













擴散模型新突破!無需微調,就能高效穩定移除目標物體
本文的共同第一作者為浙江工商大學統計與數學學院碩士生孫文灝和阿里巴巴算法工程師崔奔雷,本文的通訊作者為浙江工商大學統計與數學學院董雪梅教授。
最近,擴散模型在生成模型領域異軍突起,憑借其獨特的生成機制在圖像生成方面大放異彩,尤其在處理高維復雜數據時優勢明顯。然而,盡管擴散模型在圖像生成任務中表現優異,但在圖像目標移除任務中仍然面臨諸多挑戰。現有方法在移除前景目標后,可能會留下殘影或偽影,難以實現與背景的自然融合。
為了解決這些問題,本文提出了一種基于擴散模型且無需微調的方法 ——Attentive Eraser,以增強預訓練擴散模型目標移除的能力,從而實現穩定有效的目標移除。實驗結果表明,該方法在多種預訓練擴散模型中均表現出優異的目標移除能力,甚至優于基于訓練的方法,且無需微調,具有很強的可擴展性。
該研究論文已被人工智能頂會 AAAI 2025 錄用并選為 Oral Presentation。

- 論文標題:Attentive Eraser: Unleashing Diffusion Model's Object Removal Potential via Self-Attention Redirection Guidance
- 論文鏈接:https://arxiv.org/pdf/2412.12974
- Github 地址:https://github.com/Anonym0u3/AttentiveEraser
- Diffusers Pipeline:https://github.com/huggingface/diffusers/tree/main/examples/community#stable-diffusion-xl-attentive-eraser-pipeline
- Model Scope Demo:https://www.modelscope.cn/studios/Anonymou3/AttentiveEraser
- Hugging Face Demo:https://huggingface.co/spaces/nuwandaa/AttentiveEraser
問題背景
目前,擴散模型的廣泛應用使得生成與真實照片質量相媲美的高質量圖像成為可能,并能夠根據用戶的需求提供逼真的視覺呈現。這引發了一個自然的問題:這些模型的圖像生成能力是否可以被用于從圖像中移除特定目標。這個被稱為 “目標移除” 的任務是圖像重繪(Image Inpainting)的一種特殊形式,并需要解決兩個關鍵問題。首先,用戶指定的目標必須能夠被成功且有效地從圖像中移除。其次,被移除的區域需要填充內容,這些內容必須真實、合理,并與圖像整體保持一致性以確保視覺上的連貫性。
近年來擴散模型中最具代表性的開源預訓練模型是 Stable Diffusion(SD),其作為一種隱變量擴散模型在多種圖像生成任務中表現優異。然而,直接將其應用在重繪 pipeline 上進行目標移除時效果卻不盡人意,往往會出現偽影導致目標移除不成功,如圖 1(SD w/o SARG)所示:

