














譯者 | 朱先忠
審校 | 重樓
本文將以實戰案例探討如何在類似聊天的模式下從本地構建Llama3.2-Vision模型,并在Colab筆記本上探索其多模態技能。

簡介
視覺功能與大型語言模型(LLM)的集成正在通過多模態LLM(MLLM)徹底改變計算機視覺領域。這些模型結合了文本和視覺輸入,在圖像理解和推理方面表現出令人印象深刻的能力。雖然這些模型以前只能通過API訪問,但是最近發布的一些開源項目已經支持在本地執行,這使得它們對生產環境中一線應用更具吸引力。
在本文中,我們將學習如何使用開源Llama3.2-Vision模型與我們提供的圖像聊天,其間你會驚嘆于該模型的OCR、圖像理解和推理能力。示例工程的所有代碼都將方便地提供在一個Colab筆記本文件中。
Llama 3.2-Vision模型
背景
Llama是“大型語言模型MetaAI”的縮寫,是Meta公司開發的一系列高級大語言模型。他們的產品Llama 3.2推出了先進的視覺功能。視覺變體有兩種大小:11B和90B參數,可在邊緣設備上進行推理。Llama 3.2具有高達128k個標記的上下文窗口,支持高達1120x1120像素的高分辨率圖像,可以處理復雜的視覺和文本信息。
架構
Llama系列模型是僅使用解碼器的轉換器。Llama3.2-Vision模型建立在預訓練的Llama 3.1純文本模型之上。它采用標準的密集自回歸轉換器架構,與其前身Llama和Llama 2并無太大差異。
為了支持視覺任務,Llama 3.2使用預訓練的視覺編碼器(ViT-H/14)提取圖像表示向量,并使用視覺適配器將這些表示集成到凍結語言模型中。適配器由一系列交叉注意層組成,允許模型專注于與正在處理的文本相對應的圖像的特定部分(參考文獻【1】)。
適配器基于“文本-圖像”對進行訓練,以使圖像表示與語言表示對齊。在適配器訓練期間,圖像編碼器的參數會更新,而語言模型參數保持凍結以保留現有的語言能力。
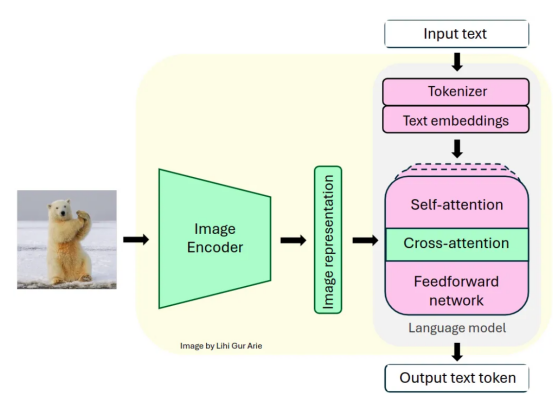
Llama 3.2-Vision模型架構:視覺模塊(綠色)集成到固定語言模型(粉紅色)中
這種設計使Llama 3.2在多模態任務中表現出色,同時保持其強大的純文本性能。生成的模型在需要圖像和語言理解的任務中展示了令人印象深刻的能力,并允許用戶與他們的視覺輸入進行交互式交流。
編碼實戰
有了對Llama 3.2架構的基本了解后,讓我們深入研究其實際實現。但首先,我們需要做一些準備工作。
準備
在Google Colab上運行Llama3.2—Vision11B之前,我們需要做一些準備:
1.GPU設置
- 建議使用至少具有22GB VRAM的高端GPU進行高效推理(參考文獻【2】)。
- 對于Google Colab用戶來說:需要導航至“運行時”>“更改運行時類型”>“A100 GPU”。請注意,高端GPU可能不適用于免費的Colab用戶。
2.模型權限
請求訪問Llama 3.2模型在鏈接https://www.llama.com/llama-downloads/處提供。
3.HuggingFace設置
如果你還沒有Hugging Face賬戶,請在鏈接https://huggingface.co/join處創建一個。
如果你沒有Hugging Face賬戶,請在鏈接https://huggingface.co/join處生成訪問令牌。
對于Google Colab用戶,請在谷歌Colab Secrets中將Hugging Face令牌設置為名為“HF_TOKEN”的秘密環境變量。
4.安裝所需的庫
加載模型
設置環境并獲得必要的權限后,我們將使用Hugging Face轉換庫來實例化模型及其相關的處理器。處理器負責為模型準備輸入并格式化其輸出。
model_id = "meta-llama/Llama-3.2-11B-Vision-Instruct"
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto")
processor = AutoProcessor.from_pretrained(model_id)預期的聊天模板
聊天模板通過存儲“用戶”(我們)和“助手”(AI模型)之間的交流,通過對話歷史記錄來維護上下文。對話歷史記錄的結構為一個稱為消息的字典列表,其中每個字典代表一個對話輪次,包括用戶和模型響應。用戶輪次可以包括圖像文本或純文本輸入,其中{"type": "image"}表示圖像輸入。
例如,經過幾次聊天迭代后,消息列表可能如下所示:
messages = [
{"role": "user", "content": [{"type": "image"}, {"type": "text", "text": prompt1}]},
{"role": "assistant", "content": [{"type": "text", "text": generated_texts1}]},
{"role": "user", "content": [{"type": "text", "text": prompt2}]},
{"role": "assistant", "content": [{"type": "text", "text": generated_texts2}]},
{"role": "user", "content": [{"type": "text", "text": prompt3}]},
{"role": "assistant", "content": [{"type": "text", "text": generated_texts3}]}
]此消息列表隨后會傳遞給apply_chat_template()方法,以便將對話轉換為模型期望格式的單個可標記字符串。
主函數
在本教程中,我提供了一個chat_with_mllm函數,該函數可實現與Llama 3.2 MLLM的動態對話。此函數能夠處理圖像加載、預處理圖像和文本輸入、生成模型響應并管理對話歷史記錄以啟用聊天模式交互。
def chat_with_mllm (model, processor, prompt, images_path=[],do_sample=False, temperature=0.1, show_image=False, max_new_tokens=512, messages=[], images=[]):
# 確保列表形式:
if not isinstance(images_path, list):
images_path = [images_path]
#加載圖像
if len (images)==0 and len (images_path)>0:
for image_path in tqdm (images_path):
image = load_image(image_path)
images.append (image)
if show_image:
display ( image )
#如果開始了一個關于一個圖像的新的對話
if len (messages)==0:
messages = [{"role": "user", "content": [{"type": "image"}, {"type": "text", "text": prompt}]}]
# 如果繼續對圖像進行對話
else:
messages.append ({"role": "user", "content": [{"type": "text", "text": prompt}]})
# 處理輸入數據
text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(images=images, text=text, return_tensors="pt", ).to(model.device)
生成相應
generation_args = {"max_new_tokens": max_new_tokens, "do_sample": True}
if do_sample:
generation_args["temperature"] = temperature
generate_ids = model.generate(**inputs,**generation_args)
generate_ids = generate_ids[:, inputs['input_ids'].shape[1]:-1]
generated_texts = processor.decode(generate_ids[0], clean_up_tokenization_spaces=False)
# 附加該模型對對話歷史記錄的響應
messages.append ({"role": "assistant", "content": [ {"type": "text", "text": generated_texts}]})
return generated_texts, messages, images與Llama聊天
蝴蝶圖像示例
在我們的第一個示例中,我們將與Llama3.2進行聊天,討論一張孵化蝴蝶的圖像。由于Llama3.2-Vision在使用圖像時不支持使用系統提示進行提示,因此我們將直接在用戶提示中附加說明,以指導模型的響應。通過設置do_sample=True和temperature=0.2,我們可以在保持響應一致性的同時實現輕微的隨機性。對于固定答案,你可以設置do_sample==False。保存聊天歷史記錄的messages參數最初為空,如images參數中所示:
instructions = "Respond concisely in one sentence."
prompt = instructions + "Describe the image."
response, messages,images= chat_with_mllm ( model, processor, prompt,
images_path=[img_path],
do_sample=True,
temperature=0.2,
show_image=True,
messages=[],
images=[])
# 輸出:"The image depicts a butterfly emerging from its chrysalis,
# with a row of chrysalises hanging from a branch above it."
圖片來自Pixabay(https://www.pexels.com/photo/brown-and-white-swallowtail-butterfly-under-white-green-and-brown-cocoon-in-shallow-focus-lens-63643/)。
我們可以看到,輸出準確而簡潔,表明模型有效地理解了圖像。
對于下一次聊天迭代,我們將傳遞一個新提示以及聊天歷史記錄和圖像文件。新提示旨在評估Llama3.2的推理能力:
prompt = instructions + "What would happen to the chrysalis in the near future?"
response, messages, images= chat_with_mllm ( model, processor, prompt,
images_path=[img_path,],
do_sample=True,
temperature=0.2,
show_image=False,
messages=messages,
images=images)
# 輸出: "The chrysalis will eventually hatch into a butterfly."我們在提供的Colab筆記本中繼續此聊天,并得到了以下對話:

