 開放了這些強大的并行處理能力。通過 CUDA,開發者可以編寫代碼,將復雜的計算任務移交給 GPU。以下是 CUDA 的工作原理:
(1) 并行處理
CUDA 將計算任務分解為多個可以獨立運行的小任務,并將這些任務分配到多個 CUDA 核心上并行執行。這樣一來,與傳統 CPU 順序執行的模式相比,GPU 可以在相同時間內完成更多的計算,從而極大地提升計算效率。
(2) 線程和塊的架構
在 CUDA 編程模型中,計算任務被進一步劃分為線程,每個線程獨立處理一部分數據。這些線程被組織成塊,每個塊中包含一定數量的線程。這種層次化結構不僅便于管理海量線程,還提高了執行效率。多個線程塊可以同時運行,使得整個任務可以快速并行完成。
(3) SIMD 架構
CUDA 核心采用單指令多數據(Single Instruction, Multiple Data,簡稱 SIMD)架構。這意味著單條指令可以對多個數據元素同時執行操作。例如,可以用一條指令對大量數據元素進行相同的計算,從而加快數值計算的速度。這種架構對矩陣運算、向量處理等高并行任務極為高效,特別適用于深度學習模型訓練、圖像處理和模擬仿真等領域。
基于這些特性,CUDA 不僅為高性能并行計算提供了直接途徑,也將 NVIDIA GPU 的強大計算潛力拓展至科學計算、人工智能、圖像識別等領域,為開發者實現復雜計算任務的加速提供了強有力的支持。
CUDA 編程模型
在 CUDA 編程中,開發者通常需要編寫兩部分代碼:主機代碼(Host Code)和設備代碼(Device Code)。
主機代碼在 CPU 上運行,負責與 GPU 進行交互,包括數據傳輸和資源管理;而設備代碼則在 GPU 上執行,承擔主要計算任務。二者相互配合,充分利用 CPU 和 GPU 的協同處理能力,以達到高效并行計算的目的。
(1) 主機代碼:主機代碼運行在 CPU 上,負責控制整個程序的邏輯流程。它管理 CPU 和 GPU 之間的數據傳輸,分配和釋放 GPU 資源,并配置 GPU 內核參數。這部分代碼不僅定義了如何組織數據并將其發送到 GPU,還包含了啟動設備代碼的指令,從而讓 GPU 接管計算密集的任務。主機代碼起到管理和協調的作用,確保 CPU 與 GPU 之間的高效協作。
此部分包括數據傳輸、內存管理、以及啟動 GPU 內核等,具體功能可參考如下所示:
- 數據傳輸管理:主機代碼負責在 CPU 和 GPU 之間傳輸數據。由于 CPU 和 GPU 通常使用不同的內存系統,主機代碼需要在兩者之間復制數據。例如,將需要處理的數據從主機內存(CPU 內存)傳輸到設備內存(GPU 內存),并在處理完成后將結果從 GPU 內存傳回 CPU 內存。這種數據傳輸是耗時的,因此在實際應用中需要盡量減少傳輸頻率,并優化數據大小,以降低延遲。
- 內存分配與管理:主機代碼分配 GPU 內存空間,為后續的計算提供儲存資源。CUDA API 提供了多種內存管理函數(如 cudaMalloc 和 cudaFree),允許開發者在 GPU 上動態分配和釋放內存。合理的內存分配策略可以有效提高內存使用效率,防止 GPU 內存溢出。
- 內核配置與調度:在主機代碼中,開發者可以配置內核啟動參數(如線程數和線程塊數)并決定內核在 GPU 上的執行方式。通過優化這些參數,主機代碼能夠顯著提升程序的執行效率
(2) 設備代碼:設備代碼編寫的核心部分是在 GPU 上執行的計算函數,通常被稱為內核(Kernel)。每個內核函數在 GPU 的眾多 CUDA 核心上并行執行,能夠快速處理大量數據。設備代碼專注于數據密集型的計算任務,在執行過程中充分利用 GPU 的并行計算能力,使得計算速度比傳統的串行處理有顯著提升。
設備代碼定義了 GPU 的計算邏輯,使用 CUDA 內核來并行處理大量數據。
