機(jī)器學(xué)習(xí)排序LTR入門——線性模型
很多搜索達(dá)人都有這樣一種沖動,想要“通過機(jī)器學(xué)習(xí)獲得最優(yōu)權(quán)重”然后用于搜索查詢中。對于搜索這件事兒來說有點(diǎn)像打地鼠游戲,正如通常人們所說的“如果我能選擇優(yōu)化‘標(biāo)題匹配’的權(quán)重還是‘內(nèi)容匹配’的權(quán)重,那我肯定會做得更好”!
這種學(xué)習(xí)何種權(quán)重應(yīng)用于查詢的本能,就是最簡化機(jī)器學(xué)習(xí)排序(learning to rank,LTR)模型的根本原理:線性模型。沒錯,就是傳說中的線性回歸!線性回歸非常簡單易用,甚至感覺一點(diǎn)兒都不像是機(jī)器學(xué)習(xí);更像是高中生的統(tǒng)計(jì)學(xué)一樣,理解該模型及其原理也非常地容易。
本系列文章中,我想先介紹成功實(shí)施LTR背后的關(guān)鍵算法,從線性回歸開始,逐步到梯度 boosting(不同種類的boosting算法一起)、RankSVM和隨機(jī)森林等算法。
LTR首先是一個回歸問題
對于本系列的文章,正如你在前一篇及文檔中了解到的,我想把LTR映射為一個更加通用的問題:回歸。回歸問題需要訓(xùn)練一個模型,從而把一組數(shù)值特征映射到一個預(yù)測數(shù)值。
舉個例子:你需要什么樣的數(shù)據(jù)才能預(yù)測一家公司的利潤?可能會有,手邊的歷史公共財(cái)務(wù)數(shù)據(jù),包括雇員數(shù)量、股票價(jià)格、收益及現(xiàn)金流等。假設(shè)已知某些公司的數(shù)據(jù),你的模型經(jīng)過訓(xùn)練后用于預(yù)測這些變量(或其子集)的函數(shù)即利潤。對于一家新公司,你可以使用這個函數(shù)來預(yù)測該公司的利潤。
LTR同樣是一個回歸問題。你手頭上有一系列評價(jià)數(shù)據(jù),來衡量一個文檔與某個查詢的相關(guān)度等級。我們的相關(guān)度等級取值從A到F,更常見的情況是取值從0(完全不相關(guān))到4(非常相關(guān))。如果我們先考慮一個關(guān)鍵詞搜索的查詢,如下示例:
- grade,movie,keywordquery
- 4,Rocky,rocky
- 0,Turner and Hootch,rocky
- 3,Rocky II,rocky
- 1,Rambo,rocky
- ...
當(dāng)構(gòu)建一個模型來預(yù)測作為一個時間信號排序函數(shù)的等級時,LTR就成為一個回歸問題。 相關(guān)度搜索中的召回,即我們所說的信號,表示查詢和文檔間關(guān)系的任意度量;更通用的名稱叫做特征,但我個人更建議叫長期信號。原因之一是,信號是典型的獨(dú)立于查詢的——即該結(jié)果是通過度量某個關(guān)鍵詞(或查詢的某個部分)與文檔的相關(guān)程度;某些是度量它們的關(guān)系。因此我們可以引入其他信號,包括查詢特有的或者文檔特有的,比如一篇文章的發(fā)表日期,或者一些從查詢抽取出的實(shí)體(如“公司名稱”)。
來看看上面的電影示例。你可能懷疑有2個依賴查詢的信號能幫助預(yù)測相關(guān)度:
- 一個搜索關(guān)鍵詞在標(biāo)題屬性中出現(xiàn)過多少次
- 一個搜索關(guān)鍵詞在摘要屬性中出現(xiàn)過多少次
擴(kuò)展上面的評價(jià),可能會得到如下CSV文件所示的回歸訓(xùn)練集,把具體的信號值映射為等級:
- grade,numTitleMatches,numOverviewMatches
- 4,1,1
- 0,0,0
- 3,0,3
- 1,0,1
你可以像線性回歸一樣應(yīng)用回歸流程,從而通過其他列來預(yù)測第一列。也可以在已有的搜索引擎像Solr或Elasticsearch之上來構(gòu)建這樣一個系統(tǒng)。
我回避了一個復(fù)雜問題,那就是:如何獲得這些評價(jià)?如何知道一個文檔對一個查詢來說是好還是壞?理解用戶分析?專家人工分析?這通常是最難解決的——而且是跟特定領(lǐng)域非常相關(guān)的!提出假設(shè)數(shù)據(jù)來建立模型雖然挺好的,但純屬做無用功!
