被DeepSeek帶火的知識蒸餾,開山之作曾被NeurIPS拒收,Hinton坐鎮都沒用
DeepSeek帶火知識蒸餾,原作者現身爆料:原來一開始就不受待見。
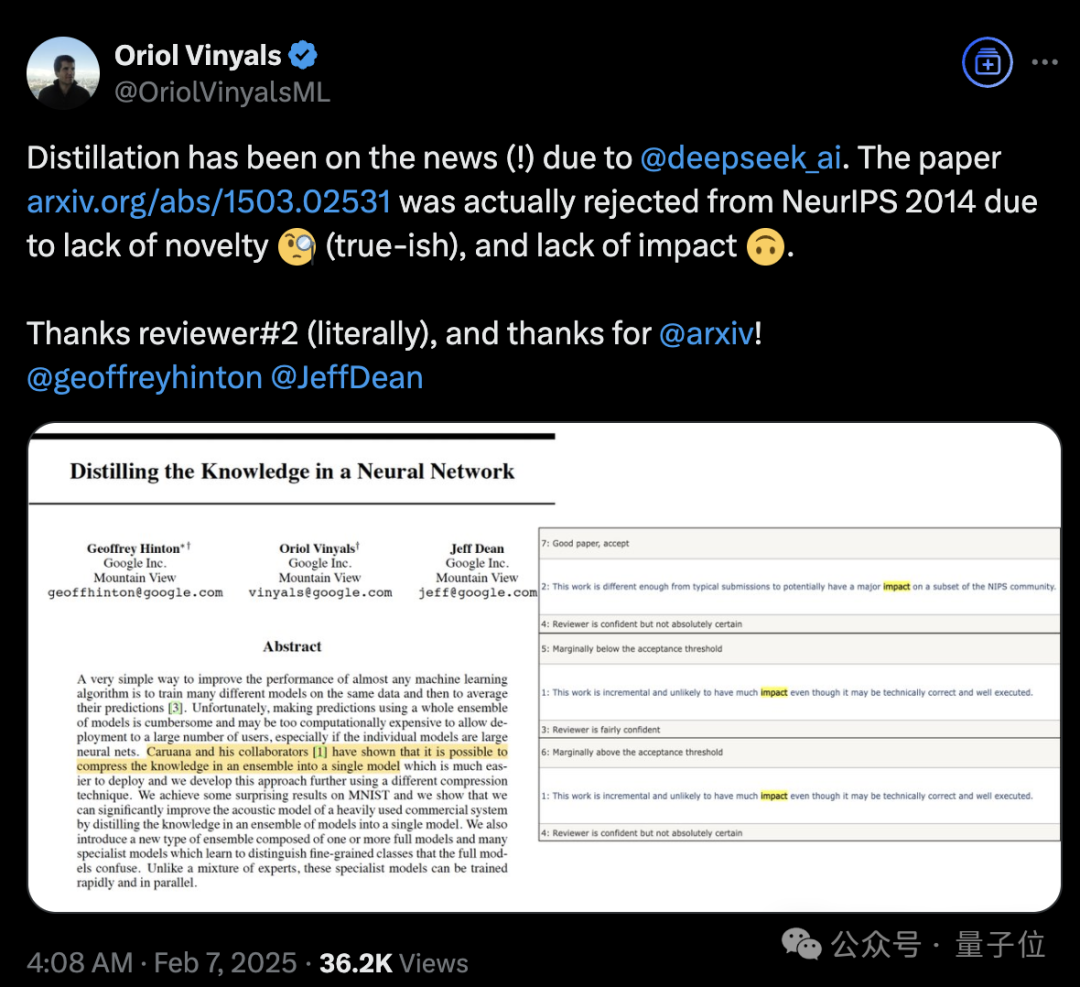
稱得上是“蒸餾圣經”、由Hinton、Oriol Vinyals、Jeff Dean三位大佬合寫的《Distilling the Knowledge in a Neural Network》,當年被NeurIPS 2014拒收。
如何評價這篇論文的含金量?
它提出了知識蒸餾這一概念,能在保證準確率接近的情況下,大幅壓縮模型參數量,讓模型能夠部署在各種資源受限的環境。
比如Siri能夠出現在手機上,就是用知識蒸餾壓縮語音模型。
自它之后,大模型用各種方法提高性能上限,再蒸餾到小模型上已經成為一種行業標配。

