聊聊分布式系統一致性問題,你懂幾分?
0.寫在前面
前幾天在pyq發起了約稿,分布式一致性問題的選題呼聲最高,分布式系統的內容是非常龐雜的,所以我們從其中幾個重點的部分切入,慢慢展開。
今天重點來一起學習分布式系統一致性問題,不過內容比較多需要分幾次寫完。
1.為什么要學分布式
作為后端從業人員,我們在找工作寫簡歷的時候除了高并發經驗,一般還會寫上自己熟悉|了解|掌握|精通分布式系統,所以高并發和分布式大多是成對出現的。
在拉勾上搜了個后端崗位:
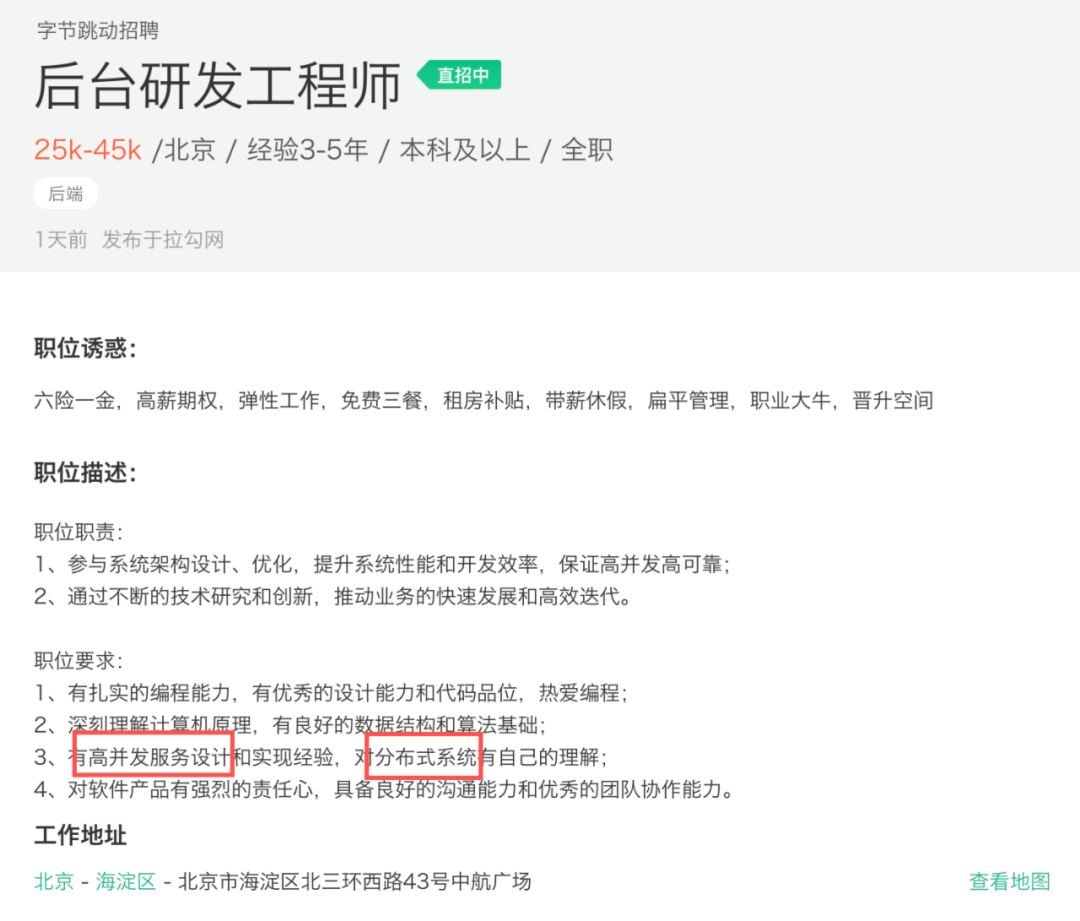
分布式系統是個多金的知識點,那還不抓緊行動!