圖 1 Stable Diffusion 模型應用 SARG 前后目標移除效果對比圖
為了將 SD 應用于目標移除任務,SD-inpainting 通過在模型中引入掩碼作為附加條件并進行微調,構建成了一個端到端的圖像重繪模型。然而,即使付出了大量資源成本,SD-inpainting 在目標移除任務中的性能依然不夠穩定,經常無法完全移除目標,還是會生成隨機偽影。除了基于模型微調的方法外,還有一種通過提示工程(prompt engineering)引導擴散模型完成目標移除的技術。盡管這類方法在某些場景下可以取得令人滿意的結果,但其顯著缺點在于,需要投入大量精力進行提示構建,同時難以與前景目標區域實現精確交互。此外,這類方法同樣需要耗費大量資源進行模型微調,進一步限制了其實用性。
為了解決上述問題,本文提出了一種基于擴散模型且無需微調的目標移除方法,具體貢獻如下:
(1)本文提出了一種無需微調的方法 ——Attentive Eraser,旨在激發預訓練擴散模型的目標移除潛能。該方法由兩個關鍵組成部分構成:1)注意力激活和抑制(Attention Activation and Suppression,AAS),這是一種專門設計用于修改預訓練擴散模型中自注意力機制的方法,可在生成圖像時增強模型對背景的注意力,同時降低對前景目標物體的注意力。同時針對生成過程中自注意力本身帶來的對相似物體的高依賴性問題,本文提出了相似性抑制(Similarity Suppression,SS),有效地解決了該問題。2)自注意力重定向引導(Self-Attention Redirection Guidance,SARG),這是一種新穎的逆向擴散采樣過程引導方法,利用所提出的 AAS 將采樣過程引導到目標移除的方向,進一步提升了目標移除的效果。
(2)通過一系列實驗和用戶偏好研究,本文驗證了所提出方法的有效性、魯棒性和可擴展性。實驗結果表明,本文的方法在目標移除的質量和穩定性方面均超越了現有的最先進方法。
AttentiveEraser 核心創新
本文提出的 Attentive Eraser 免微調目標移除方法的總體框架圖如圖 2 所示,其中有兩個主要部分:(a)AAS,這是一種專為目標移除任務設計的自注意力機制修改操作,針對目標移除任務中固有的挑戰,AAS 通過對自注意力機制進行精細調整,使得模型在生成前景目標區域時能夠更加關注背景內容,而非前景目標,進而在生成結果圖中消除目標的外觀信息。此外,SS 可抑制由于自注意力的固有特性而可能導致的對相似物體的過度關注;(b)SARG,這是一種應用于逆向擴散采樣過程的引導方法,它利用通過 AAS 重定向的自注意力來引導采樣過程指向目標移除的方向。在這種引導下,擴散模型能夠更好地消除掩碼區域內的前景目標,并生成與背景自然融洽的圖像內容。
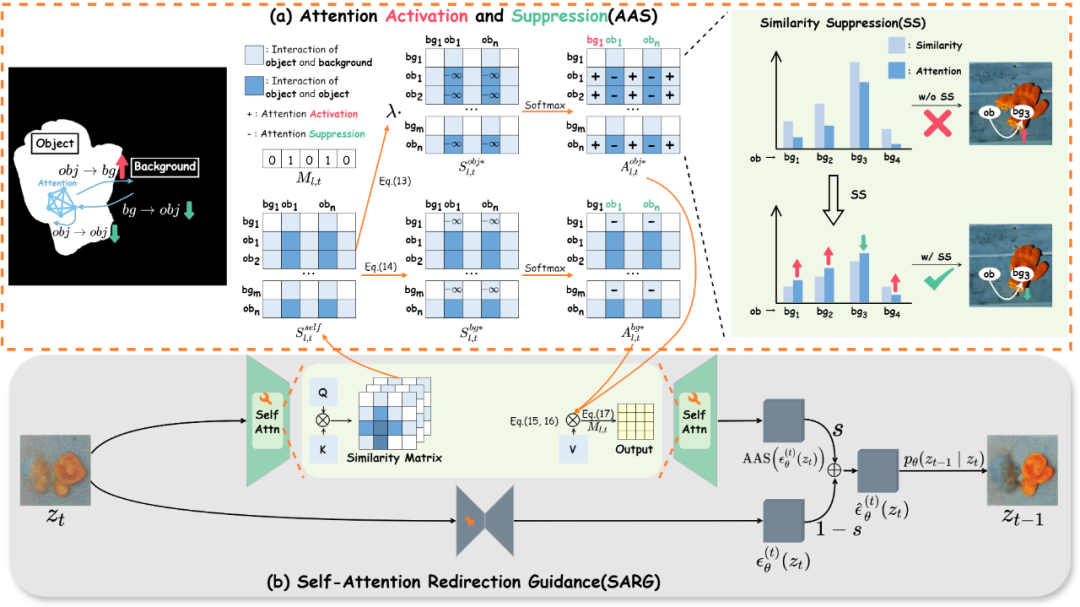
圖 2 Attentive Eraser 的總體框架圖
創新一:注意力抑制與激活(AAS)
動機分析

圖 3 去噪網絡不同層在所有時間步上的平均自注意力圖的可視化圖
