技術分享:數據不平衡問題
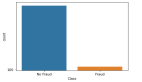
在學術研究與教學中,很多算法都有一個基本假設,那就是數據分布是均勻的。當我們把這些算法直接應用于實際數據時,大多數情況下都無法取得理想的結果。因為實際數據往往分布得很不均勻,都會存在“長尾現象”,也就是數據不平衡”。
以下幾種方法是針對數據不平衡問題所做的處理,具體包括:
- smote采樣
- adasyn采樣
- 欠采樣
- 一分類
- 改進的adaboost方法
一、smote采樣
SMOTE全稱是Synthetic Minority Oversampling Technique即合成少數類過采樣技術,它是基于隨機過采樣算法的一種改進方案,由于隨機過采樣采取簡單復制樣本的策略來增加少數類樣本,這樣容易產生模型過擬合的問題,即使得模型學習到的信息過于特別(Specific)而不夠泛化(General),SMOTE算法的基本思想是對少數類樣本進行分析并根據少數類樣本人工合成新樣本添加到數據集中,算法流程如下。
- 對于少數類中每一個樣本x,以歐氏距離為標準計算它到少數類樣本集中所有樣本的距離,得到其k近鄰。
- 根據樣本不平衡比例設置一個采樣比例以確定采樣倍率N,對于每一個少數類樣本x,從其k近鄰中隨機選擇若干個樣本,假設選擇的近鄰為xn。
- 對于每一個隨機選出的近鄰xn,分別與原樣本按照如下的公式構建新的樣本 xnew=x+rand(0,1)∗|x−xn|
部分代碼如下:
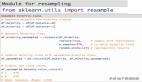
- df=get_data()
- x, y = load_creditcard_data(df)
- X_resampled_smote, y_resampled_smote = SMOTE().fit_sample(x, y) # print(y_resampled_smote)
- X_train, X_test, y_train, y_test = train_test_split(X_resampled_smote, y_resampled_smote, test_size=0.3,random_state=0)
二、adasyn采樣
本文介紹的是 ADASYN: 自適應綜合過采樣方法。
算法步驟如下:
(1)計算不平衡度
記少數類樣本為ms,多數類為ml,則不平衡度為 d = ms / ml,則d∈(0,1]。(作者在這里右邊用了閉區間,我覺得應該用開區間,若是d = 1,則少數類與多數類樣本數量一致,此時數據應該平衡的)
(2)計算需要合成的樣本數量
G = (ml - ms)* b,b∈[0,1],當b = 1時,即G等于少數類和多數類的差值,此時合成數據后的多數類個數和少數類數據正好平衡
(3)對每個屬于少數類的樣本用歐式距離計算k個鄰居,為k個鄰居中屬于多數類的樣本數目,記比例r為r = / k,r∈[0,1]
(4)在(3)中得到每一個少數類樣本的 ri ,
用 計算每個少數類樣本的周圍多數類的情況
(5)對每個少數類樣本計算合成樣本的數目 (6)在每個待合成的少數類樣本周圍k個鄰居中選擇1個少數類樣本,根據下列等式進行合成
重復合成直到滿足需要步驟(5)合成的數目為止。
部分代碼如下:
- df=get_data()
- x, y = load_creditcard_data(df)
- X_resampled_smote, y_resampled_smote = ADASYN().fit_sample(x, y)
三、欠采樣
以下兩種方法都屬于欠抽樣,不同于直接欠抽樣,他們將信息的丟失程度盡量降低。兩者的核心思想為:
1. EasyEnsemble 核心思想是:
- 首先通過從多數類中獨立隨機抽取出若干子集
- 將每個子集與少數類數據聯合起來訓練生成多個基分類器
- 最終將這些基分類器組合形成一個集成學習系統
EasyEnsemble 算法被認為是非監督學習算法,因此它每次都獨立利用可放回隨機抽樣機制來提取多數類樣本
2. BalanceCascade 核心思想是:
- 使用之前已形成的集成分類器來為下一次訓練選擇多類樣本
- 然后再進行欠抽樣
四、一分類
對于正負樣本極不平衡的場景,我們可以換一個完全不同的角度來看待問題:把它看做一分類(One Class Learning)或異常檢測(Novelty Detection)問題。這類方法的重點不在于捕捉類間的差別,而是為其中一類進行建模,經典的工作包括One-class SVM等。
我們只對一類進行訓練,模型的結果會聚集在某個范圍內,測試集進行測試,則模型的輸出結果為1和-1兩種,當落在這個區間,結果為1,不在這個區間,則結果為-1
部分代碼如下:
- def MechanicalRupture_Model():
- train = pd.read_excel(normal)
- test = pd.read_excel(unnormal)
- clf = svm.OneClassSVM(nu=0.1, kernel=rbf, gamma=0.1)
- clf.fit(train)
- y_pred_train = clf.predict(train)
- y_pred_test = clf.predict(test)
五、改進的adaboost方法