線性回歸LTR
如果你學(xué)過一些統(tǒng)計(jì)學(xué),可能已經(jīng)很熟悉線性回歸了。線性回歸把回歸問題定義為一個簡單的線性函數(shù)。比如,在LTR中我們把上文的第一信號(一個搜索關(guān)鍵詞在標(biāo)題屬性中出現(xiàn)過多少次)叫做t,第二信號(一個搜索關(guān)鍵詞在摘要屬性中出現(xiàn)過多少次)叫做o,我們的

模型能生成一個函數(shù)s,像下面這樣對相關(guān)度來打分:
我們能評估出最佳擬合系數(shù)c0,c1,c2等,并使用最小二乘擬合的方法來預(yù)測我們的訓(xùn)練數(shù)據(jù)。這里就不贅述了,重點(diǎn)是我們能找到c0,c1,c2等來最小化實(shí)際等級g與預(yù)測值s(t,o)之間的誤差。如果溫習(xí)下線性代數(shù),會發(fā)現(xiàn)這就像簡單的矩陣數(shù)學(xué)。
使用線性回歸你會更滿意,包括決策確實(shí)是又一個排序信號,我們定義為t*o。或者另一個信號t2,實(shí)踐中一般定義為t^2或者log(t),或者其他你認(rèn)為有利于相關(guān)度預(yù)測的最佳公式。接下來只需要把這些值作為額外的列,用于線性回歸學(xué)習(xí)系數(shù)。
任何模型的設(shè)計(jì)、測試和評估是一個更深的藝術(shù),如果希望了解更多,強(qiáng)烈推薦統(tǒng)計(jì)學(xué)習(xí)概論。
使用sklearn實(shí)現(xiàn)線性回歸LTR
為了更直觀地體驗(yàn),使用Python的sklearn類庫來實(shí)現(xiàn)回歸是一個便捷的方式。如果想使用上文數(shù)據(jù)通過線性回歸嘗試下簡單的LTR訓(xùn)練集,可以把我們嘗試的相關(guān)度等級預(yù)測值記為S,我們看到的信號將預(yù)測該得分并記為X。
我們將使用一些電影相關(guān)度數(shù)據(jù)嘗試點(diǎn)有趣的事情。這里有一個搜索關(guān)鍵詞“Rocky”的相關(guān)度等級數(shù)據(jù)集。召回我們上面的評判表,轉(zhuǎn)換為一個訓(xùn)練集。一起來體驗(yàn)下真實(shí)的訓(xùn)練集(注釋會幫助我們了解具體過程)。我們將檢查的三個排序信號,包括標(biāo)題的TF*IDF得分、簡介的TF*IDF得分以及電影觀眾的評分。
- grade,titleScore,overviewScore,ratingScore,comment:# keywords@movietitle
- 4,10.65,8.41,7.40,# 1366 rocky@Rocky
- 3,0.00,6.75,7.00,# 12412 rocky@Creed
- 3,8.22,9.72,6.60,# 1246 rocky@Rocky Balboa
- 3,8.22,8.41,0.00,# 1374 rocky@Rocky IV
- 3,8.22,7.68,6.90,# 1367 rocky@Rocky II
- 3,8.22,7.15,0.00,# 1375 rocky@Rocky V
- 3,8.22,5.28,0.00,# 1371 rocky@Rocky III
- 2,0.00,0.00,7.60,# 154019 rocky@Belarmino
- 2,0.00,0.00,7.10,# 1368 rocky@First Blood
- 2,0.00,0.00,6.70,# 13258 rocky@Son of Rambow
- 2,0.00,0.00,0.00,# 70808 rocky@Klitschko
- 2,0.00,0.00,0.00,# 64807 rocky@Grudge Match
- 2,0.00,0.00,0.00,# 47059 rocky@Boxing Gym
- ...