圖 3 中,在輸入圖像經過 DDIM inversion 后,利用主成分分析和聚類技術,對逆向擴散去噪過程中去噪網絡的不同層在所有時間步上的平均自注意力圖進行了可視化。通過這些可視化結果,可以觀察到自注意力圖顯示出類似于圖像各個組成部分的語義布局。這種布局清晰地展示了前景物體和背景在生成過程中所對應的自注意力的顯著差異,表明它們在模型中的處理方式存在明確的區分。這種語義布局為目標移除任務提供了重要的啟示,為了在生成過程中有效地去除前景目標,一個直觀的方法是在生成過程中將前景物體的自注意力逐漸 “融合” 到背景中,使其與背景區域的注意力更加趨同。換句話說,在生成過程中與前景目標相關的區域應更關注背景區域,同時減少對自身的關注。前景目標的自注意力逐漸向背景轉移有助于消除前景物體,使其自然地消隱于背景之中。此外,考慮到目標移除任務的特殊性,前景目標是處理的核心,背景區域應在生成過程中保持固定不變,且不受前景區域變化的影響。因此,為了實現更自然的生成效果,背景區域對前景區域的關注度也應適當地降低,從而避免生成過程中背景被不必要地干擾。這一策略確保了生成結果與背景的自然融合,使生成圖像顯得更加和諧、真實。
專為目標移除設計的自注意力機制修改方法
結合上述分析,本文提出了一種針對目標移除任務設計的簡單而有效的方法 ——AAS,如圖 2(a)所示,AAS 方法的核心在于通過調整自注意力機制,靈活控制前景目標區域與背景區域之間的關系,從而實現更為自然的目標移除效果。
注意力激活的目的是通過增加前景目標區域生成內容對背景區域的注意力,即增加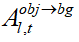 ,從而確保前景目標被移除后,生成的內容能夠與背景自然融合。這一過程的關鍵在于增強前景區域生成內容對背景的關注度,使得前景區域在生成過程中更多地參考背景的特征信息,進而生成與背景風格一致的圖像內容。這種增強能夠有效地避免前景移除后出現與背景不協調的情況,確保生成圖像的整體連貫性和視覺一致性。
,從而確保前景目標被移除后,生成的內容能夠與背景自然融合。這一過程的關鍵在于增強前景區域生成內容對背景的關注度,使得前景區域在生成過程中更多地參考背景的特征信息,進而生成與背景風格一致的圖像內容。這種增強能夠有效地避免前景移除后出現與背景不協調的情況,確保生成圖像的整體連貫性和視覺一致性。
與此相反,注意力抑制是指抑制前景目標區域關于其外觀及其對背景影響的信息,即減少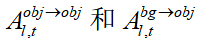 ,達到抹除前景目標的效果。降低
,達到抹除前景目標的效果。降低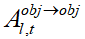 的目的是抑制前景區域對自身外觀信息的關注,逐步抹除前景目標的原始語義信息。這意味著在逆向擴散去噪過程中,前景目標的特征信息將被逐步削弱直至完全消失而背景區域的生成過程則保持不變,以確保背景的完整性。此外,降低
的目的是抑制前景區域對自身外觀信息的關注,逐步抹除前景目標的原始語義信息。這意味著在逆向擴散去噪過程中,前景目標的特征信息將被逐步削弱直至完全消失而背景區域的生成過程則保持不變,以確保背景的完整性。此外,降低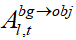 的作用在于減少背景區域對前景區域的依賴,避免背景區域在前景移除過程中受到不必要的影響。