- 內核函數(Kernel Function):設備代碼的核心是內核函數,即在 GPU 的多個線程上同時執行的函數。內核函數由 __global__ 關鍵字標識,表示該函數將在設備端(GPU)執行。內核函數與普通的 C/C++ 函數不同,它必須是無返回值的,因為所有輸出結果都要通過修改傳入的指針或 GPU 內存來傳遞。
- 線程和線程塊的組織:在設備代碼中,計算任務被分解為多個線程,這些線程組成線程塊(Block),多個線程塊組成一個線程網格(Grid)。CUDA 提供了 threadIdx、blockIdx 等內置變量來獲取線程的索引,從而讓每個線程在數據中找到屬于自己的計算任務。這種方式使得設備代碼可以非常高效地并行處理數據集中的每個元素。
- 并行算法優化:在設備代碼中,CUDA 編程可以實現多個并行優化技術,例如減少分支、優化內存訪問模式(如減少全局內存訪問和提高共享內存利用率),這些優化有助于最大化利用 GPU 計算資源,提高設備代碼的執行速度。
(3) 內核啟動:內核啟動是 CUDA 編程的關鍵步驟,由主機代碼啟動設備代碼內核,在 GPU 上觸發執行。內核啟動參數指定了 GPU 上線程的數量和分布方式,使內核函數可以通過大量線程并行運行,從而加快數據處理速度。通過適當配置內核,CUDA 編程能以更優的方式利用 GPU 資源,提高應用的計算效率。
在整個體系中,這一步驟至關重要,它控制了設備代碼的并行性、效率及運行行為。具體可參考如下:
- 內核啟動語法:CUDA 使用特殊的語法 <<<Grid, Block>>> 啟動內核函數。例如:kernel<<<numBlocks, threadsPerBlock>>>(parameters);,其中 numBlocks 表示線程塊的數量,threadsPerBlock 表示每個線程塊中包含的線程數。開發者可以根據數據集的大小和 GPU 的計算能力選擇合適的線程塊和線程數量。
- 并行化控制:通過指定線程塊數和線程數,內核啟動控制了 GPU 的并行粒度。較大的數據集通常需要更多的線程和線程塊來充分利用 GPU 的并行能力。合理配置內核啟動參數,可以平衡 GPU 的并行工作負載,避免資源浪費或過載現象。
- 同步與異步執行:內核啟動后,GPU 可以異步執行任務,CPU 繼續進行其他操作,直至需要等待 GPU 完成。開發者可以利用這種異步特性,使程序在 CPU 和 GPU 間并行執行,達到更高的并行效率。此外,CUDA 提供了同步函數(如 cudaDeviceSynchronize),確保 CPU 在需要時等待 GPU 完成所有操作,避免數據不一致的問題。
通過有效協調這三者,CUDA 編程能夠實現對數據密集型任務的高速并行處理,為高性能計算提供了一個極具擴展性的解決方案。
CUDA 內存層次結構體系
在 CUDA 編程中,GPU 內存的結構是多層次的,具有不同的速度和容量特性。CUDA 提供了多種內存類型,用于不同的數據存儲需求。合理利用這些內存可以顯著提升計算效率。以下是各類內存的詳細描述:
(1) 全局內存(Global Memory)
全局內存是 GPU 上容量最大的存儲空間,通常為幾 GB,并且是 GPU 的主要數據存儲區。全局內存可以被所有線程訪問,也可以與 CPU 共享數據,但其訪問速度相對較慢(相對于其他 GPU 內存類型而言),因此需要避免頻繁訪問。數據傳輸操作也較耗時,因此全局內存常用于存儲較大的數據集,但會優先考慮數據訪問的批處理或其他緩存策略來減少其頻繁調用。
通常而言,全局內存主要適用于存儲程序的大部分輸入輸出數據,尤其是需要 GPU 和 CPU 共享的大容量數據。
示例:在矩陣乘法中,兩個矩陣的元素可以存儲在全局內存中,以便所有線程都可以訪問。
__global__ void matrixMultiplication(float *A, float *B, float *C, int N) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
float sum = 0.0;