再來看它的主創陣容。
Hinton,深度學習之父,如今已是諾獎得主。
Oriol Vinyals,Google DeepMind研究科學家,參與開發的明星項目包括TensorFlow、AlphaFold、Seq2Seq、AlphaStar等。
Jeff Dean,Google DeepMind首席科學家、從2018年開始全面領導谷歌AI。大模型浪潮里,推動了PaLM、Gemini的發展。
不過,那又怎樣?
主創之一Oriol Vinyals表示,因為缺乏創新和影響力,這篇論文被拒啦。謝謝審稿人(字面意思),謝謝arxiv!
方法簡單、適用于各種模型
簡單粗暴總結,《Distilling the Knowledge in a Neural Network》是一篇更偏工程性改進的文章,但是帶來的效果提升非常顯著。
Caruana等人在2006年提出了將集成知識壓縮到單模型的可能性,論文中也明確提到了這一點。
Hinton等人的工作是提出了一種簡單有效的知識遷移框架,相較于Caruana團隊的方法更加通用。
方法看上去非常簡單:
- 用軟目標代替硬目標
- 在softmax層加入溫度參數T。當T=1時,就是普通的softmax輸出。T越大,輸出的概率分布越平滑(soft)。
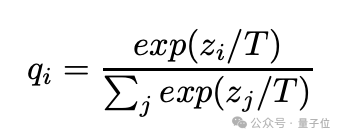
他們認為此前人們習慣性地將模型中的知識與模型的具體參數綁定在一起,因此很難想到該如何在改變模型結構的同時仍舊保留這些知識。
如果把知識看作是輸入向量到輸出向量的一個抽象映射,而不是某種固定的參數實現,就能更容易理解如何將知識從一個模型轉移到另一個模型。
知識蒸餾的關鍵就是讓小模型模仿大模型的“理解方式”,如果大模型是多個模型的集成,表現出很強的泛化能力,那就通過蒸餾訓練小模型去學習這種泛化方式,這種方法能讓小模型集成大模型的知識精髓,同時更適合實際應用部署。
怎么將泛化能力轉移?
讓大模型生成類別概率作為軟目標,以此訓練小模型。
在這個轉移階段,使用與原始訓練相同的數據集,或者單獨準備一個“遷移”數據集。
如果大模型是由多個模型集成,那就取它們的預測平均值。
軟目標的特點是,它具有高熵時(即預測的概率分布更平滑),每個訓練樣本中包含的信息量比硬目標要多得多,訓練樣本之間的梯度變化也更小。
因此,用軟目標訓練小模型時,往往可以使用比原始模型更少的數據,并且可以采用更高的學習率。
小模型可以用無標簽數據或原始訓練。如果用原始訓練數據,可以讓小模型同時學習來自大模型的軟目標和真實標簽,這樣效果會更加好。
具體方法是使用軟目標的交叉熵損失、真實標簽的交叉熵損失兩個目標函數加權平均。如果真實標簽的交叉熵損失權重較小時,往往能獲得最佳效果。
此外,他們還發現軟目標的梯度大小隨著T2縮放,同時使用真實標簽和軟目標時,比如將軟目標的梯度乘以T2,這樣可以確保在調整蒸餾溫度這一超參數時,硬目標和軟目標的相對貢獻保持大致不變。
實驗結果顯示,在MINIST數字時延中,教師模型(1200層)的錯誤案例為67個,學生模型(800層)使用蒸餾后的錯誤案例為74個。
在JFT數據集上,基準模型的錯誤率為27.4%,集成模型的錯誤率為25%。蒸餾模型錯誤率為25.6%,效果接近集成模型但計算量大幅減少。
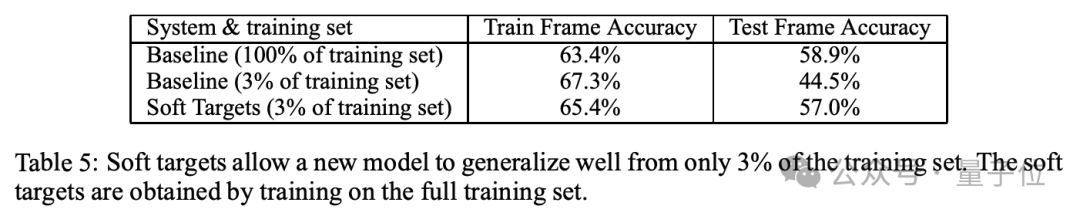
語音識別實驗上,蒸餾模型也達到了與集成模型相同的性能,但是僅使用了3%的訓練數據。
或許還有很多滄海遺珠
值得一提的是,Vinyals還表示,提出了LSTM的Jürgen Schmidhuber在1991年發表的一篇文章,這可能與現在火熱的長上下文息息相關。
他提到的應該是《Learning complex, extended sequences using the principle of history compression》這篇論文。其核心內容是利用歷史壓縮的原則,即通過模型結構和算法將序列的歷史信息有效地編碼和存儲,從而減少處理長序列時的計算開銷,同時保留關鍵的信息。
有人就說,不妨設置一個時間檢驗獎頒給那些未被接收的論文吧。

同時也有人在這個話題下想到了DeepSeek。
曾在蘋果、谷歌工作過的Matt Henderson表示,DeepSeek做的蒸餾只是基于教師模型輸出的微調,并沒有用到軟目標(因為模型的分詞方式不同)。

Vinyals回應說,那看來我們取蒸餾這個名字真的不錯~