AdaCost算法修改了Adaboost算法的權重更新策略,其基本思想是對于代價高的誤分類樣本大大地提高其權重,而對于代價高的正確分類樣 本適當地降低其權重,使其權重降低相對較小。總體思想是代價高樣本權重增加得大降低得慢。
具體adacost代碼如下:
- #!/usr/bin/env python3# -*- coding:utf-8 -*-import numpy as npfrom numpy.core.umath_tests import inner1dfrom sklearn.ensemble import AdaBoostClassifierclass AdaCostClassifier(AdaBoostClassifier):#繼承AdaBoostClassifier
- def _boost_real(self, iboost, X, y, sample_weight, random_state):
- implement a single boost using the SAMME.R real algorithm.
- :param iboost:
- :param X:
- :param random_state:
- :param y:
- :return:sample_weight,estimator_error
- estimator = self._make_estimator(random_state=random_state)
- estimator.fit(X, y, sample_weight=sample_weight)
- y_predict_proba = estimator.predict_proba(X) if iboost == 0:
- self.classes_ = getattr(estimator, 'classes_', None)
- self.n_classes_ = len(self.classes_)
- y_predict = self.classes_.take(np.argmax(y_predict_proba, axis=1),axis=0)
- incorrect = y_predict != y
- estimator_error = np.mean(np.average(incorrect, weights=sample_weight, axis=0)) if estimator_error = 0: return sample_weight, 1., 0.
- n_classes = self.n_classes_
- classes = self.classes_
- y_codes = np.array([-1. / (n_classes - 1), 1.])
- y_coding = y_codes.take(classes == y[:, np.newaxis])
- proba = y_predict_proba # alias for readability
- proba[proba np.finfo(proba.dtype).eps] = np.finfo(proba.dtype).eps
- estimator_weight = (-1. * self.learning_rate * (((n_classes - 1.) / n_classes) *
- inner1d(y_coding, np.log(y_predict_proba)))) # 樣本更新的公式,只需要改寫這里
- if not iboost == self.n_estimators - 1:
- sample_weight *= np.exp(estimator_weight *
- ((sample_weight 0) |
- (estimator_weight 0)) *
- self._beta(y, y_predict)) # 在原來的基礎上乘以self._beta(y, y_predict),即代價調整函數
- return sample_weight, 1., estimator_error def _beta(self, y, y_hat):
- adjust cost function weight
- :param y:
- :param y_hat:
- :return:res
- res = [] for i in zip(y, y_hat): if i[0] == i[1]:
- res.append(1) # 正確分類,系數保持不變,按原來的比例減少
- elif i[0] == 0 and i[1] == 1: # elif i[0] == 1 and i[1] == -1:
- res.append(1) # 將負樣本誤判為正樣本代價應該更大一些,比原來的增加比例要高
- elif i[0] == 1 and i[1] == 0: # elif i[0] == -1 and i[1] == 1:
- res.append(1.25) # 將正列判為負列,代價不變,按原來的比例增加
- else: print(i[0], i[1]) return np.array(res)
總結:
其中
smote采樣 、adasyn采樣、欠采樣、一分類是針對數據集做出處理。
改進的adaboost方法是對模型方法進行的改進。
具體采用哪種方式,需要結合具體情況。