2021年,送給碼農的免費Python機器學習課程
2021年來了,越過了充滿艱辛的2020,希望大家在新的一年里,手里能多一件對抗未知的武器,剛哥送給大家免費的Python機器學習課程。
線性回歸
最基本的機器學習算法必須是具有單個變量的線性回歸算法。如今,可用的高級機器學習算法,庫和技術如此之多,以至于線性回歸似乎并不重要。但是,學習基礎知識總是一個好主意。這樣,您將非常清楚地理解這些概念。在本文中,我將逐步解釋線性回歸算法。
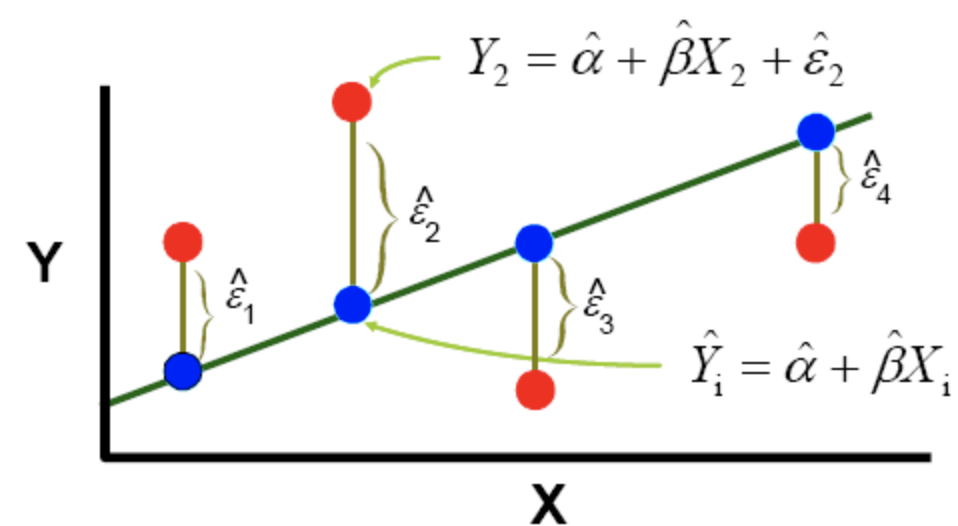
多元線性回歸
在回歸分析中,如果有兩個或兩個以上的自變量,就稱為多元回歸。事實上,一種現象常常是與多個因素相聯系的,由多個自變量的最優組合共同來預測或估計因變量,比只用一個自變量進行預測或估計更有效,更符合實際。因此多元線性回歸比一元線性回歸的實用意義更大
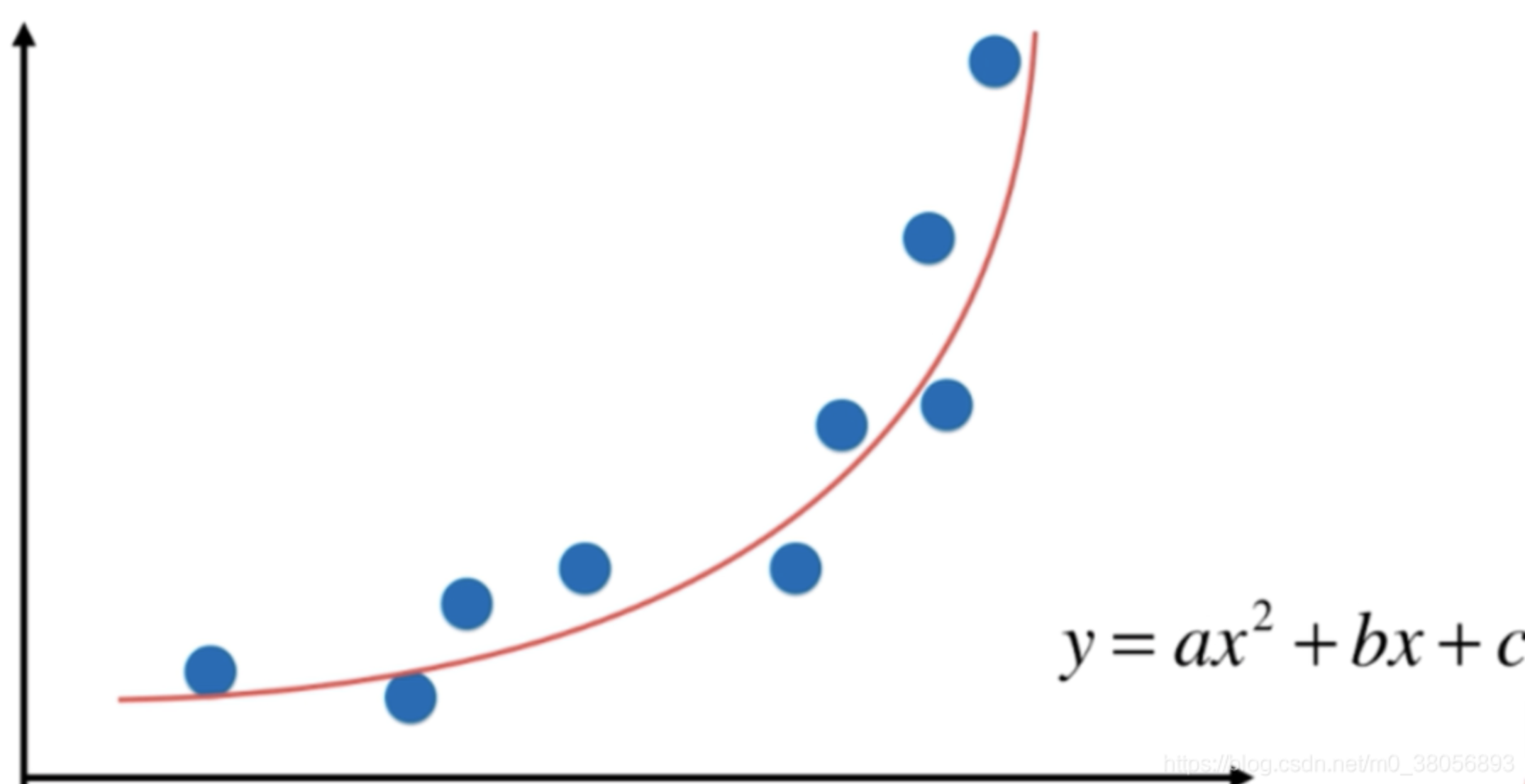
多項式回歸