for (int i = 0; i < N; ++i) {
sum += A[row * N + i] * B[i * N + col];
}
C[row * N + col] = sum;
}(2) 共享內存(Shared Memory)
共享內存是分配在 GPU 每個線程塊內部的高速緩存,其訪問速度遠高于全局內存,但容量較小(通常為每塊 48 KB 或更少)。共享內存是線程塊內線程共享的,適合存儲需要在一個線程塊內頻繁訪問的數據。由于它存儲在各自的塊內,每個塊內的線程可以在共享內存中快速讀寫數據,從而減少對全局內存的訪問。
相對于全局內存,共享內存更多適用于多線程間的數據交換,尤其是需在一個線程塊內反復使用的數據。
示例:在矩陣乘法中,A 和 B 的子塊可以加載到共享內存中,以便線程塊中的所有線程都可以快速訪問。
__shared__ float sharedA[TILE_SIZE][TILE_SIZE];
__shared__ float sharedB[TILE_SIZE][TILE_SIZE];(3) 本地內存(Local Memory)
本地內存是分配給每個線程的私有內存,主要用于存儲線程的私有變量。盡管稱為“本地”,它實際上是分配在全局內存中,因此訪問速度較慢,接近全局內存的訪問速度。由于本地內存容量有限且其訪問開銷較高,建議只在必要時使用。
通常情況下,本地內存適用于存儲線程的臨時變量、私有數據或不適合在寄存器中保存的數據。
示例:對于復雜計算中的中間變量,可以放置在本地內存中,以便線程之間不發生沖突。
int localVariable = 0; // 本地內存中的變量(4) 常量和紋理內存(Constant and Texture Memory)
常量內存和紋理內存分別是 CUDA 提供的專用于只讀數據的內存類型,具有特殊的緩存機制,能夠在特定訪問模式下加快數據讀取。常量內存用于存儲不會更改的常量數據,而紋理內存適合存儲二維或三維數據,通過紋理緩存可以提高訪問速度。
常量內存(Constant Memory):僅可由 CPU 寫入,但可被所有 GPU 線程讀取。適合存儲小規模的、不變的數據(如配置信息、系數等)。
紋理內存(Texture Memory):專門優化以支持二維或三維數據的讀取,對于非順序或稀疏訪問模式的數據(如圖像數據)具有較高的訪問效率。
示例:在圖像處理應用中,將像素數據加載到紋理內存中,讓 GPU 利用其特定的緩存機制來優化訪問效率。
__constant__ float constData[256]; // 常量內存
cudaArray* texArray;
cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc<float>();
cudaMallocArray(&texArray, &channelDesc, width, height); // 紋理內存CUDA平臺為開發人員提供了對CUDA GPU并行計算資源的深度訪問,允許直接操作GPU的虛擬指令集和內存。通過使用CUDA,GPU可以高效地處理數學密集型任務,從而釋放CPU的計算資源,使其能夠專注于其他任務。這種架構與傳統GPU的3D圖形渲染功能有著本質的區別,開創了GPU在計算領域的新用途。
在CUDA平臺的架構中,CUDA核心是其核心組成部分。每個CUDA核心都是一個獨立的并行處理單元,負責執行各種計算任務。GPU中的CUDA核心數量越多,它能夠并行處理的任務就越多,從而顯著提升計算性能。通過這種并行計算,CUDA平臺能夠在復雜的計算過程中實現大規模任務的并行處理,提供卓越的性能和高效性。
Reference :
- [1] https://acecloud.ai/resources/blog/why-gpus-for-deep-learning/
- [2] https://www.weka.io/learn/glossary/ai-ml/cpu-vs-gpu/