所以接下來直接來到代碼的部分!下面的代碼從一個CSV文件讀取數(shù)據(jù)到一個numpy數(shù)組;該數(shù)組是二維的,第一維作為行,第二維作為列。在下面的注釋中可以看到很新潮的數(shù)組切片是如何進(jìn)行的:
- from sklearn.linear_model import LinearRegression
- from math import sin
- import numpy as np
- import csv
- rockyData = np.genfromtxt('rocky.csv', delimiter=',')[1:] # Remove the CSV header
- rockyGrades = rockyData[:,0] # Slice out column 0, where the grades are
- rockySignals = rockyData[:,1:-1] # Features in columns 1...all but last column (the comment)
不錯!我們已準(zhǔn)備好進(jìn)行一個簡單線性回歸了。這里我們使用一個經(jīng)典的判斷方法:方程比未知數(shù)多!因此我們需要使用常最小二乘法來估算特征rockySignals和等級rockyGrades間的關(guān)系。很簡單,這就是numpy線性回歸所做的:
- butIRegress = LinearRegression()
- butIRegress.fit(rockySignals, rockyGrades)
這里給出了系數(shù)(即“權(quán)重”)用于我們的排序信號,:
- butIRegress.coef_ #boost for title, boost for overview, boost for rating
- array([ 0.04999419, 0.22958357, 0.00573909])
- butIRegress.intercept_
- 0.97040804634516986
漂亮!相關(guān)度解決了!(真的嗎?)我們可以使用這些來建立一個排序函數(shù)。我們已經(jīng)學(xué)習(xí)到了分別使用什么樣的權(quán)重到標(biāo)題和簡介屬性。
截至目前,我忽略了一部分事項(xiàng),即我們需要考量如何評價(jià)模型和數(shù)據(jù)的匹配度。在本文的結(jié)尾,我們只是想看看一般情況下這些模型是如何工作。但不只是假設(shè)該模型非常適合訓(xùn)練集數(shù)據(jù)是個不錯的想法,總是需要回退一些數(shù)據(jù)來測試的。接下來的博文會分別介紹這些話題。
使用模型對查詢打分
我們通過這些系數(shù)可以建立自己的排序函數(shù)。做這些只是為了描述目的,sk-learn的線性回歸帶有預(yù)測方法,能評估作為輸入的模型,但是構(gòu)建我們自己的更有意思:
- def relevanceScore(intercept, titleCoef, overviewCoef, ratingCoef, titleScore, overviewScore, movieRating):
- return intercept + (titleCoef * titleScore) + (overviewCoef * overviewScore) + (ratingCoef * movieRating)
使用該函數(shù)我們可以獲得檢索“Rambo”時,這兩部候選電影的相關(guān)度得分:
- titleScore,overviewScore,movieRating,comment
- 12.28,9.82,6.40,# 7555 rambo@Rambo
- 0.00,10.76,7.10,# 1368 rambo@First Blood
現(xiàn)在對Rambo和First Blood打分,看看下哪一個跟查詢“Rambo”更相關(guān)!
- # Score Rambo
- relevanceScore(butIRegress.intercept_, butIRegress.coef_[0], butIRegress.coef_[1], butIRegress.coef_[2], titleScore=12.28, overviewScore=9.82, movieRating=6.40)
- # Score First Blood
- relevanceScore(butIRegress.intercept_, butIRegress.coef_[0], butIRegress.coef_[1], butIRegress.coef_[2], titleScore=0.00, overviewScore=10.76, movieRating=7.10)
結(jié)果得分分別是Rambo 3.670以及First Blood 3.671。
非常接近!First Blood稍微高于Rambo一點(diǎn)兒獲勝。原因是這樣——Rambo是一個精確匹配,而First Blood是Rambo電影前傳!因此我們不應(yīng)該真的讓模型如此可信,并沒有那么多的例子達(dá)到那個水平。更有趣的是簡介得分的系數(shù)比標(biāo)題得分的系數(shù)大。所以至少在這個例子中我們的模型顯示,簡介中提到的關(guān)鍵字越多,最終的相關(guān)度往往越高。至此我們已經(jīng)學(xué)習(xí)到一個不錯的處理策略,用來解決用戶眼里的相關(guān)度!