在統計學中, 多項式回歸是回歸分析的一種形式,其中自變量 x 和因變量 y 之間的關系被建模為關于 x 的 n 次多項式。多項式回歸擬合x的值與 y 的相應條件均值之間的非線性關系,表示為 E(y|x),并且已被用于描述非線性現象,例如組織的生長速率[1]、湖中碳同位素的分布[2]以及沉積物和流行病的發展[3]。雖然多項式回歸是擬合數據的非線性模型,但作為統計估計問題,它是線性的。在某種意義上,回歸函數 E(y|x) 在從數據估計到的未知參數中是線性的。因此,多項式回歸被認為是多元線性回歸的特例。
邏輯回歸
自上世紀以來,邏輯回歸是一種流行的方法。它建立了分類變量和一個或多個自變量之間的關系。在機器學習中使用此關系來預測分類變量的結果。它被廣泛用于許多不同的領域,例如醫療領域,貿易和商業,技術等等。
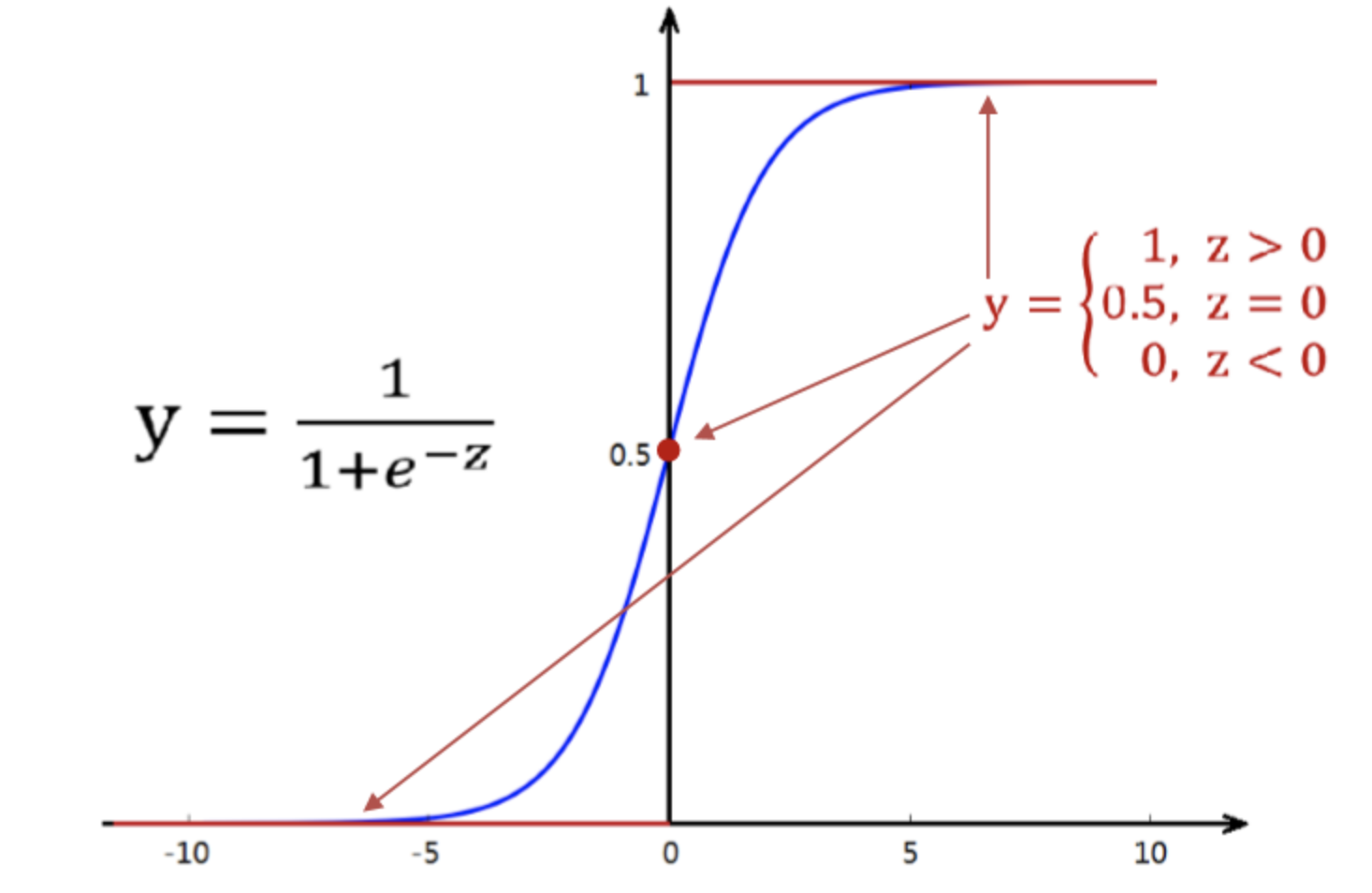
多類分類邏輯回歸
普通的邏輯回歸只能針對二分類問題,要想實現多個類別的分類,我們必須要改進邏輯回歸,讓其適應多分類問題。
關于這種改進,有兩種方式可以做到。
第一種方式是直接根據每個類別,都建立一個二分類器,帶有這個類別的樣本標記為1,帶有其他類別的樣本標記為0。假如我們有k個類別,最后我們就得到了k個針對不同標記的普通的邏輯二分類器。
第二種方式是修改邏輯回歸的損失函數,讓其適應多分類問題。這個損失函數不再籠統地只考慮二分類非1就0的損失,而是具體考慮每個樣本標記的損失。這種方法叫做softmax回歸,即邏輯回歸的多分類版本。
神經網絡算法
神經網絡已被開發來模仿人類的大腦。神經網絡在機器學習中非常有效。它在1980年代和1990年代很流行。最近,它變得越來越流行。可能是因為計算機足夠快,可以在合理的時間內運行大型神經網絡。
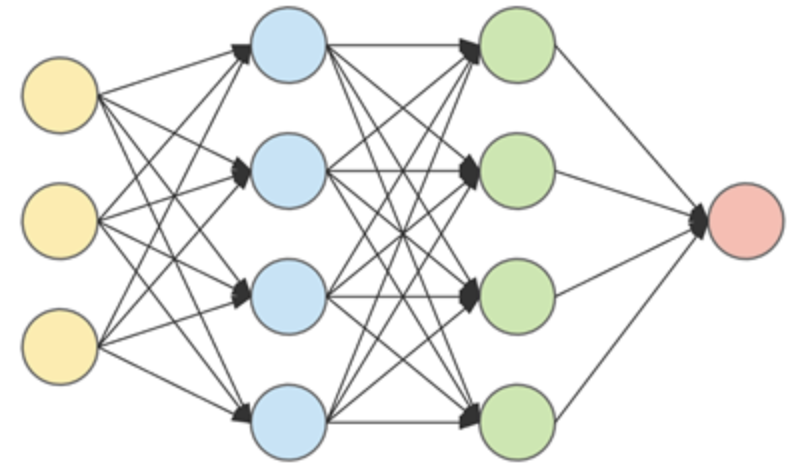
如何應對算法效果不佳
我們花了很多時間來開發機器學習算法。但是在部署后,如果該算法性能不佳,那將令人沮喪。問題是,如果算法無法按預期工作,下一步應該怎么做。什么地方出了錯?訓練數據的數量是否足夠?我們使用了正確的功能嗎?我們是否應該繼續收集更多數據?我們可以,但是那是非常耗時且昂貴的。我們應該添加更多功能嗎?那也可能很昂貴。

往哪個方向走?
如果您的機器學習算法無法正常工作,下一步該怎么做?有幾種選擇:
- 獲取更多的訓練數據非常耗時。甚至可能需要數月的時間才能獲得更多的研究數據。
- 獲得更多的訓練特征。也可能需要很多時間。但是,如果添加一些多項式特征可以工作,那就太酷了。
- 選擇較小的一組訓練特征。
- 增加正則項
- 減少正則項。
那么,接下來您應該嘗試哪一個呢?開始嘗試任何操作都不是一個好主意。因為您可能最終會花太多時間在無用的事情上。您需要先發現問題,然后采取相應措施。學習曲線有助于輕松檢測問題,從而節省大量時間。
學習曲線對于確定如何提高算法性能非常有用。確定算法是否遭受偏差或擬合不足,方差或擬合過度,或兩者兼而有之,這很有用。
精確度,召回率
如何處理機器學習中偏斜的數據集
用偏斜的數據集開發有效的機器學習算法可能很棘手。例如,數據集涉及銀行中的欺詐活動或癌癥檢測。發生的情況是,您將在數據集中看到99%的時間沒有欺詐活動或沒有癌癥。您可以很容易地作弊,并且始終可以僅預測0(如果癌癥則預測1,如果沒有癌癥則預測0),從而獲得99%的準確性。如果這樣做,我們將擁有99%的準確機器學習算法,但我們將永遠不會檢測到癌癥。如果某人患有癌癥,他/他將永遠得不到治療。在銀行中,不會采取任何針對欺詐活動的措施。因此,僅靠準確性就無法確定偏斜的數據集,就像算法是否有效運行一樣。
有不同的評估矩陣可以幫助處理這些類型的數據集。這些評估指標稱為精確召回評估指標。
要了精確度和召回率,您需要了解下表及其所有術語。考慮二進制分類。它將返回0或1。對于給定的訓練數據,如果實際類別為1,而預測類別也為1,則稱為真實肯定。如果實際類別為0,而預測類別為1,則為假陽性。如果實際類別為1,但預測類別為0,則稱為假陰性。如果實際類別和預測類別均為0,則為真陰性。
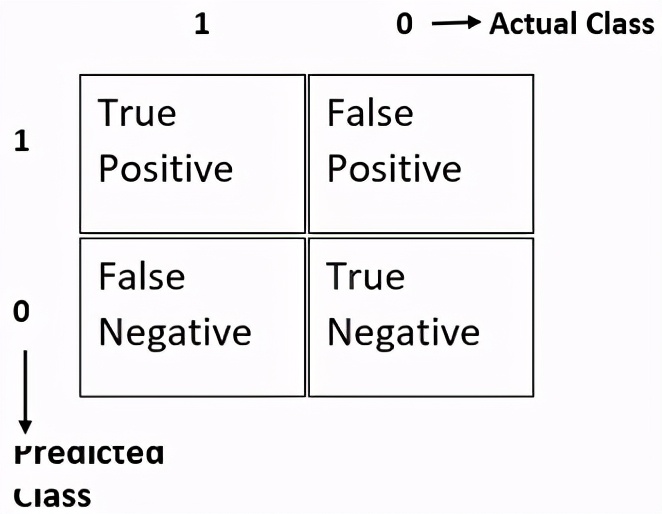
使用所有這些,我們將計算精度和召回率。
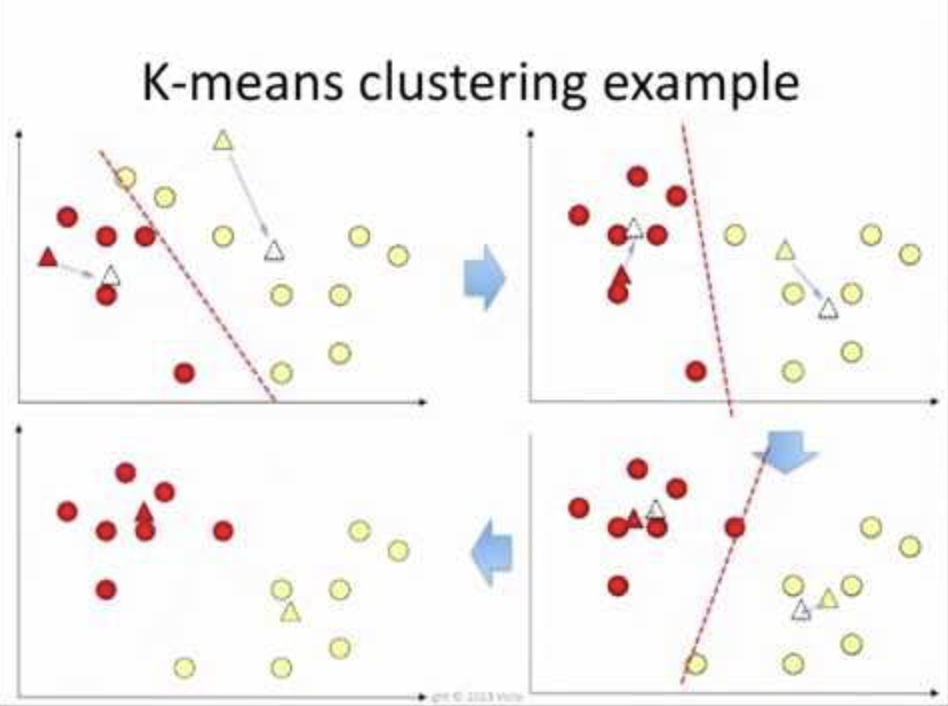
K均值聚類
K均值聚類是最流行和廣泛使用的無監督學習模型。它也稱為群集,因為它通過群集數據來工作。與監督學習模型不同,非監督模型不使用標記數據。
該算法的目的不是預測任何標簽。而是更好地了解數據集并對其進行標記。
在k均值聚類中,我們將數據集聚類為不同的組。
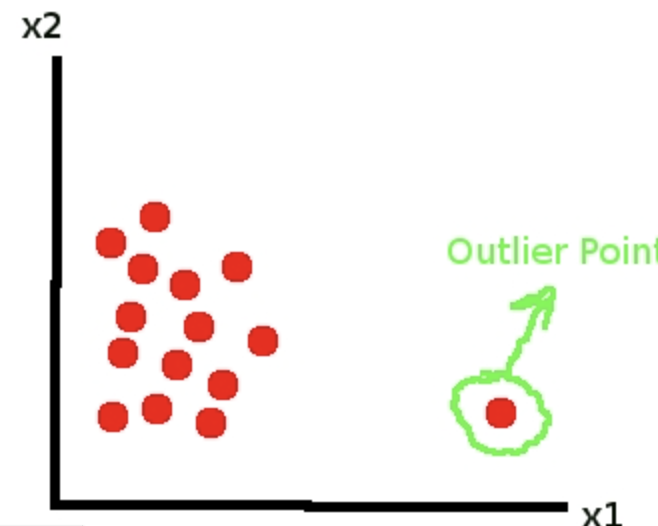
異常檢測
異常檢測可以作為離群分析的統計任務來對待。但是,如果我們開發一個機器學習模型,它可以自動化,并且像往常一樣可以節省大量時間。有很多異常檢測用例。信用卡欺詐檢測,故障機器檢測或基于其異常功能的硬件系統檢測,基于病歷的疾病檢測都是很好的例子。還有更多的用例。而且異常檢測的使用只會越來越多。
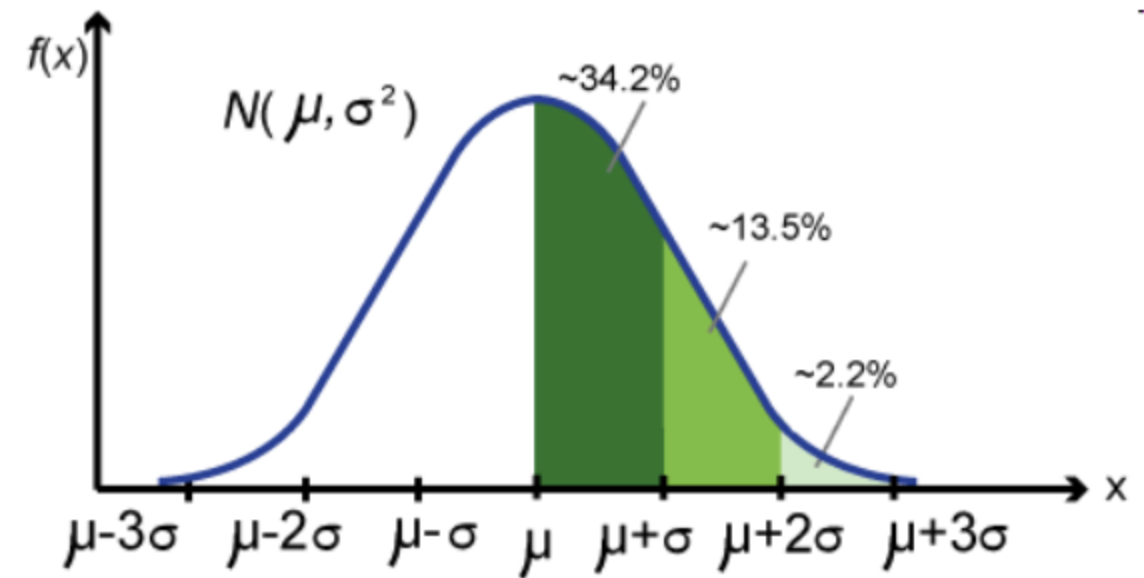
單變量和多元高斯分布
高斯分布是統計中最重要的概率分布,在機器學習中也很重要。因為許多自然現象,例如人口高度,血壓,鞋子的尺碼,諸如考試成績之類的教育手段以及自然界中許多其他重要方面,都傾向于遵循高斯分布。
