進化決策樹:當機器學習從生物學中汲取靈感時
隨著時間的推移,我們對生物學(或生命科學)的了解大大增加,它已成為許多工程師解決挑戰性問題并產生發明創造的的重要靈感來源。
以日本的高速列車“新干線”為例,它是世界上最快的火車之一,時速超過300公里/小時。 在設計過程中,工程師遇到了巨大的難題:火車前部空氣的位移所產生的噪音,其幅度大到可能破壞某些隧道的結構。
他們以一個出乎意料的方式找到了這個問題的解法:翠鳥。這種鳥的喙部細長,使之在潛入水中捕食時能夠少濺水花。
因此,通過模仿這種鳥的形象重新設計列車,工程師不僅解決了最初的問題,而且還將列車的耗電量減少了15%,速度提高了10%。
圖1-日本的高速鐵路,新干線,來源
生物學知識也可以成為機器學習中靈感的來源。
內容
本文重點關注的一個例子是進化決策樹。
這類分類器使用進化算法來構建魯棒性更強,性能更好的決策樹。進化算法依賴于生物進化啟發的機制。
-
決策樹是什么?
-
如何根據進化算法搭建決策樹?
-
與其它分類器相比,進化決策樹的表現如何?
數據集
為了說明本文中提及的概念,我將使用航空公司乘客滿意度的調查結果數據集。有關此數據集的更多信息,請參見此處。
其目的是預測顧客對航空公司的服務的滿意度。這樣的研究對公司的決策至關重要。它不僅可以使提供商品或服務的公司知曉其產品在哪些方面需要改進,而且可以使公司知道應該改進到什么程度以及改進的緊要程度
事不宜遲,讓我們從復習關于決策樹的基礎知識開始吧。
1. 什么是決策樹?
決策樹是一種分類器,其分類流程可表示為樹形圖。模型在訓練過程中根據數據的特征推斷出簡單的決策規則,并依此對數據點進行分類。
下圖展示了一個決策樹的例子。這是使用Scikit Learn決策樹模塊在航空公司乘客滿意度的調查結果數據集上進行訓練的結果。
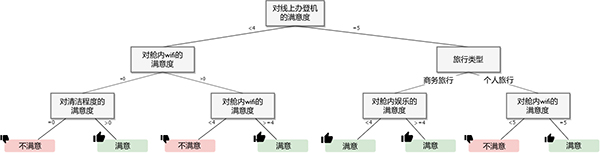
圖2-決策樹示例
決策樹表明網上值機服務是商務旅行中乘客滿意度的重要因素,乘客在能簡單高效地在網上辦理登機手續時更可能感到滿意。另外,艙內wifi的信號質量也十分重要。
決策樹由于具有許多優點而被廣泛用于分類任務:
-
它的推理過程與人類相似,易于理解和解釋;
-
它能處理數值數據和分類數據;
-
它通過分層分解能更充分地利用變量。
大多數用于推導決策樹的算法都使用自上而下的遞歸劃分“貪心”策略。
源集(source set)代表了樹的根節點。源集是根據特定規則劃分為各個子集(子節點)的。在每次劃分出的子集上重復該劃分過程,直到某個節點下的子集中的目標變量的值全部相同,或者劃分過程不再使預測結果的值增加。
用于在節點和劃分中確定生成測試的最佳方法的量化指標是因算法而異的。最常見的指標是信息量(或熵)和基尼雜質量。它們度量的是雜質度,當節點的所有樣本屬于同一類別時,這類指標的值為0;當節點的樣本的類別呈均一分布(即,該節點取到某一類別的概率為常數)時,這類指標的值取到最大值。更多相關信息參見本文。
但是,此類指標有兩個主要缺點:
1.可能取到次優解;
2.可能生成過于復雜的決策樹,以至于在訓練數據中泛化效果不好,導致過擬合。
目前已有幾種方法可用于克服這些問題:
-
剪枝:首先,構建一顆完整的決策樹,即每片葉子中的所有實例都屬于同一類。然后刪除“不重要”的節點或子樹,以減小樹的大小。
-
組合樹:構建不同的樹,并通過特定規則(一般是投票計數)選擇最終的分類結果。值得注意的是,這會導致決策樹的可解釋性降低。
因此,有必要探索生成樹模型的其它方法。最近,進化算法(Evolutionary Algorithms, EA)獲得了極大的關注。進化算法在所有可能的解法中進行強大的全局搜索,而不僅僅是本地搜索。結果,與貪心策略相比,進化算法更可能把屬性交互處理得更好。
進化算法的具體工作方式見下。
2. 怎樣用進化算法構造決策樹?