2. 熵增的分布式系統
關于什么是分布式系統,有很多文章介紹,其實這個并不難理解,大白話講就是:工廠活多了一個人撐不住,那就多找些工人一起干,要讓這么多人為了一個目標干得快干得好,就需要一些規矩和套路,否則就亂了。
從實踐來看分布式系統屬于重要的架構模式,對于互聯網工程架構的演進,簡單提一下為什么會出現分布式系統以及什么是分布式系統:
業務量的迅速增大,普通的單機系統無法滿足要求,要么垂直擴展升級機器硬件,要么水平擴展堆廉價服務器,這也是主流可以想到的解決方法,目前來看互聯網領域選擇了后者-水平擴展。
水平擴展機器多機房部署升級服務集群規模來應對業務的增長,也就出現了分布式系統,這些分布式系統中的物理節點可能是多機房多網絡場景部署的,相互之間通過網絡進行通信和協作。
分布式系統就是為了解決巨大業務量和數據量而生的,但是龐大數量的節點來一起正確有序的完成共同的目標是需要理論和實踐來錘打的,這也是分布式系統的重點內容。
一般我們常接觸的分布式系統包括兩大類:分布式存儲和分布式計算。
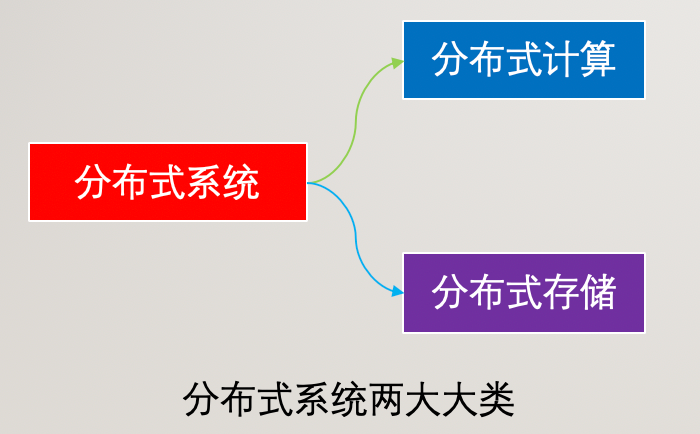
分布式系統那么多機器要一起協調去完成任務也不是一件容易的事情,所以我們通常認為分布式系統是個熵增過程。
熵是描述一個系統內在混亂程度的物理量,對于一個宏觀熵看孤立的系統來說,在沒有外力干預做功的前提下,系統內在混亂程度是會不斷增加的,也就是熵是增加的。
為了讓系統保持有序就必須對其進行外力干涉,對于分布式系統而言,我們必須使用相應的策略和算法使整個系統保持有序和正確,所以認為分布式系統是個熵增過程。
