數據科學簡化:統計學習的關鍵概念
在本文中,我將深入探討數據科學中的統計學習概念。
首先,我將定義什么是統計學習。然后,我們將深入研究統計學習中的關鍵概念。
什么是統計學習?
根據維基百科,統計學習理論是從統計學和功能分析領域中提取的機器學習的框架。
機器學習是通過軟件應用程序實現的統計學習技術的表現。
這在實踐中意味著什么?統計學習是指能夠使我們更好地理解數據的工具和技術。理解數據是什么意思?
在統計學習的背景下,有兩種類型的數據:
- 可以直接控制的數據被稱為自變量。
- 無法直接控制的數據被稱為因變量。
- 無法控制的數據,即因變量需要預測或估計。
更好地理解數據是根據自變量來表示因變量。讓我用一個例子來說明它:
- 假設我想根據我為電視,廣播和打印分配的廣告預算來衡量銷售額。我可以控制可以分配給電視,廣播和打印的預算。我無法控制的是它們將如何影響銷售。我想用我無法控制的數據(銷售)作為我可以控制的數據(廣告預算)的函數。
統計學習揭示隱藏的數據關系。依賴數據和獨立數據之間的關系。
參數和模型
運營管理中著名的商業模式之一是ITO模型。它代表輸入 - 轉換 - 輸出模型。這些輸入經歷了一些轉換創建一個輸出。
統計學習也應用了類似的概念。有輸入數據,輸入數據被轉換,生成輸出(需要預測或估計的數據)。
轉換引擎稱為模型。這些是估算輸出的函數。
這個轉換是數學上的。將數學成分添加到輸入數據中以估計輸出。這些成分稱為參數。
讓我們來看一個例子:
- 是什么決定了一個人的收入?收入是由一個人的教育和多年的經驗決定的。估計收入的模型可以是這樣的:收入= c +β0*教育+β1*經驗
β0和β1是表示收入與教育和經驗相關的參數。
教育和經驗是可控的變量。這些可控變量具有不同的同義詞。它們被稱為自變量。它們也被稱為特征。
收入是無法控制的變量。它們被稱為目標。
訓練和測試
當我們準備考試時,我們該怎么辦?研究,學習,接受,做筆記,練習,模擬測試。這些是學習和準備未知測試的工具。
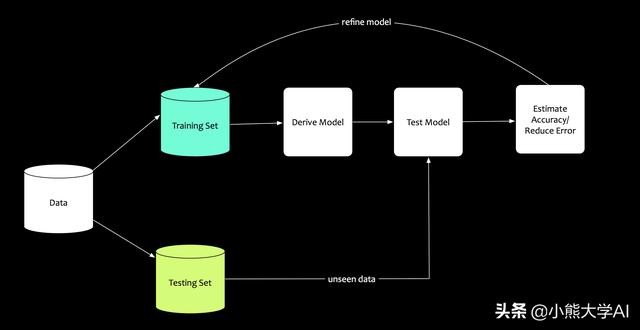
機器學習也使用類似的學習概念。數據是有限的,可用的數據需要謹慎使用。構建的模型需要進行驗證。驗證它的方法如下:
將數據拆分為兩部分。
- 一部分進行訓練。讓模型從中學習,讓模型使用數據。此數據集稱為訓練數據。
- 另一部分進行測試。使用未知的數據對模型進行“測試”。此數據集稱為測試數據。
在競爭性考試中,如果準備充分,學習合理,那么最后的考試成績也會令人滿意。類似地,在機器學習中,如果模型從訓練數據中很好地學習,則它將在測試數據上表現良好。
類似地,在機器學習中,一旦在測試數據集上測試了模型,就會評估模型的性能。它是根據估計的輸出與實際值的接近程度來評估的。
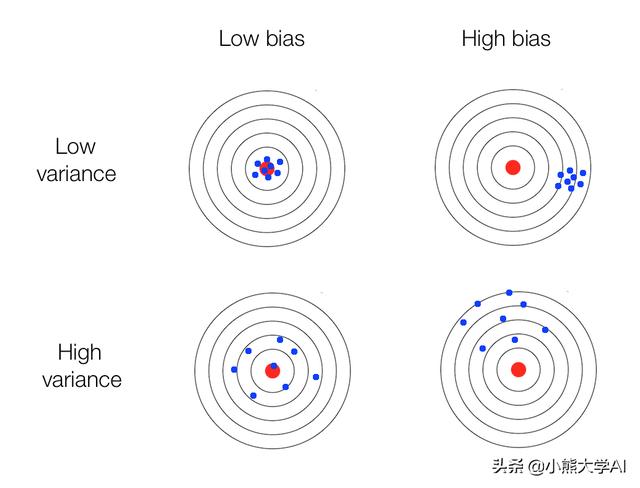
方差和偏差
英國著名統計學家喬治·博克斯曾引用過:
- “All models are wrong, but some are useful。“