進化算法是搜索啟發式方法,其機理源自自然中的生物進化過程。
在這個范式中,群體中的每個“個體”代表給定問題的一種候選解法。每個個體的適合度代表這種解法的質量。這樣,隨機初始化的第一個群體會朝著搜索空間中更好的區域進化。在每一代中,選擇過程使得適合度較高(原文為“適合度較低”,疑有誤)的個體具有較高的繁殖概率。
此外,還會對群體進行特定的由遺傳學啟發的操作,例如重組,兩個個體的信息在混合后才會傳給他們的后代;以及突變,對個體進行微小的隨機改變。對這一過程進行迭代,直到達到某一終止條件。然后選擇最適個體為答案。

基于進化算法的決策樹是通用方法的一種有意思的替代品,因為:
-
隨機搜索法能有效避免自上而下的遞歸劃分“貪心”策略可能找到的局部最優解。
-
對決策樹的解釋與整體法相反。
-
不僅僅是優化單一指標,它可以將不同的目標集成在適合度中。

2.1 群體的初始化
在進化決策樹中,一個個體代表的是一棵決策樹。初始群體由隨機生成的樹組成。
隨機樹可以按以下步驟生成:
在根節點和兩個子節點后,算法以預設概率p決定每個子節點是否繼續劃分或成為終點。
-
如果繼續劃分該子節點,算法會隨機選擇一些性質和閾值作為劃分的標準。
-
如果該子節點成為終點(葉節點),就給它隨機分配一個類別標簽。
2.2 適合度
分類器的目標是在輸入未標記的新數據時能獲得最高預測準確度。此外,決策樹分類器還需要控制樹的最終尺寸。因為樹的尺寸小會導致欠擬合,而樹的結構太復雜會導致過擬合。
因此,在定義適合度時需要在這兩項之間取得平衡:
適合度 = α1 f1 + α2 f2
其中:
-
f1是在訓練集上的準確度;
-
f2是對個體的尺寸(樹的深度)所設置的懲罰項;
-
α1 和 α2 是待指定的參數。
2.3. 選擇過程
有多種方法可以選擇用于創建下一代樹的親本。最常見的是以下幾種:
-
基于適應度按比例選擇,或輪盤賭式選擇:按適合度對群體排序,然后依次為每個個體賦予選擇概率。
-
淘汰制選擇:先從群體中隨機選出一些個體,再從選出的集合中取適合度最高的個體作為親本。
-
精英制選擇:直接把適合度最高的個體用到下一代。這種方法能保留每代最成功的個體。
2.4 重組
獲得重組子代的過程需要使親本兩兩配對。
首先,選擇兩個個體作為親本。然后在兩棵樹中各隨機選一個節點。用第二棵樹中選擇的子樹代替第一棵樹中選中的子樹,獲得子代。
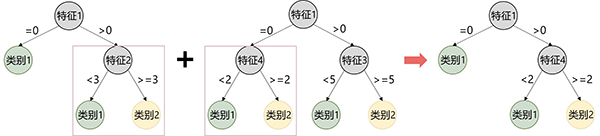
圖3-重組
2.5 突變
突變指的是一個群體的部分個體中的隨機的小選擇。突變是遺傳多樣性的保證,這意味著遺傳算法能搜索到更大的范圍。
對決策樹而言,突變可以通過隨機更改屬性或者細分隨機選的節點來實現。
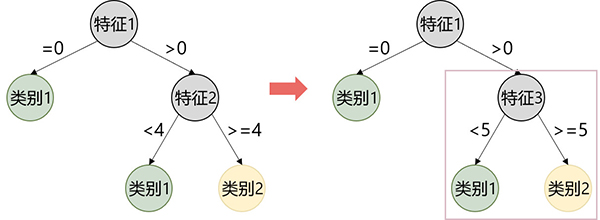
圖4-突變
2.6 終止條件
如果最優秀的個體的適合度在給定數量的世代中沒有上升,就可以認為算法已經收斂了。
為了在收斂得很慢時節約計算時間,這個世代數目是預先設定的參數。
3. 跟其它分類器比,進化決策樹的表現如何?
進化決策樹看起來很好,但跟常規機器學習算法相比,它的表現又如何?