的作用在于減少背景區域對前景區域的依賴,避免背景區域在前景移除過程中受到不必要的影響。
相似性抑制
盡管上述理論在目標移除任務中展現了顯著的效果,但其仍存在一個重要的局限性。具體而言,當背景中包含與前景目標相似的內容時,由于自注意力機制的固有特性,在生成過程中這些相似部分的注意力可能會高于其他區域。這種情況會導致擴散模型在去除前景目標時,誤將背景中相似的部分保留,從而無法徹底去除目標(見圖 2(a)右側的一個例子)。這一問題的存在表明,單純依靠上述理論可能不足以應對復雜場景中具有相似特征的前景和背景目標的區分與處理。
因此,為了減少對相似目標的關注并將其分散到其他區域,本文提出了一種較為直接且有效的擴展策略引入到 AAS 中來解決上述問題:通過簡單地引入一個小于 1 的相似性抑制系數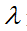 來降低相似性矩陣
來降低相似性矩陣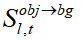 方差。本文將該方法稱為相似性抑制(SS)。基于 SoftMax 函數的權重計算機制,減少
方差。本文將該方法稱為相似性抑制(SS)。基于 SoftMax 函數的權重計算機制,減少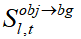 方差可以在一定程度上削弱生成過程過度關注高相似度區域的傾向,同時增加對背景其他區域的注意力,由此來抑制生成過程中可能出現的相似物體,從而減少目標去除不徹底的情況。
方差可以在一定程度上削弱生成過程過度關注高相似度區域的傾向,同時增加對背景其他區域的注意力,由此來抑制生成過程中可能出現的相似物體,從而減少目標去除不徹底的情況。
創新二:自注意力重定向引導(SARG)
為了進一步提高目標去除能力以及生成圖像的整體質量,本文受 Ahn 等人提出的 PAG(PAG:Ahn D, Cho H, Min J, et al. Self-rectifying diffusion sampling with perturbed-attention guidance [C]. European Conference on Computer Vision. Springer, Cham, 2025: 1-17.)啟發,將經過 AAS 處理后的去噪網絡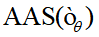 看作是噪聲
看作是噪聲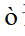 預測過程中的一種擾動形式,通過這種擾動來引導采樣過程朝向理想方向。因此,修正后的擴散模型的預測噪聲可以定義如下:
預測過程中的一種擾動形式,通過這種擾動來引導采樣過程朝向理想方向。因此,修正后的擴散模型的預測噪聲可以定義如下:
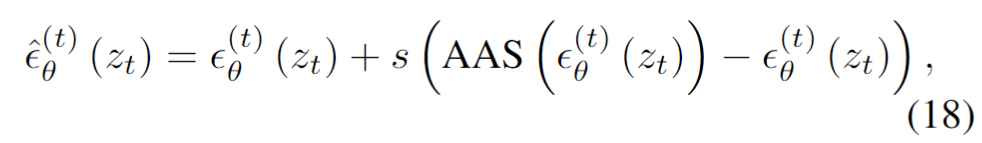