這個并不難理解,就像我們為了保持房屋整潔,定期必須打掃,要不然就亂成一鍋粥了。
如果對于系統不加以控制和干預,系統將自主走向混亂和無序。
3.分布式一致性問題的理解
分布式一致性到底是什么一致?
分布式的一致性可以表現在很多方面,這些都是個性問題,然而無論這些個性問題有多少,任何行為和狀態的展示必然是以數據為基礎的,所以這些個性的一致性問題最終都會映射到一個共性問題--分布式數據的一致性。
分布式系統中擁有很多獨立的節點,這些節點一般來說可以獨立進行存儲和計算任務,這兩項是最主要的任務類型,本質上計算和存儲的過程仍然是圍繞數據展開的,所以最終還是數據一致性。
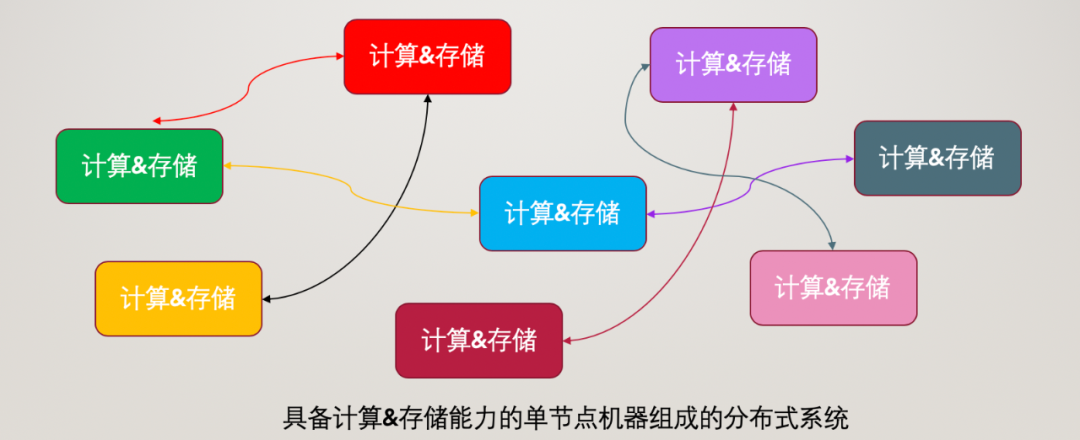
在中心化結構中,存在管理節點和任務節點的區別,也就是每個節點的權利和義務是不一樣的,管理節點可能負責分配任務給下屬節點和收集計算結果等,總體承擔協調者的角色,任務節點主要是承接任務,這樣容易出現管理節點的單點問題。
在去中心化的結構中,各個節點的權利和義務是相同的,盡管沒有單獨指定領導者,在實際的運行中仍然會選舉出領導者和failover動態更新領導者的問題,完全的去中心化系統并不多,相比中心化系統來說,去中心系統更加扁平也更加穩定,像Redis官方集群就是去中心化的實現,任何一個節點的故障都不會帶來特別大的問題,因為節點是平等的。
無論在中心化還是去中心化的分布式系統中,任何一個節點的計算和存儲結果都會對其他節點產生影響,這些獨立的節點通過基礎和特定的網絡協議進行協作,從而形成一個整體。
4. 嚴格意義的數據一致性
經過前面的一些鋪墊,我們開始重點部分的學習-分布式系統數據一致性問題。