把這個模型加進(jìn)來會更有意思,這很好理解,并且產(chǎn)生了很合理的結(jié)果;但是特征的直接線性組合通常會因?yàn)橄嚓P(guān)度應(yīng)用而達(dá)不到預(yù)期。由于缺乏這樣的理由,正如Flax的同行所言,直接加權(quán)boosting也達(dá)不到預(yù)期。
為什么?細(xì)節(jié)決定成敗!
從前述例子中可以發(fā)現(xiàn),一些非常相關(guān)的電影確實(shí)有很高的TF*IDF相關(guān)度得分,但是模型卻傾向于概要字段與相關(guān)度更加密切。實(shí)際上何時標(biāo)題匹配以及何時概要匹配還依賴于其他因素。
在很多問題中,相關(guān)度等級與標(biāo)題和摘要屬性的得分并不是一個簡單的線性關(guān)系,而是與上下文有關(guān)。如果就想直接搜索一個標(biāo)題,那么標(biāo)題肯定會更加匹配;但是對于并不太確定想要搜索標(biāo)題,還是類別,或者電影的演員,甚至其他屬性的情形,就不太好辦了。
換句話說,相關(guān)度問題看起來并非是一個純粹的最優(yōu)化問題:
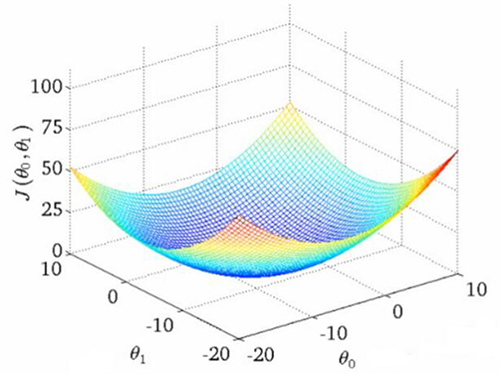
實(shí)踐中的相關(guān)度要更加復(fù)雜。并沒有一個神奇的最優(yōu)解,寧可說很多局部最優(yōu)依賴于很多其他因子的! 為什么呢?換句話說,相關(guān)度看起來如圖所示:
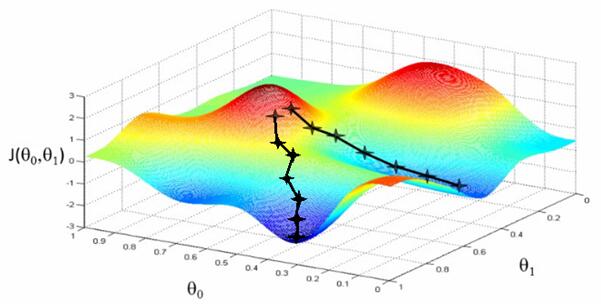
可以想象這些圖(吳恩達(dá)機(jī)器學(xué)習(xí)課程中的干貨)用于展示“相關(guān)度錯誤” —— 離我們正在學(xué)習(xí)的分?jǐn)?shù)還有多遠(yuǎn)。兩個θ變量的映射表示標(biāo)題和摘要的相關(guān)度得分。第一張圖中有一個單一的最優(yōu)值,該處的“相關(guān)度錯誤”最小 —— 一個理想的權(quán)重設(shè)置應(yīng)用這兩個查詢。第二個更加實(shí)際一些:波浪起伏、上下文相關(guān)的局部最小。有時與一個非常高的標(biāo)題權(quán)重值有關(guān),或者是一個非常低的標(biāo)題權(quán)重!