時空AI技術:深度強化學習在智能城市領域應用介紹
深度強化學習是近年來熱起來的一項技術。深度強化學習的控制與決策流程必須包含狀態,動作,獎勵是三要素。在建模過程中,智能體根據環境的當前狀態信息輸出動作作用于環境,然后接收到下一時刻狀態信息和獎勵。以眾所周知的AlphaGo為例,盤面就是當前的狀態,動作就是下一步往哪里落子,獎勵就是最終的輸贏。整個強化學習過程就是不斷與環境交互,在交互的過程中產生數據,并利用這些交互產生的數據來學習的過程。正是在深度強化學習的幫助下,AlphaGo得以橫掃世界級頂尖棋手。所以相比于有監督學習方法,深度強化學習在特定場景下可以達到超越人類的水準。
在圍棋領域大放異彩之后,深度強化學習也在不斷地拓展著自己的疆域,游戲、金融等越來越多的領域也出現了深度強化學習的身影。現代城市作為人類生產、生活的核心區域,是一個匯聚了交通、物流、能源等多個產業的復雜綜合體。如果能夠優化這種復雜結構,那么將會帶來巨大的社會價值。而強化學習恰好可以做到這件事情。本文將為大家介紹幾個強化學習在智能城市領域的應用案例。
一、智能交通
在城市各種各樣的交通場景中,會遇到各種各樣的資源配置和交通調度難題。如圖3(a)所示,在一個典型的救護車輛調度場景中,救護車需要不斷地往返于患者和救護車站點。救護車的接車時間在很大程度上取決于移動救護車的動態重新部署策略。也就是說,在救護車可用之后,應該把它調到哪個車站。重新調配現有救護車會影響未來接載病人的時間。例如在圖3(b)中,未來將有3名患者來到1號站附近,因此將現有的救護車1號重新部署到1號站,通過從1號站派遣救護車,可以使這些患者迅速被接走。
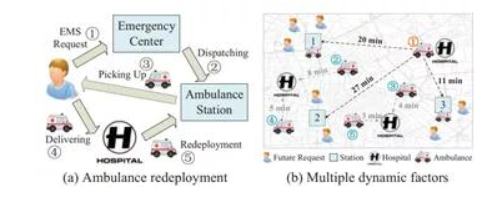
圖1 救護車調度場景
這一問題依然可以利用強化學習的方法來求解。文章[1]將需要調度的救護車都被作為智能體,建模的核心就是確定相應的狀態、動作以及獎勵。在這一場景中,影響救護車效率的因素主要包括未來車站附近的病人數量、車站救護車的數量以及救護車與車站的距離等。將這些指標進行一定的轉化,就可以提煉出病患密度、旅程時間等多個相關因子。這些相關因子就可以被作為輸入狀態。在這一場景中,決策變量,也就是救護車在完成接送任務后,被部署到不同的站點,就是智能體的動作。而優化目標,也就是將接載病人的時間,就是智能體的獎勵,時間越短,獎勵越大。理想情況下,每一輛救護車智能體都能夠找到一種優勢策略,讓平均接送時間最短。接下來,文章引入深度強化學習算法,對這一場景進行很好地求解。
文章使用在真實世界中收集的數據集來評估動態救護車重新部署方法。實驗結果表明,基于深度強化學習的救護車的重新部署方法明顯優于最先進的基準方法。具體來說,與基準方法相比,基于深度強化學習的方法可以將10分鐘內接診的患者比例從0.786提高到0.838,節省平均接診時間約20%(約100秒)。為了能夠增加及時拯救病人的可能性,每一秒都是至關重要的。
在交通場景中,還有很多與之相似地調度問題,例如共享單車調度、公交車輛路線規劃、出租車/網約車調度等。在這些場景中,都可以使用與之相類似的方法。此外,隨著物聯網技術的發展,未來各行各業的管理將進一步扁平化。一大批新的場景也會涌現出來。例如,交通信號燈的控制優化、自動駕駛的控制于決策,無人車輛的調度都屬于深度強化學習的應用場景。所以,強化學習技術在未來將會在未來的智能交通中起到重要作用。