沒有一個模型是100%準確的。所有模型都是有誤差的。這些誤差來自兩個來源:
- 偏差
- 方差
讓我試著用類比來解釋這個。
一個7歲的孩子,剛剛學習了乘法的概念。他已經掌握了1和2的法則。他的下一個挑戰是學習3的法則。他非常興奮并開始練習3的乘法表。他的表是這樣的:
- 3 x 1 = 4
- 3 x 2 = 7
- 3 x 3 = 10
- 3 x 4 = 13
- 3 x 5 = 16
他的同學和他一樣,但是他的表看起來是這樣的:
- 3 x 1 = 5
- 3 x 2 = 9
- 3 x 3 = 18
- 3 x 4 = 24
- 3 x 5 = 30
讓我們從機器學習的角度來研究兩個學生創建的乘法模型。(我們將兩個孩子認定為A,B)
- A的模型有一個無效的假設。它假設乘法運算意味著在結果之后添加一個1。該假設引入了偏置誤差。假設是一致的,即在輸出中加1。這意味著A的模型具有較低的偏差。
- A的模型導致輸出始終與實際相差1個數。這意味著他的模型具有低方差。
- B的模型輸出沒有邏輯。他的模型輸出與實際值有很大差異。偏差沒有一致的模式。B的模型具有高偏差和高方差。
上面的例子粗略地解釋了方差和偏差的重要概念。
- 偏壓:是模型不考慮數據中的所有信息,從而不斷學習錯誤的東西的傾向。
- 方差:是模型在不考慮真實信息的情況下獲取隨機信息的傾向。
偏差 - 方差的權衡
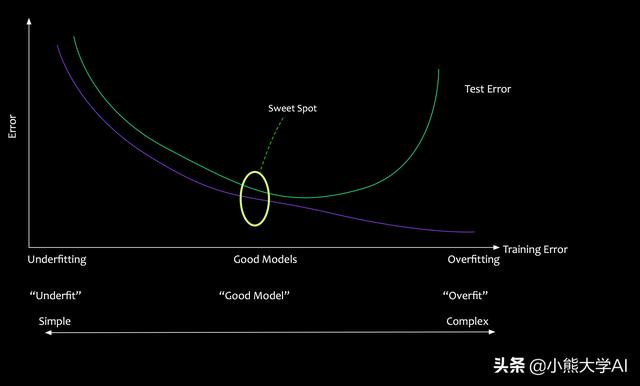
如果模型對特定的數據集了解太多,并試圖將相同的模型應用于未知的數據,則會出現較高的誤差。從給定數據集中學習太多被稱為過度擬合,它沒有將學習推廣到有用的未知數據上。另一方面,學習太少會導致欠擬合,該模型非常差,甚至無法從給定的數據中學習。
阿爾伯特愛因斯坦簡潔地總結了這個概念。他說:
“每件事都應該盡可能地簡單,但絕不是越簡單越好。”
在機器學習的問題中,一個不斷努力的目標就是找到一個正確的平衡點。創建一個不太復雜且不太簡單的模型,創建一個通用模型,創建一個相對不準確但有用的模型。
- 過度擬合的模型很復雜。它在訓練數據方面表現很好。它在測試數據方面表現不佳。
- 欠擬合的模型過于簡單。它對訓練數據和測試數據都無法正常的執行。
- 一個好的模型可以平衡欠擬合和過度擬合。它盡可能簡單但并不簡單。
這種平衡行為稱為偏差 - 方差的權衡。
結論
統計學習是復雜機器學習應用的基礎。本文介紹了統計學習的一些基本概念。本文的前5個要點是:
- 統計學習揭示隱藏的數據關系。依賴數據和獨立數據之間的關系。
- 模型是轉換引擎。參數是實現轉換的要素。
- 模型使用訓練數據來學習,使用測試數據進行評估。
- All models are wrong, but some are useful(所有模型都是錯誤的; 只有一些是有用的。)
- 偏差 - 方差權衡是一種平衡行為。平衡找到最佳平衡點,找到最優模型。
我們將在以后繼續深入研究機器學習模型的細節。