這種引導過程的優勢在于,通過調整自注意力機制,SARG 能夠在生成過程中不斷優化生成策略,使模型更加靈活地適應不同場景下的目標移除需求。同時,通過優化生成過程的各個時間步,SARG 還提高了最終生成圖像的質量,通過合理地控制生成過程中的注意力分配,SARG 確保了最終生成圖像與背景之間的自然融合,減少了它們之間的突兀感,從而提高了圖像的視覺一致性和自然度,確保了高質量的目標移除效果。
實驗亮點:AttentiveEraser 的穩定目標擦除能力及高拓展性
對比實驗的定量和定性結果
表 1 對比實驗定量結果表
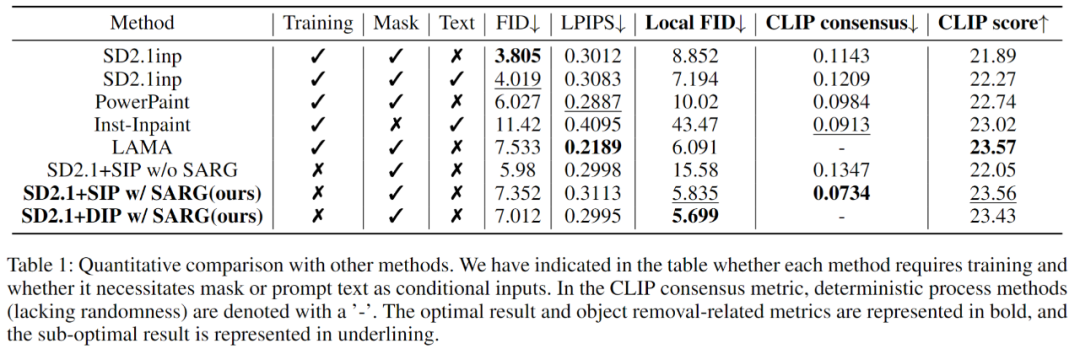
從定量分析的結果來看,盡管在全局質量指標 FID 和 LPIPS 上,本文的方法表現處于平均水平,但這兩個指標并不能充分反映目標去除的效果。進一步分析 Local-FID 指標,該指標評估生成區域的視覺質量與背景的真實分布的吻合程度,可以看到我們的方法在局部移除方面展現出色的表現,顯著優于其他方法,說明在局部區域細節上我們方法生成的內容與真實圖像分布更接近。同時,CLIP consensus 指標通過計算多次生成結果的標準偏差,揭示了方法在不同隨機種子下生成結果的一致性。從結果可以明顯看到其他基于擴散模型的方法的標準偏差較大,說明了它們應用在目標移除任務時的不穩定性,而我們的結果展現了顯著更低的標準偏差,說明我們方法的穩定性顯著優于對比方法,更傾向于生成一致性高的圖像。而 CLIP Score 指標直接反映目標是否被有效去除且背景是否被合理重建,實驗結果表明我們的方法能夠高效地去除目標,并在重繪前景區域時與背景高度一致。在 CLIP Score 指標上,我們的方法與當前領先的基于快速傅立葉卷積的重繪模型 LAMA 達到了相當的競爭水平,并在特定場景中表現出更強的背景適配能力。

圖 4 對比實驗定性結果圖

圖 5 目標移除穩定性實驗結果對比圖
對比實驗的定性結果如圖 4 所示,其中輸入圖像中的掩碼以紅色高亮顯示,本文的方法以粗體標出。從圖中可以觀察到本文的方法與其他方法之間的顯著差異。LAMA 由于缺乏生成能力,雖然能成功去除目標,但生成的內容顯得模糊且不清晰。相比之下,其他基于擴散模型的方法都存在一個普遍的問題,即目標移除的不穩定性,這種不穩定性往往導致隨機偽影的出現,無法生成與背景連貫一致的內容。為了進一步證實這一問題,本文進行了目標移除穩定性實驗,結果如圖 5 所示。圖中展示了每種方法在使用三種不同隨機種子下的目標移除結果。可以清楚地看到,本文的方法在各個版本的 SD 模型中都能實現穩定的目標移除,生成的內容一致且連貫。而其他方法則難以保持這種穩定性,目標移除效果因隨機性而產生較大的波動,難以實現與背景一致的生成效果。
用戶偏好研究和 GPT-4o 評估
表 2 用戶偏好研究和 GPT-4o 評估結果表
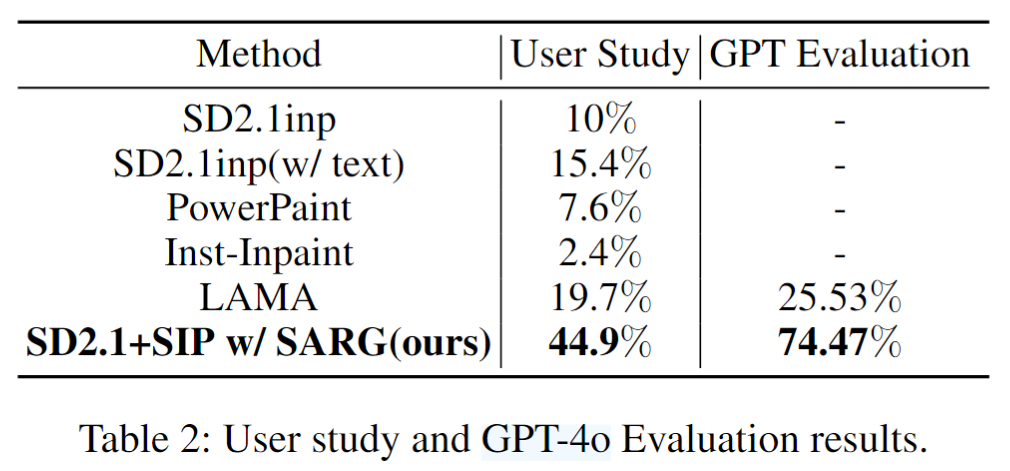
由于缺乏針對目標移除任務的有效指標,上述指標可能不足以證明本文方法的優越性。因此,本文進一步進行了用戶偏好研究(User Study)以驗證本文方法的實際效果。表 2 列出了用戶對各種方法的偏好百分比,結果表明本文的方法比其他方法更受用戶青睞。這一發現與對比試驗的結果一致,進一步驗證了本文方法在目標移除任務中的有效性和優越性,突出表明該方法在實際應用中的表現優于其他現有方法。