對話通過準確描述場景,突出了模型的圖像理解能力。它還展示了它的推理能力,通過邏輯地連接信息來正確推斷蛹會發生什么,并解釋為什么有些蛹是棕色的,而有些蛹是綠色的。
模因圖像示例
在這個例子中,我將向模型展示我自己創建的模因,以評估Llama的OCR能力并確定它是否理解我的幽默感。
instructions = "You are a computer vision engineer with sense of humor."
prompt = instructions + "Can you explain this meme to me?"
response, messages,images= chat_with_mllm ( model, processor, prompt,
images_path=[img_path,],
do_sample=True,
temperature=0.5,
show_image=True,
messages=[],
images=[])這是輸入模因:

作者制作的表情包。原始熊圖像由Hans-Jurgen Mager制作。
這是模型的回應:

我們可以看到,該模型展示了出色的OCR能力,并理解了圖像中文本的含義。至于它的幽默感——你覺得怎么樣,它明白了嗎?你明白了嗎?也許我也應該努力培養我的幽默感!
結束語
在本文中,我們學習了如何在本地構建Llama3.2-Vision模型并管理聊天式交互的對話歷史記錄,從而增強用戶參與度。我們探索了Llama 3.2的零樣本能力,并領悟了其場景理解、推理和OCR技能。
我們還可以將其他一些高級技術應用于Llama 3.2,例如對獨特數據進行微調,或使用檢索增強生成(RAG)來進行預測并減少幻覺。
總體而言,本文帶領你深入了解了快速發展的多模態LLM領域及其在各種應用中的強大功能。
參考文獻
【0】本文示例項目在Colab Notebook地址:https://gist.github.com/Lihi-Gur-Arie/0e87500813c29bb4c4a6a990795c3aaa
【1】Llama 3模型介紹地址:https://arxiv.org/pdf/2407.21783
【2】Llama 3.2 11B Vision模型要求:https://llamaimodel.com/requirements-3-2/
譯者介紹
朱先忠,51CTO社區編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。
原文標題:Chat with Your Images Using Llama 3.2-Vision Multimodal LLMs,作者:Lihi Gur Arie





