二、智能物流
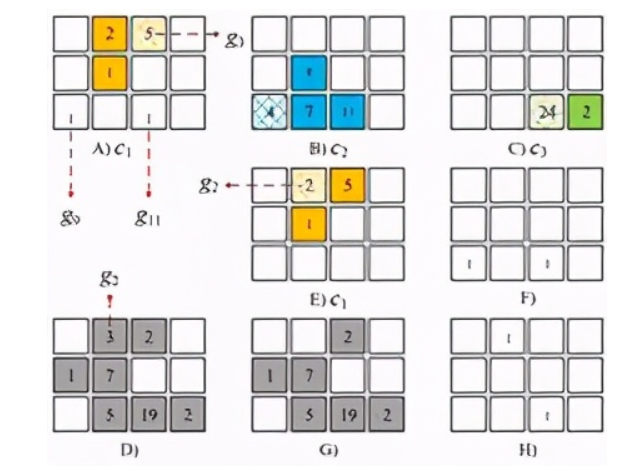
物流的發展極大地方便了人們,促進了電子商務的發展。但龐大的運單量卻帶來了很多管理問題,行業派單效率和配送效率普遍低下,導致了大量勞動力浪費。在快遞領域,配送員的任務量不均衡現象是普遍存在的。這導致部分快遞員任務量過飽和或不足。如果能夠根據任務的不同,動態規劃出每一個快遞員的任務進行規劃,那么就可以減弱這種資源不均衡現象,來提高資源利用率和任務完成率。但在現實中,快遞員需要同時肩負配送和取件兩項職能,還要兼顧整體地配送效率更高,這無疑會增加問題的復雜度。文章[2]利用深度強化學習來解決這一問題。在文章中,作者將整個空間粗略地劃分成若干小區域,由圖4中的小方格來表示。其中A、B、C分別表示三個快遞員c1、c2、c3在每一個小區域的剩余配送量,其中陰影的小區域表示快遞員當前的位置。D和G表示每一個小區域待取件的數量。F和H分別表示以快遞員c1、c2為視角,其他快遞員的位置。E表示快遞員c1由位置g3到達位置g2。在真實場景中,影響快遞員路線規劃的因素,包括剩余的配送位置、待取件的位置、隊友的位置、隊友的行進路線等,基本都可以被這一圖結構表達出來。所以這一圖結構就作為智能體的狀態。而智能體的動作則是快遞員的前進方向,如向左還是向右,獎勵就是為快遞員完成的任務量。完成的任務越多,獎勵越大。同樣,在確定了這三維核心指標后,就可以引入深度強化學習算法來求解。
我們可以推斷出,除了快遞員的路徑選擇,車輛的運輸、調度,也屬于相似的場景,也可以使用相似的方法來解決。甚至大型物流倉儲管理,也可以利用強化學習來建模。
三、智能能源
鍋爐燃燒優化是一個典型的智能控制場景。電站鍋爐系統高度復雜,包含磨煤、燃燒、水汽循環等多個環節,一個普通600MW中型火電機組就擁有上萬個傳感器測點,內部涉及燃燒、風煙、水熱循環等眾多物理化學過程非常復雜。純粹使用機理建模的方法很難對如此復雜的系統做精準化建模,導致系統描述失準,影響優化效果。
從控制優化角度來講,火電燃燒優化涉及上百個主要控制量(例如機組內部各種鍋爐給煤量、各種風門、閥門開度等),而且這些變量均為連續變量(例如某個閥門開度20%和開度25%可能對機組運行帶來非常不同的影響)。與此同時,當前動作所造成的影響往往不能夠實時反饋,所以還需要考慮到長期的影響。對于如此復雜的場景,即便是有多年豐富經驗的運行人員,也很少能夠總結出一套高效的調節策略。所以此類復雜系統高維連續變量控制優化問題是世界性的難題。
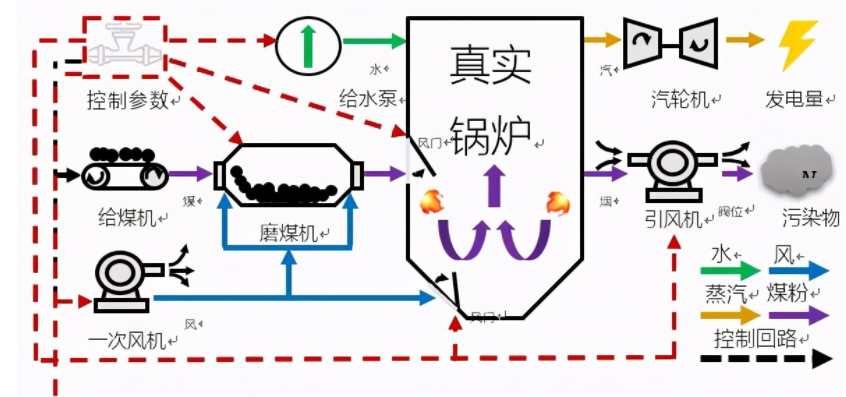
圖3 火電鍋爐運行流程
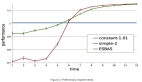