此外為了進一步表明本文提出方法的優越性,我們還利用 GPT-4o 對本文的方法和用戶偏好研究中排名第二方法 LAMA 之間的目標移除性能進行了進一步評估。在該對比實驗中,我們要求 GPT-4o 根據設計好的公平合理的文本提示選擇目標移除效果最佳的圖像。具體的文本提示如下:“你是一個生成圖像評估專家。現有兩張圖和對應的掩碼,請從以下方面進行評估:1. 生成圖像是否有效移除了掩碼內目標且在掩碼區域內生成和背景一致的內容,2. 掩碼內目標的生成內容的真實感。根據以上標準,請告訴我哪張圖片更好。” 最終,計算了本文的方法和 LAMA 被選擇的頻率,以此衡量各自的目標移除性能。評估結果在表 2 中,結果也表明本文的方法明顯優于 LAMA,表現出卓越的性能。通過這些實驗,本文的方法不僅在生成圖像的整體質量上優于 LAMA,還在目標移除的準確性和生成內容的真實感方面展現了顯著的優勢。
魯棒性和可拓展性分析

圖 6 Attentive Eraser 對輸入掩碼的魯棒性實驗結果圖

圖 7 在 solarsync 模型上應用 Attentive Eraser 去除卡通圖像目標的結果圖
由于 Attentive Eraser 是一個基于掩碼的方法,因此我們在實驗中進一步證明了其對輸入掩碼的魯棒性,并展示了其在其他預訓練擴散模型上的可拓展性。
如圖 6 所示,我們通過三種不同精細度的掩碼類型來評估該方法的魯棒性,按從細致到粗糙可以將掩碼分為:實例分割掩碼、分割邊界框掩碼和手繪掩碼。可以看出,即使使用較為粗糙的手繪掩碼,我們的方法依然能夠有效去除目標并生成合理的前景內容。這表明,Attentive Eraser 的性能并不依賴于掩碼的精細程度,具有極高的魯棒性。同時,這種魯棒性也為用戶提供了更多的靈活性和便捷性,無論是使用精細的自動生成的分割掩碼,還是手工繪制的粗略掩碼,用戶都能夠獲得理想的目標移除效果。
此外,如圖 7 所示,我們的方法不僅適用于生成自然圖像的預訓練擴散模型(例如 SD1.5、SD2.1 等),還可以擴展到生成動漫圖像的模型,如 Civital 平臺上的 solarsync 模型,體現出了 Attentive Eraser 在不同預訓練擴散模型和架構上的可拓展性和廣泛適用性,無論是用于自然圖像還是動漫圖像的目標移除任務,均能發揮出色的效果。
通過這些實驗,我們充分展示了 Attentive Eraser 的魯棒性和可拓展性,為其在實際應用中的廣泛應用提供了堅實的理論與實驗支持。
Demo 演示
- Demo 已發布在魔搭社區創空間及 Hugging Face spaces:
- https://www.modelscope.cn/studios/Anonymou3/AttentiveEraser
- https://huggingface.co/spaces/nuwandaa/AttentiveEraser

更多詳情,請參閱論文原文。






























