誰說強化學習只能是蛋糕上的櫻桃,說不定,它也可以是整個蛋糕呢?
誰說強化學習只能是蛋糕上的櫻桃,說不定,它也可以是整個蛋糕呢?

在 2016 年的一次演講中,Yann LeCun 曾將強化學習比喻成蛋糕上的櫻桃。他提到,「如果把智能比作一塊蛋糕,那么無監(jiān)督學習就是蛋糕的主體,監(jiān)督學習就是蛋糕上的糖霜,而強化學習則是糖霜上的櫻桃。我們已經(jīng)知道如何制作糖霜和櫻桃,但卻不知道如何制作蛋糕本身。」

從 2016 年至今,LeCun 對強化學習一直不看好。然而,不可否認的是,強化學習在提升 AI 模型能力方面正變得越來越重要。而且,來自微軟的一項新研究顯示,它不僅在后訓練階段發(fā)揮著關鍵作用,甚至在預訓練階段也展現(xiàn)出巨大的潛力。

在這篇題為「Reinforcement Pre-Training」的論文中,作者提出了一種名為「強化預訓練(RPT)」的新范式。在這種范式中,下一個 token 預測任務可以被重新定義為一個通過強化學習訓練的推理任務。在這一任務中,模型會因正確預測給定上下文中的下一個 token 而獲得可驗證的獎勵。

這就好比在制作蛋糕的過程中,直接將櫻桃融入到蛋糕的主體結(jié)構(gòu)中。


作者指出,RPT 范式的好處在于,它提供了一種可擴展的方法,能夠利用海量文本數(shù)據(jù)進行通用強化學習,而無需依賴特定領域的標注答案。
通過激勵模型進行下一個 token 的推理,RPT 顯著提升了預測下一個 token 的語言建模準確性。此外,RPT 為后續(xù)的強化微調(diào)提供了一個強大的預訓練基礎。
scaling 曲線表明,隨著訓練計算量的增加,下一個 token 預測的準確性持續(xù)提升。這些結(jié)果表明,RPT 是一種有效且有前景的 scaling 范式,能夠推動語言模型預訓練的發(fā)展。
不過,由于論文提出的方法比較新,社區(qū)對該方法的有效性、效率、前景等還有所疑問。



接下來,我們看文章內(nèi)容。
論文概覽

- 論文標題:Reinforcement Pre-Training
- 論文鏈接:https://www.arxiv.org/pdf/2506.08007
大語言模型(LLMs)通過在海量文本語料庫上采用可擴展的對下一個 token 的預測,展現(xiàn)出跨多種任務的卓越能力。這種自監(jiān)督范式已被證明是一種高效的通用預訓練方法。
與此同時,RL 已成為微調(diào)大語言模型的關鍵技術(shù),既能讓 LLM 符合人類偏好,又能提升諸如復雜推理等特定技能。
然而,目前 RL 在 LLM 訓練中的應用面臨著可擴展性和通用性方面的挑戰(zhàn)。
一方面,基于人類反饋的強化學習雖然在對齊方面有效,但依賴于昂貴的人類偏好數(shù)據(jù),而且其學習到的獎勵模型容易受到 reward hacking 攻擊,從而限制了其可擴展性。
另一方面,可驗證獎勵的強化學習 (RLVR) 利用客觀的、基于規(guī)則的獎勵,這些獎勵通常來自問答對。雖然這可以緩解 reward hacking 攻擊,但 RLVR 通常受限于數(shù)據(jù)的稀缺性,不能用于通用預訓練。
本文提出了強化預訓練(Reinforcement Pre-Training, RPT)這一新范式,旨在彌合可擴展的自監(jiān)督預訓練與強化學習能力之間的鴻溝。
RPT 將傳統(tǒng)的對 next-token 的預測任務重構(gòu)為對 next-token 的推理過程:對于預訓練語料中的任意上下文,模型需在預測前對后續(xù) Token 進行推理,并通過與語料真實的 next-token 比對獲得可驗證的內(nèi)在獎勵。
該方法無需外部標注或領域特定獎勵函數(shù),即可將傳統(tǒng)用于 next-token 預測的海量無標注文本數(shù)據(jù),轉(zhuǎn)化為適用于通用強化學習的大規(guī)模訓練資源。
這種方法提供了幾個關鍵的優(yōu)點。
首先,RPT 具有固有的可擴展性和通用性:該方法充分利用了傳統(tǒng) next-token 預測所使用的海量無標注文本數(shù)據(jù),無需任何外部標注,即可將其轉(zhuǎn)化為適用于通用強化學習的大規(guī)模訓練數(shù)據(jù)集。
其次,使用直接的、基于規(guī)則的獎勵信號本質(zhì)上可以最大限度地降低 reward hacking 風險。
第三,通過明確獎勵 next-token 推理范式,讓模型能夠進行更深入的理解和泛化,而不僅僅是記住下一個 Token。
最后,預訓練期間的內(nèi)部推理過程允許模型為每個預測步驟分配更多的思考(計算資源),這類似于將推理時間擴展能力提前應用到訓練過程中,從而直接提升下一 Token 預測的準確性。
強化預訓練(RPT)詳解
Next-Token 預測與 Next-Token 推理對比如下。