我們必須要有個共識:嚴格意義上的分布式數據一致性是不存在的。
為啥不存在呢?
在分布式系統中數據存儲是多節點主從備份的,一般做成讀寫分離,當客戶端將數據通過主庫的代理寫入之后,在極其短暫的瞬間,主節點的數據是無法復制到從節點的,這個瞬間其他客戶端讀取到的從庫數據都是舊數據。
聰明的讀者盆友們可以體會一下瞬間這個詞,當然你可以認為這是相對論的范疇,從物理角度去看可能更能體會。
我們以redis主從節點之間的數據復制來看同步復制和異步復制場景下的數據一致性問題:
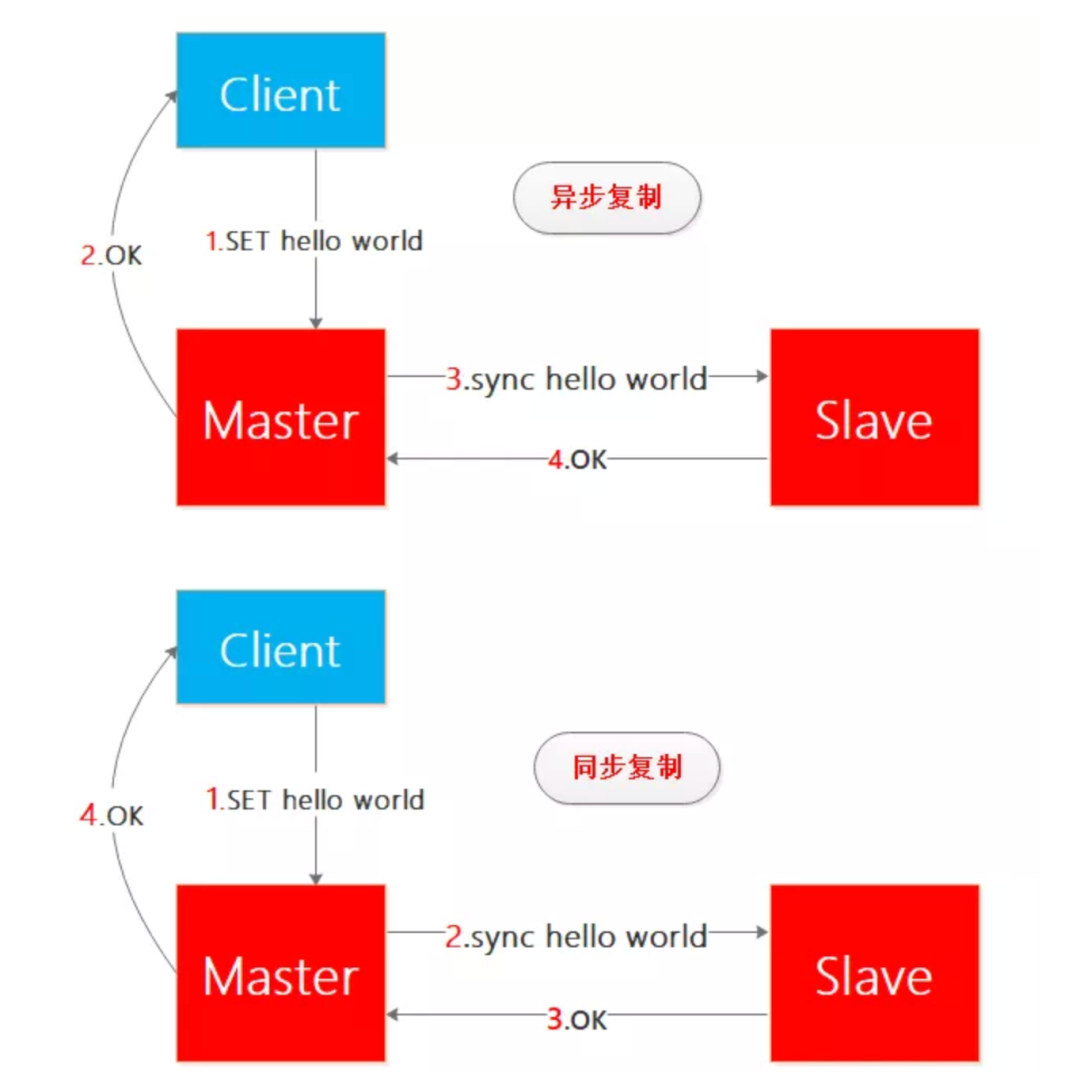
一般來說,為了保證服務的高可用,主從節點的數據復制是異步的,因為同步復制延時無法保證,當然有的場景也是同步復制的,這樣整體延時是無法保證的,假如是一主多從就更無法保證了同步復制的延時了。
所以我們不討論嚴苛意義上的數據一致性,而是研究在我們認為可以接受的時間長度下的數據一致性問題,也就是在自身環境約束下的數據一致性。
單機系統的一致性和事務都是比較容易達到的,在分布式系統中由于所有節點的交互都要通過網絡來實現,網絡必然存在不穩定并且龐大系統中的單節點穩定性也是需要考慮的。
前面這段話,讀起來云里霧里,我想表達的意思是:不要過分把對單機系統中的數據一致性要求照搬到分布式系統中,因為兩者的約束不一樣,我們要合理分析從而讓分布式系統的一致性盡量接近單機系統。
solo和團戰畢竟是不一樣的,典型的《倚天屠龍記》中張無忌要去少林寺救謝遜,但是遇上的少林三位神僧渡厄、渡難、渡劫已經坐禪幾十年,三人合一登峰造極,實在太難了,這也是優秀分布式系統的頂峰吧...