我敢肯定,您聽說過這個詞,并且在某種程度上也知道。如果沒有,請不要擔心。本文將對其進行清晰的解釋。我在吳哥倫教授在Coursera的機器學習課程中發現了一些驚人的視覺效果。他知道如何將主題分解成小塊,使其變得更容易并進行詳細說明。
他使用了一些視覺效果,可以很容易地理解高斯分布及其與相關參數(例如均值,標準偏差和方差)的關系。
在本文中,我從他的課程中切出了一些視覺效果,并在這里用它來詳細解釋了高斯分布。
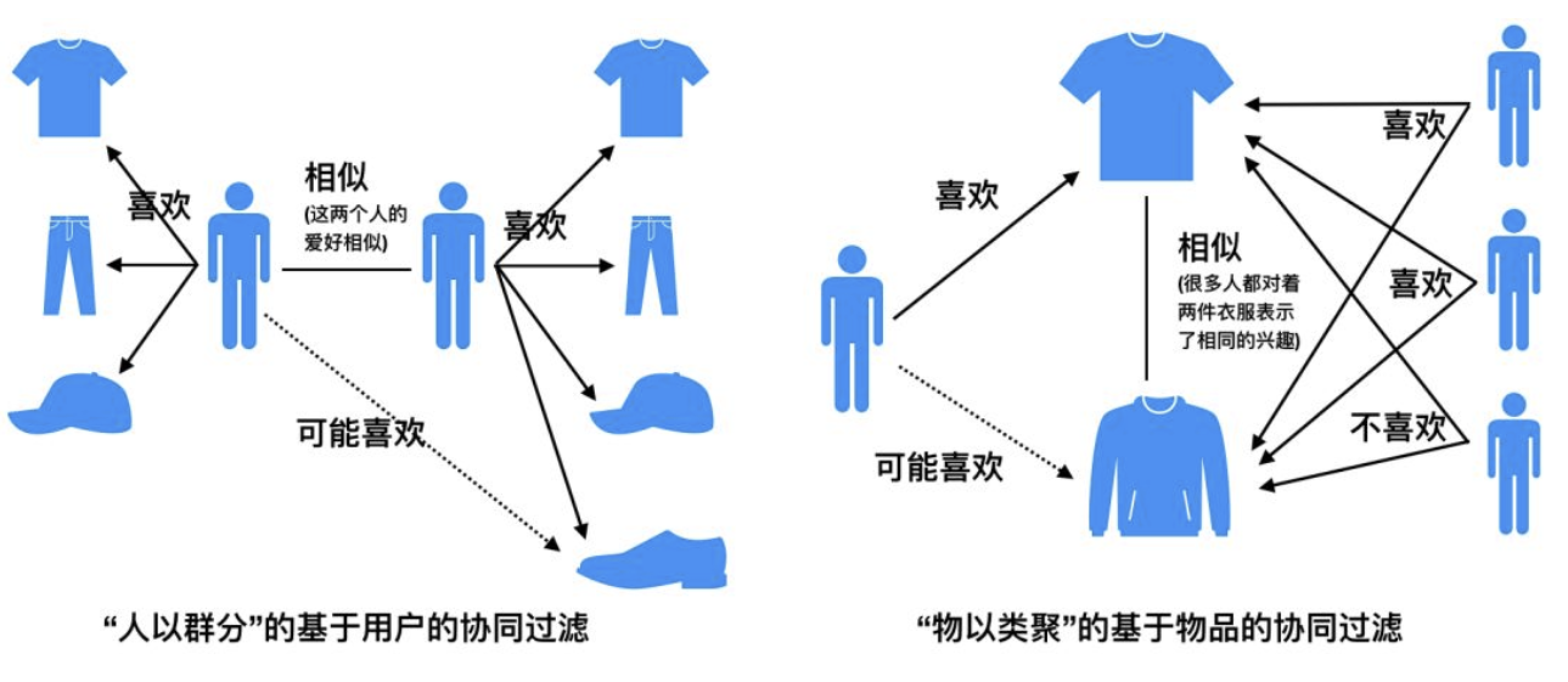
推薦系統
如今,我們到處都能看到推薦系統。當您在諸如Amazon,eBay或其他任何地方的在線市場上購買商品時,他們會推薦類似的產品。在Netflix或youtube上,您會在首頁上看到與以前的活動或搜索類似的建議。他們是如何做到的?他們都遵循這一想法。也就是說,他們從您之前的活動中獲取數據并進行相似性分析。根據該分析,他們會建議您喜歡的更多產品或視頻或電影。
希望這些課程能夠幫助你學習機器學習的基本知識,在新的一年里,解決更為復雜的問題。