在 Next-Token 推理范式下,長思維鏈可以包含各種推理模式,例如自我批評和自我修正。
Next-Token 推理將預訓練語料庫重構(gòu)為一系列龐大的推理問題,使預訓練不再局限于學習表面的 Token 級關聯(lián),而是理解其背后的隱藏知識。
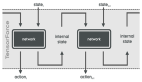
RPT 通過 on-policy 強化學習的方式訓練大語言模型執(zhí)行 next-token 推理任務,如圖 3 所示。

對于給定的上下文 ,提示語言模型
,提示語言模型 生成 G 個響應(思維軌跡)
生成 G 個響應(思維軌跡) 。每個響應
。每個響應 由一系列思維推理序列
由一系列思維推理序列 和最終預測序列
和最終預測序列  組成。
組成。
此外,為了驗證 的正確性,本文還引入了前綴匹配獎勵(prefix matching reward)。
的正確性,本文還引入了前綴匹配獎勵(prefix matching reward)。
對于 的第 i 個輸出的獎勵
的第 i 個輸出的獎勵  定義為:
定義為:

實驗設置。本文使用 OmniMATH 數(shù)據(jù)集進行強化預訓練,其包含 4,428 道競賽級數(shù)學題目及答案。實驗基礎模型為 Deepseek-R1-Distill-Qwen-14B。
實驗結(jié)果
語言建模能力
表 1 顯示了 RPT 方法和基線方法在不同難度級別測試集上的下一個 token 預測準確性。結(jié)果顯示,RPT 在與標準下一個 token 預測基線和基于推理的預測基線對比時均表現(xiàn)更優(yōu)。
具體來說,與 R1-Distill-Qwen-14B 相比,RPT-14B 在所有難度級別上都具有更高的下一個 token 預測準確率。

值得注意的是,它的性能與一個更大的模型的性能相媲美,即 R1-Distill-Qwen-32B(圖 4)。這些結(jié)果表明,強化預訓練在捕獲 token 生成背后的復雜推理信號方面是有效的,并且在提高 LLM 的語言建模能力方面具有強大的潛力。

強化預訓練的 scaling 特性
如圖 5 所示,RPT 的下一個 token 預測準確率隨著訓練計算的擴大而可靠地提高。所有難度級別的高 R2 值表明擬合曲線準確地捕捉了性能趨勢。

在 RPT 基礎上進行強化微調(diào)
如表 2 所示,經(jīng)過強化預訓練的模型在進一步使用 RLVR 進行訓練時能夠達到更高的性能上限。當模型持續(xù)使用下一個 token 預測目標在相同數(shù)據(jù)上進行訓練時,其推理能力顯著下降。隨后的 RLVR 訓練僅能帶來緩慢的性能提升。這些結(jié)果表明,在數(shù)據(jù)有限的情況下,強化預訓練能夠快速將從下一個 token 推理中學到的強化推理模式遷移到下游任務中。

零樣本性能
如表 3 所示,RPT-14B 在所有基準測試中始終優(yōu)于 R1-Distill-Qwen-14B。值得注意的是,RPT-14B 在 next-token 預測方面也超越了規(guī)模更大得多的 R1-Distill-Qwen-32B。

Next-Token 推理模式分析
如圖 6 所示,RPT-14B 的 next-token 推理過程與 R1-Distill-Qwen-14B 的問題解決過程明顯不同。表明 next-token 推理引發(fā)的推理過程與結(jié)構(gòu)化問題解決存在質(zhì)的差異。

最后,本文還在表 4 中提供了一個推理模式的示例。他們表明,RPT-14B 參與的是深思熟慮的過程,而非簡單的模式匹配。