5.CAP理論和PACELC理論
我們知道cap理論描述了一致性、可用性、分區容忍性的關系。
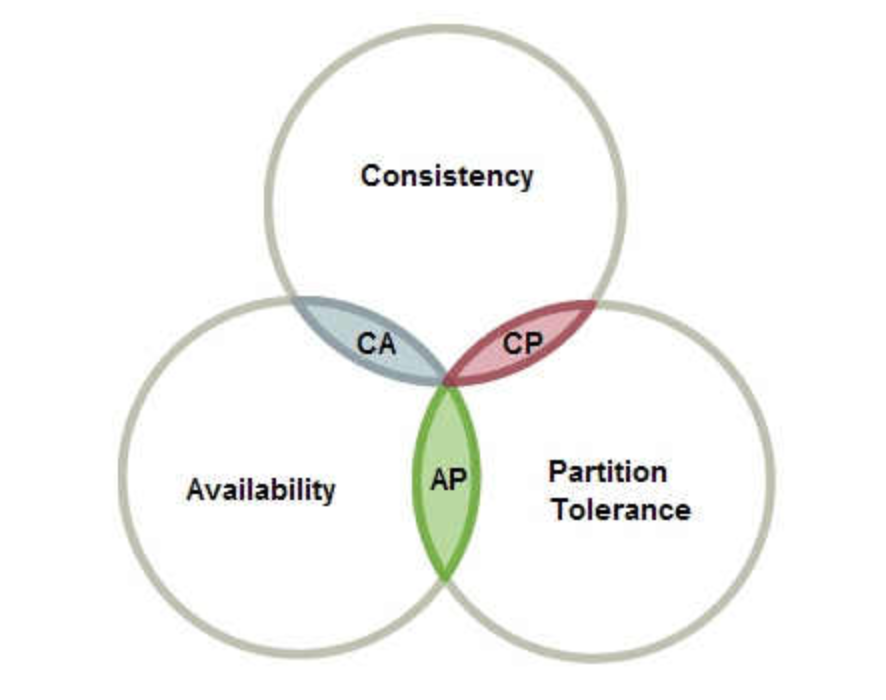
在分布式系統中,由于節點物理分布和網絡穩定性等原因,分區容忍性P是必然存在的,因此分布式系統必然要建立在分布式網絡存在分區P的前提下。
在P的基礎上我們對于C和A進行選擇,當然并不是說在任何時刻我們都必須C和A二選一,在網絡正常的情況下C和A我們也是可以都有的,并且每個系統設計目標也不一樣,需要更加實際要求來進行選擇。
分布式系統中P是必然存在的,我們在設計系統之初就要對C和A做平衡和選擇,在正常的情況下跑出正確的結果是基本要求,在異常情況下仍然可以正常運行是設計重點。
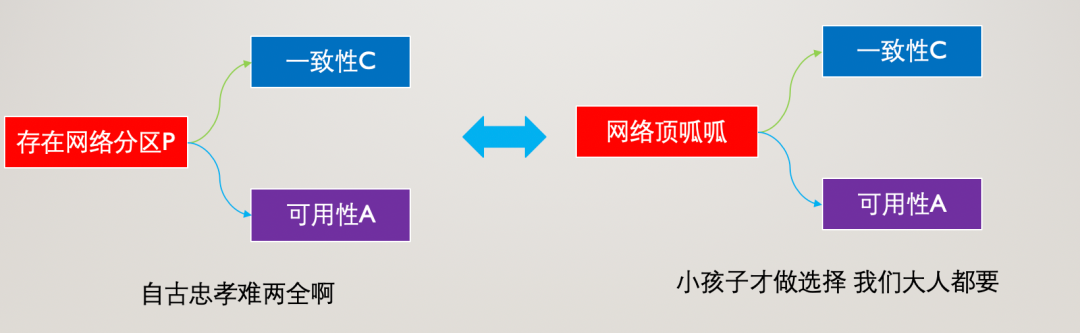
在分布式系統中,我們使用PACELC理論比CAP理論更加合適,因為PACELC理論是CAP理論的擴展,簡單來說PACELC理論的表述是這樣的:
如果分區partition (P)存在,分布式系統就必須在availability (A) 和consistency (C)之間取得平衡作出選擇,否則else (E) 當系統運行在無分區P情況下,系統需要在 latency (L) 和 consistency (C)之間取得平衡。
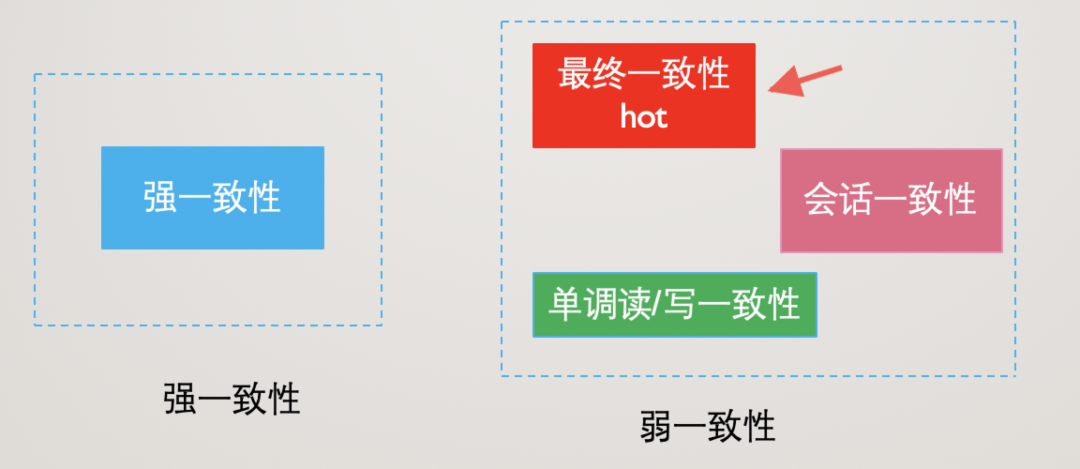
PACELC理論比CAP理論更適合分布式系統,它完全展現了出現網絡分區和正常情況下的取舍平衡問題,特別地引入了L時延因素,來對一致性C進行說明,也就是我們常說的強一致性和弱一致性。
