ImageNet-D 詳解:嚴格評估神經網絡的魯棒性
神經網絡在零樣本圖像分類中取得了驚人的成就,但它們真的能“看”得有多好呢?現有的用于評估這些模型魯棒性的數據集僅限于網絡上的圖像或通過耗時且資源密集的手動收集創建的圖像。這使得系統評估這些模型在面對未見數據和真實世界條件(包括背景、紋理和材質的變化)時的泛化能力變得困難。一個可行的解決方案是在合成生成的圖像上評估模型,例如ImageNet-C、ImageNet-9或Stylized-ImageNet。
然而,這些數據集依賴于特定的合成損壞、背景和紋理;此外,它們的變化有限,缺乏真實的圖像質量。

ImageNet-D與其他合成圖像數據集的對比示例
這些模型變得如此強大,以至于在這些合成圖像數據集中實現了極高的準確性,這也帶來了額外的挑戰。
ImageNet-D
ImageNet-D是一個通過擴散模型生成的新基準,解決了這些局限性,通過具有挑戰性的圖像將模型推向極限,并揭示模型魯棒性的關鍵缺陷。
- 它由4,835張“困難圖像”組成。
- ImageNet-D涵蓋了ImageNet和ObjectNet之間的113個重疊類別。
- 該數據集包含547種干擾變化,包括廣泛的背景(3,764種)、紋理(498種)和材質(573種),使其比之前的基準更加多樣化。通過系統地改變這些因素,ImageNet-D全面評估了模型是否能夠真正“看到”圖像表面特征之外的內容。
從“真實世界數據的復雜性”轉向像ImageNet-D這樣的合成數據集可能看起來違反直覺,但它解決了評估神經網絡魯棒性時的關鍵局限性。
為什么合成數據集具有優勢?
- 需要系統性控制:真實世界的數據本質上是不可控的。如果你想測試神經網絡對背景、紋理或材質變化的響應,很難系統地創建或找到包含所有所需組合的真實世界數據。
- 合成數據提供控制性和可擴展性:ImageNet-D利用擴散模型生成合成圖像,克服了真實世界數據的局限性。這種方法使研究人員能夠系統地控制并高效擴展數據集,探索比僅使用真實圖像更廣泛的變化范圍。通過擴散模型,ImageNet-D可以生成比現有數據集更多樣化的背景、紋理和材質的圖像。
- 專注于“困難”示例:ImageNet-D使用困難圖像挖掘過程,選擇性地保留導致多個視覺模型失敗的圖像。通過關注當前模型的弱點,ImageNet-D提供了更具信息量的評估。
- 通過人工驗證進行質量控制:雖然是合成的,但ImageNet-D并未犧牲質量。通過嚴格的質量控制流程,包括人工標注者,確保生成的圖像是有效的、單一類別的且高質量的。
擴散模型的圖像生成

ImageNet - D 的創建框架
ImageNet-D的創建框架涉及幾個關鍵步驟,利用Stable Diffusion和困難圖像挖掘策略。生成過程公式為:Image(C,N) = Stable Diffusion(Prompt(C, N)),其中C是對象類別,N表示背景、材質和紋理等干擾因素。

用于創建合成圖像的提示詞格式
- 通過在擴散模型的提示詞中將每個物體與所有干擾因素進行配對來生成圖像,這些干擾因素使用了來自 Broden 數據集的 468 種背景、47 種紋理和 32 種材質。
- 每張圖像都以其提示詞類別 C 作為分類的真實標簽進行標注。
- 如果模型預測的標簽與真實標簽 C 不匹配,則該圖像被視為分類錯誤。
困難圖像挖掘與共享感知失敗
ImageNet-D的困難圖像挖掘策略旨在識別和選擇最具挑戰性的圖像,以評估神經網絡的魯棒性。其目標是創建一個測試集,將視覺模型推向極限,暴露它們的弱點和失敗點。
- 共享感知失敗:核心概念是“共享失敗”,即當一張圖像導致多個模型錯誤預測對象標簽時發生。其原理是,導致不同模型共享失敗的圖像可能本質上更具挑戰性,對評估魯棒性更具信息量。
- 代理模型:為了識別這些困難圖像,使用一組預先建立的視覺模型作為“代理模型”。這些模型充當代理,估計圖像對其他潛在未知“目標模型”的難度。
挖掘過程
- 如前文所述,使用擴散模型生成大量合成圖像。
- 在生成的圖像上運行每個替代模型,并記錄其預測結果。
- 找出多個替代模型未能正確預測物體標簽的圖像。這些圖像被標記為潛在的 “難例”。
- ImageNet - D 測試集就是利用這些替代模型的共同錯誤構建而成。最終的 ImageNet - D 是通過 4 個替代模型的共同錯誤創建的。
其結果是一個精心設計的過程,通過選擇能夠暴露多個視覺模型共同弱點的合成圖像,來創建一個具有挑戰性且信息豐富的基準測試。
質量控制:人工參與
人工參與的組件對于驗證ImageNet-D數據集的質量和準確性至關重要,確保圖像被正確標注并適合評估神經網絡的魯棒性。
雖然擴散模型和難例圖像挖掘能夠生成并選擇具有挑戰性的圖像,但人工標注對于完善數據集同樣必不可少。人工標注確保 ImageNet - D 圖像有效、屬于單類別且質量較高。由于 ImageNet - D 包含各種可能不常見的物體和干擾因素組合,標注標準會考慮主要物體的外觀和功能。
679 名合格的亞馬遜土耳其機器人(Mechanical Turk)工人參與了 1540 項標注任務,在從 ImageNet - D 中抽取的圖像上達成了 91.09% 的一致性。工人需要考慮以下問題:
- 你能在圖像中識別出目標物體([真實類別])嗎?
- 圖像中的物體可以用作目標物體([真實類別])嗎?
為保持高質量的標注,在每個標注任務中都加入了哨兵樣本。這些樣本包括:
- 正哨兵樣本:明確屬于目標類別的圖像,且被多個模型正確分類。
- 負哨兵樣本:不屬于目標類別的圖像。
- 一致性哨兵樣本:隨機重復出現的圖像,用于檢查工人回答的一致性。
未通過哨兵樣本檢查的工人回復將被丟棄。
如何使用和解釋結果
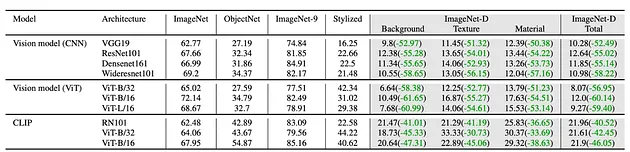
在ImageNet-D上測試模型后,如何解釋結果并獲取有關模型優勢和劣勢的寶貴見解?
- 較低的準確性表明缺乏魯棒性:如果你的模型在ImageNet-D上的表現明顯低于ImageNet等標準基準,則表明它在面對背景、紋理和材質變化時難以泛化。這意味著模型可能依賴于表面特征,而不是真正“理解”對象。
- 與其他模型進行比較:單一的準確性分數信息有限。為了評估模型的魯棒性,將其在ImageNet-D上的表現與其他模型進行比較。這將幫助你了解其相對地位,并突出其表現優異或落后的領域。
- 分析失敗案例:不要只看整體準確性,還要分析模型失敗的特定圖像。是否存在某些背景始終導致錯誤分類?模型是否容易被不尋常的紋理或材質迷惑?通過分析這些失敗案例,你可以識別模型的具體弱點,并針對性地改進。
下一步如果你有興趣探索該數據集,我已將其解析為FiftyOne格式并上傳到Hugging Face。通過幾行代碼,你可以下載并開始探索數據集。
import fiftyone as fo
import fiftyone.utils.huggingface as fouh
dataset = fouh.load_from_hub("Voxel51/ImageNet-D")
# Launch the App
session = fo.launch_app(dataset)結論
通過結合擴散模型的合成圖像生成、系統性的困難圖像挖掘和嚴格的人工驗證,ImageNet-D提供了一個比以往數據集更全面、更具挑戰性的基準。
ImageNet-D測試的結果可以揭示模型對視覺概念的真正理解,而不僅僅是表面級別的模式匹配。
隨著視覺模型的進步,評估其局限性的可靠方法變得越來越重要。ImageNet-D幫助識別這些局限性,并為開發更魯棒的模型提供了途徑,這些模型能夠更好地處理真實世界中的外觀、背景和上下文變化。對于計算機視覺的研究人員和從業者來說,ImageNet-D不僅僅是一個基準,它是一個寶貴的工具,用于理解和改進人工神經網絡如何“看”和解釋視覺世界。
數據集鏈接:https://github.com/chenshuang-zhang/imagenet_d