3.1 一個簡單的實驗
為了評價分類器的效率,我搭建了一個決策樹,并在航空公司乘客滿意度調查結果數據集上進行訓練。
目標是找出能導致乘客滿意度升高的因素。 這樣就需要一個簡單而抗干擾的模型來解釋導致乘客感到滿意(或不滿意)的途徑。
關于數據集
這個數據集很大,囊括了多于10萬條航線。
-
含有關于乘客及其行程的事實信息:乘客的性別,年齡,客戶類型(是否有慣性),旅行類型(個人或商務旅行),航班艙位(商務,環保,極環保 )和飛行距離。
-
還包含乘客對以下服務的滿意度:艙內wifi,出發/到達時間(是否合宜),網上預訂(是否方便),登機口位置,餐飲,網上值機,座椅舒適度,艙內娛樂,登機服務,座椅腿部空間 ,行李服務,值機服務,艙內服務,整潔度。
數據標簽是乘客的滿意度,包括“滿意”,“中立”和“不滿意”。
方法
我使用的計算步驟可簡要歸納如下:
1. 數據預處理:將類別變量轉換為指示變量。將數據集隨機劃分為訓練集和測試集。
2. 建模和測試:訓練每個模型在訓練子集上考慮條件,在驗證子集上進行衡量。
3. 比較各模型的表現。
我選擇將進化決策樹(EDT)方法與基于簡單的樹的,基于決策樹(DT)的和基于隨機森林(RF)的模型進行比較。限制樹的深度小于(等于?)3。 我還將EDT的群體大小和RF的評價器數量設置為10,以便于在合理的計算時間內以一致的方式比較它們。
結果
結果如下:
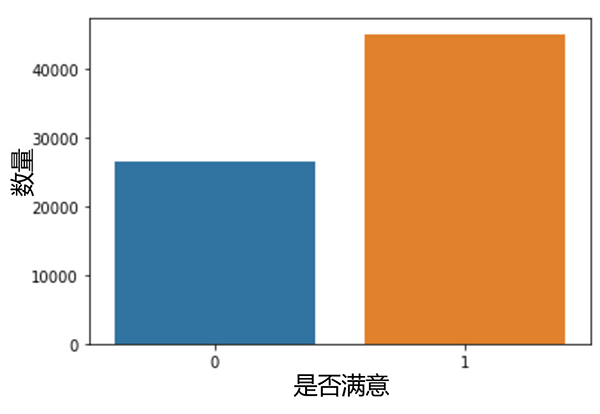
圖5-“滿意”以及“中立或不滿意”的乘客的數量
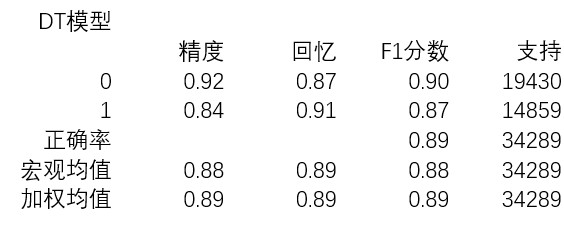
表1-DT模型的分類報告
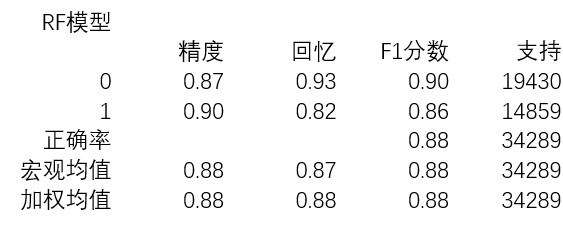
表2-RF模型的分類報告
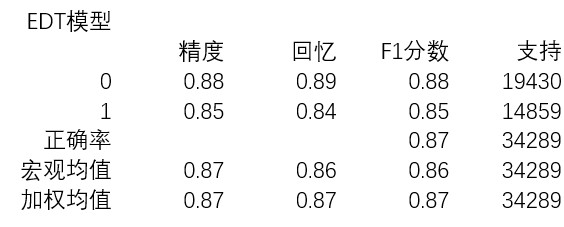
表3-EDT模型的分類報告
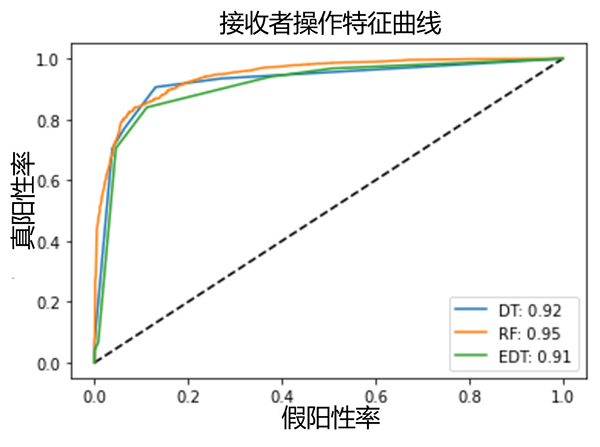
圖6-3個模型的ROC曲線和曲線下面積
在這種參數設置下,EDT的表現和另外兩種機器學習算法很接近。
然而,EDT的優勢在于它能提供這樣一棵決策樹:
-
可以呈現多顆決策樹聚集的位點(與RF模型相比),并且
-
具有魯棒性(與簡單DT模型相比),因為它是一群樹中表現最好的那顆。
在訓練過程中,將最大深度設為2,獲得的EDT群體中表現最好的決策樹可以表征為如下形式:

圖7()-EDT中最佳決策樹的示意圖
3.2 對EDF方法的一個更泛化的實驗驗證
上述實驗肯定不足以評估進化決策樹跟其它機器學習算法相比時的性能和可靠性。
因為只用了一個數據集,因此沒有考慮到所有可能性,例如標簽的類別數量,特征數量和觀測數量的影響等。
在[2]中,作者使用真實的UCI數據集對EDT方法與其他機器學習方法的性能進行了比較。
這篇文章的發現如下。
關于數據集
下表簡要介紹了所用的數據集:
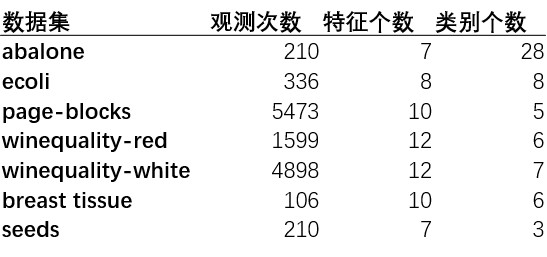
表4-數據集的性質
如你所見,數據集在觀測次數,特征個數和類別個數這幾個方面的差別很大。
最困難的數據集肯定是第一個數據集,因為它有很多類別,而觀察次數較少。
方法
以下是與更‘經典’的機器學習算法相比時,作者用來評估EDT模型表現的方法的主要信息:
-
EDT模型已使用以下超參數進行了訓練:世代數為500,群體大小為400,重組/變異的概率分別為0.6 / 0.4,選擇方法為隨機統一的精英制選擇。
-
使用5x2交叉驗證來測量模型的表現。
結果
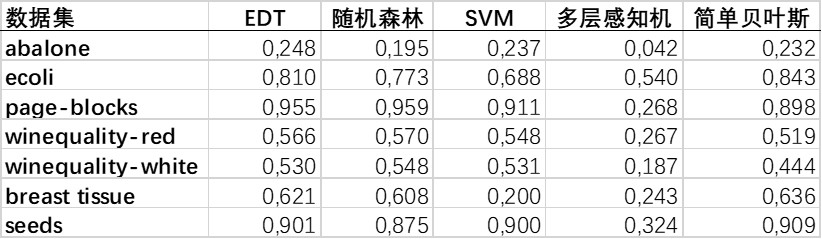
表5-模型的正確率取決于所用的數據集
-
基于樹的算法幾乎總是優于其它機器學習算法。 可以解釋為決策樹本身更能選擇出最重要的特征。 此外,基于規則的模型更適合用于特定的數據集,尤其是難以對目標與特征間的關系建模時。
-
鮑魚數據集上的結果都很差:因為有28個類別,而且觀測次數很少(只有210次)。 但是,EDT模型以最高的準確率脫穎而出。 這表明它能有效地處理困難的數據集并避免過擬合。
值得注意的是,EDT模型使用的是默認參數。 調整參數能帶來更好的表現。
引用
[1] R. Barros et al., A Survey of Evolutionary Algorithms for Decision Tree Induction, 2011
[2] D. Jankowski et al., Evolutionary Algorithm for Decision Tree Induction, 2016
[3] S. Cha, Constructing Binary Decision Trees using Genetic Algorithms, 2008
[4] D. Carvalho et al., A Hybrid Decision Tree/Genetic Algorithm Method for Data Mining, 2003
[5] Wikipedia, Traveling salesman problem
[6] Wikipedia, Genetic Algorithm