強一致性不必多說,對主從數據的一致性要求很高,一般會犧牲可用性來保證,弱一致性又可以分為最終一致性/會話一致性/單調讀一致性/單調寫一致性等情況,從實用的角度來說我們重點關注弱一致性的最終一致性情況即可。
6.分布式和BASE理論
我們知道由于網絡穩定性原因,分布式系統出現網絡分區是必須要考慮的問題,在一般的互聯網場景中我們選擇最終一致性來保證服務的高可用,也就是允許一段時間L的數據不一致,經過數據復制和同步后最終達到一致。
我們看下BASE理論,這是我們理解分布式系統一致性的重要理論基礎:
BASE是基本可用(Basically Available)、軟狀態(Soft state)和最終一致性(Eventually consistent)三個短語的縮寫。
BA基本可用是指:系統在絕大部分時間應處于可用狀態,允許出現故障損失部分可用性,但保證核心可用。
S軟狀態是指:數據狀態不要求在任何時刻都保持一致,允許存在中間狀態,而該狀態不影響系統可用性。
E最終一致性是指:軟狀態前提下,經過一定時間后,這些數據最終能達到一致性狀態。
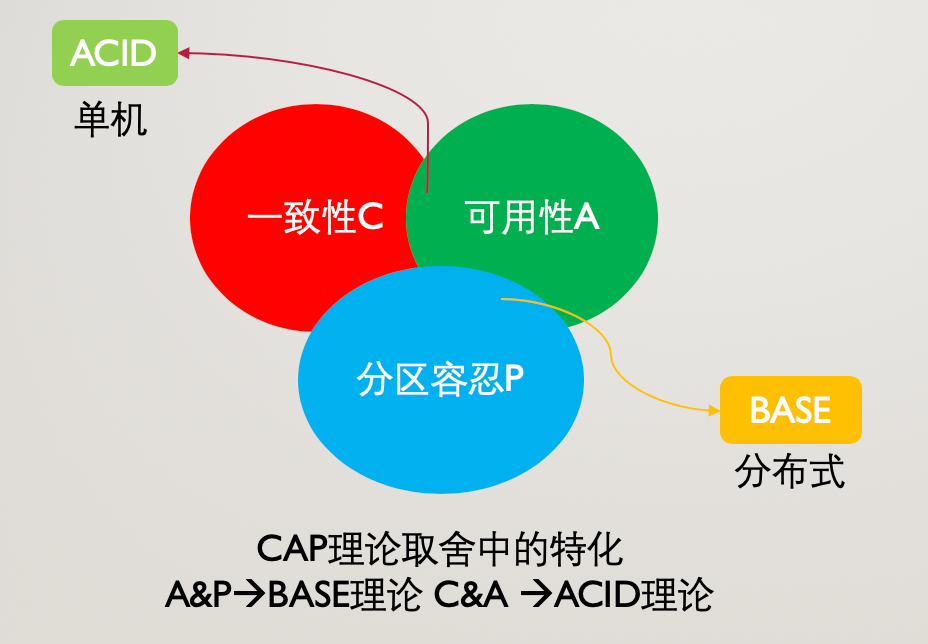
7.CAP&BASE&ACID的關系
CAP理論說明了分布式系統中一致性C 、可用性A、分區容錯性P之間的制約關系。
BASE理論和ACID理論可以看做是對CAP理論中三要素進行取舍后的某種情況,也是在單機系統和分布式系統中適用的情況,三者的關系如圖: