字節大模型新進展:首次引入視覺定位,實現細粒度多模態聯合理解,已開源&demo可玩
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
字節大模型,BuboGPT來了。
支持文本、圖像、音頻三種模態,做到細粒度的多模態聯合理解。
答哪指哪,什么講了什么沒講,一目了然:

除了有“慧眼”,還有“聰耳”。人類都注意不到的細節BuboGPT能聽到:
Audio-1-chime-bird-breeze,量子位,20秒

前方高能!
三模態聯合理解,文字描述+圖像定位+聲音定位,一鍵搞定,準確判斷聲音來源:
Audio-7-dork-bark,量子位,6秒

別著急,還沒完!
即使音頻和圖像之間沒有直接關系,也可以合理描述兩者之間的可能關系,看圖辨音講故事也可以:
Audio-11-six-oclock,量子位,1分鐘

這么一看,BuboGPT干點活,夠“細”的。
研究人員表示:
MiniGPT-4,LLaVA和X-LLM等最近爆火的多模態大模型未對輸入的特定部分進行基礎性連接,只構建了粗粒度的映射。
而BuboGPT利用文本與其它模態之間豐富的信息且明確的對應關系,可以提供對視覺對象及給定模態的細粒度理解。
因此,當BuboGPT對圖像進行描述時,能夠指出圖中對象的具體位置。

BuboGPT:首次將視覺連接引入LLM
除了上面作者分享在YouTube的示例,研究團隊在論文中也展示了BuboGPT玩出的各種花樣。
活久見青蛙彈琴!這樣的圖BuboGPT也能準確描述嗎?

一起康康回答得怎么樣:

不僅能夠準確描述青蛙的姿勢,還知道手摸的是班卓琴?
問它圖片都有哪些有趣的地方,它也能把圖片背景里的東西都概括上。
BuboGPT“眼力+聽力+表達力測試”,研究人員是這樣玩的,大家伙兒先來聽這段音頻。
Audio-9-hair-dryer,量子位,5秒
再來看看BuboGPT的描述怎么樣:

圖片上的人的性別、聲音來源、圖片中發生的事情,BuboGPT都能準確理解。
效果這么好,是因為字節這次用了將視覺定位引入LLM的方法。
具體方法我們接著往下看。
BuboGPT的架構是通過學習一個共享的語義空間,并進一步探索不同視覺對象和不同模態之間的細粒度關系,從而實現多模態理解。
為探索不同視覺對象和多種模態之間的細粒度關系,研究人員首先基于SAM構建了一個現成的視覺定位pipeline。
這個pipeline由標記模塊(Tagging Module)、定位模塊(Grounding Module)和實體匹配模塊(Entity-matching Module)三個模塊組成。

流程大概是這樣嬸兒的:
首先,標記模塊是一個預訓練模型,可以生成與輸入圖像相關的多個文本標簽。
基于SAM的定位模塊進一步定位圖像上與每個文本標簽相關的語義掩模或邊界框。
然后,實體匹配模塊利用LLM的推理能力從標簽和圖像描述中檢索匹配的實體。
研究人員就是通過這種方式,使用語言作為橋梁將視覺對象與其它模態連接起來。
為了讓三種模態任意組合輸入都能有不錯的效果,研究人員采用了類似于Mini-GTP4的兩階段走訓練方案:
單模態預訓練和多模態指令調整。

具體而言,BuboGPT使用了ImageBind作為音頻編碼器,BLIP-2作為視覺編碼器,以及Vicuna作為預訓練LLM。
在單模態預訓練階段,在大量的模態-文本配對數據上訓練相應的模態Q-Former和線性投影層。
對于視覺感知,研究人員僅對圖像標題生成部分進行投影層的訓練,并且保持來自BLIP2的Q-Former固定。
對于音頻理解,他們同時訓練了Q-Former和音頻標題生成部分。
在這兩種設置下都不使用任何提示(prompt),模型僅接收相應的圖像或音頻作為輸入,并預測相應的標題(caption)。

△不同輸入的指令遵循示例
在多模態指令調整階段,構建了一個高質量的多模態指令數據集對線性投影層進行微調,包括:
- 圖像-文本:使用MiniGPT-4和LLaVa中的兩個數據集進行視覺指令調優。
- 音頻-文本:基于Clotho數據集構建了一系列表達性和描述性數據。
- 音頻-圖像-文本:基于VGGSS數據集構建了<音頻,圖像,文本>三模態指導調優數據對,并進一步引入負樣本來增強模型。
值得注意的是,通過引入負樣本“圖像-音頻對”進行語義匹配,BuboGPT可以更好地對齊,多模態聯合理解能力更強。
目前BuboGPT代碼、數據集已開源,demo也已發布啦,我們趕緊上手體驗了一把。
demo淺玩體驗
BuboGPT demo頁面功能區一目了然,操作起來也非常簡單,右側可以上傳圖片或者音頻,左側是BuboGPT的回答窗口以及用戶提問窗口:
上傳好照片后,直接點擊下方第一個按鈕來上傳拆分圖片:

就拿一張長城照片來說,BuboGPT拆成了這個樣子,識別出了山、旅游勝地以及城墻:

當我們讓它描述一下這幅圖時,它的回答也比較具體,基本準確:

可以看到拆分框上的內容也有了變化,與回答的文本內容相對應。
再來一張圖片,并帶有一段音頻,BuboGPT也正確匹配了聲音來源:
Audio-8-bicycle_bell,量子位,22秒
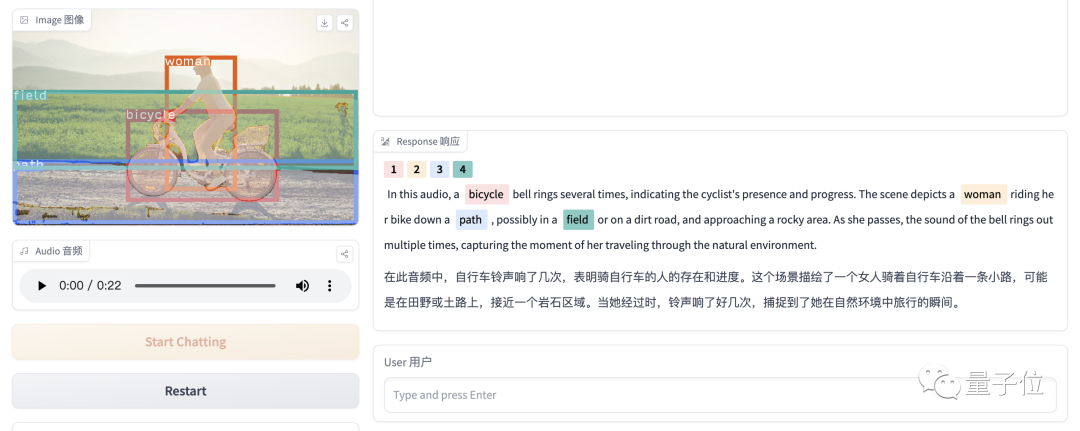
當然,它也會出現識別不成功,表述錯誤的情況,比如說下面這張圖中并沒有人,音頻也只是鐘聲,但它的描述和圖片似乎并不搭邊。

感興趣的家人趕緊親自上手試試~~
傳送門:
[1]https://bubo-gpt.github.io/
[2]https://huggingface.co/spaces/magicr/BuboGPT(demo)