而深度強化學習恰恰適合來做這件事情。圖2展示了我們基于強化學習的建模流程。對于一個典型的鍋爐環境,我們可以得到很多的傳感器提供系統的狀態描述,例如鍋爐中各種溫度、風量、水量、壓力等監測值。我們可以把這些實時反饋的監測值作為狀態,也就是智能體能夠“看到”的東西。然后我們將給煤量、各種風門、閥門開度等控制變量作為動作。在確定了狀態和動作,我們利用一個業務指標(燃燒效率)作為獎勵。智能體依據當前的狀態輸出動作,對鍋爐控制參數進行調節,鍋爐環境就會產生一個變化,到達一個新的狀態,如果燃燒效率朝著好的方向變化,我們就給一個正向的獎勵,如果是不好的變化,我們可以給一個負向的獎勵。在完成了建模工作后,我們接下來通過合理的學習算法,就可以學習出更好的策略。學習算法通過觀察很多的從狀態和動作到下一個狀態的變化過程,從中抽象狀態——動作——獎勵的對應模式,最終找到一個最佳的控制策略,可以從當前的狀態映射到最佳的控制(動作)變量,實現長期平均獎勵的最大化。
在上機實測過程中,基于強化學習的控制策略相比于人類操作達到了0.5%的效率提升,對于一臺600MW機組,相當于年經濟效益240萬元。與此同時,我們已經實現了對于AI模型的產品化,具備了批量復制的能力,并在多個電廠落地并完成了驗收。
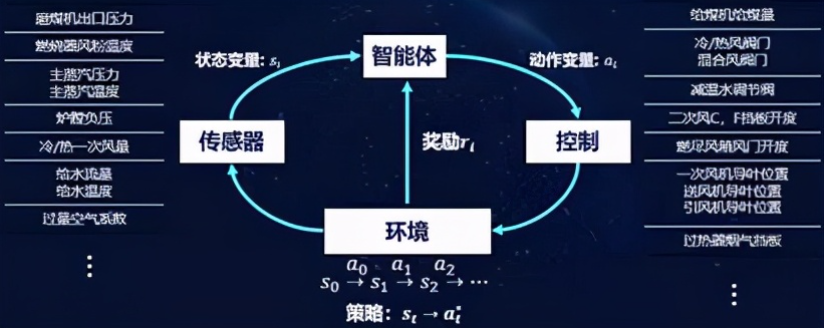
圖4 基于強化學習的燃燒優化智能體
除了燃燒優化場景之外,在火電中,我們也已經將強化學習方法用在了磨煤機控制優化、冷端優化等場景中,并取得了很好的效果。上文所述的控制場景,強化學習也可以在溫度控制、電網調度、能源管理等領域得到應用。另外,火電鍋爐的控制屬于典型的過程控制。在工業生產中,水泥生產過程中的磨機控制,機場ACDM系統中的車輛與人員調度、停機位優化,以及鋼鐵制造、化工等工業場景也均屬于相似的場景。在這些場景中,可以提煉出來大量的控制與優化問題,深度強化學習技術也具有著廣闊的空間。
通過案例我們可以看到,對于一個現實中的場景,如果能夠確定影響的相關因素、優化動作以及優化目標,深度強化學習技術將可以隆重登場了。而這些場景在我們的生產生活中是大量存在的。所以在未來的智能城市與產業中,深度強化學習技術會起到重要的作用。但是就目前來說,深度強化學習的落地仍存在一些局限。這其中一部分原因是算法的學習效率仍不夠高效,適應場景也較為狹窄,另外一部分原因是目前很多行業的數字化程度還比較低。但隨著物聯網時代的到來,這一問題將會被逐步解決。與此同時,隨著大批研究人員的前仆后繼,深度強化學習本身的技術也在不斷地迭代發展,算法適用的范圍也越來越廣泛。未來的發展一定越來越好。
參考文獻
[1] Shenggong Ji,et.al A Deep ReinforcementLearning-Enabled Dynamic Redeployment System for Mobile Ambulances. UbiComp2019
[2] Li Y, Zheng Y, Yang Q. Efficient and Effective Expressvia Contextual Cooperative Reinforcement Learning[C]//Proceedings of the 25thACM SIGKDD International Conference on Knowledge Discovery & Data Mining.2019: 510-519.