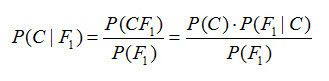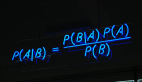Java實現基于樸素貝葉斯的情感詞分析
樸素貝葉斯(Naive Bayesian)是一種基于貝葉斯定理和特征條件獨立假設的分類方法,它是基于概率論的一種有監督學習方法,被廣泛應用于自然語言處理,并在機器學習領域中占據了非常重要的地位。在之前做過的一個項目中,就用到了樸素貝葉斯分類器,將它應用于情感詞的分析處理,并取得了不錯的效果,本文我們就來介紹一下樸素貝葉斯分類的理論基礎和它的實際使用。
在學習樸素貝葉斯分類以及正式開始情感詞分析之前,我們首先需要了解一下貝葉斯定理的數學基礎。
貝葉斯定理
貝葉斯定理是關于隨機事件A和B的條件概率的定理,公式如下:
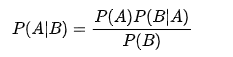
在上面的公式中,每一項表示的意義如下:
- P(A):先驗概率(prior probability),是在沒有任何條件限制下事件A發生的概率,也叫基礎概率,是對A事件概率的一個主觀判斷
- P(A|B):在B發生的情況下A發生的可能性,也被稱為A的后驗概率(posterior probability)
- P(B|A):似然性,也被稱為條件似然(conditional likelihood)
- P(B):不論A是否發生,在所有情況下B發生的概率,它被稱為整體似然或歸一化常量(normalizing constant)
按照上面的解釋,貝葉斯定理可以表述為:
- 后驗概率 = 先驗概率 * 似然性 / 歸一化常量
通俗的來說,可以理解為當我們不能確定某一個事件發生的概率時,可以依靠與該事件本質屬性相關的事件發生的概率去推測該事件發生的概率。用數學語言來表達就是,支持某項屬性的事件發生得愈多,則該事件發生的的可能性就愈大,這個推理過程也被叫做貝葉斯推理。
在查閱的一些文檔中,P(B|A)/P(B) 可以被稱為可能性函數,它作為一個調整因子,表示新信息B對事件A帶來的調整,作用是將先驗概率(主觀判斷)調整到更接近真實的概率。那么,貝葉斯定理也可以理解為:
- 新信息出現后A的概率 = A的先驗概率 * 新信息帶來的調整
舉一個例子,方便大家更直觀的理解這一過程。假設統計了一段時間內天氣和氣溫對于運動情況的影響,如下所示:
- 天氣 氣溫 運動
- 晴天 非常高 游泳
- 晴天 高 足球
- 陰天 中 釣魚
- 陰天 中 游泳
- 晴天 低 游泳
- 陰天 低 釣魚
現在請計算在晴天,氣溫適中的情況下,去游泳的概率是多少?根據貝葉斯定理,計算過程如下:
- P(游泳|晴天,中溫)=P(晴天,中溫|游泳)*P(游泳)/P(晴天,中溫)
- =P(晴天|游泳)*P(中溫|游泳)*P(游泳)/[P(晴天)*P(中溫)]
- =2/3 * 1/3 *1/2 / (1/2 *1/3 )
- =2/3
最終得出去游泳的概率是2/3,上面就是基于貝葉斯定理,根據給定的特征,計算事件發生概率大小的過程。
貝葉斯分析的思路對于由證據的積累來推測一個事物的發生的概率具有重大作用,當我們要預測一個事物,首先會根據已有的經驗和知識推斷一個先驗概率,然后在新證據不斷的積累的情況下調整這個概率。整個通過累積證據來得到一個事件發生概率的過程我們稱為貝葉斯分析。這樣,貝葉斯底層的思想就可以概括為,如果能夠掌握一個事情的全部信息,就能夠計算出它的一個客觀概率。
另外,在貝葉斯公式的基礎上進行變形,可以得到下面的公式:
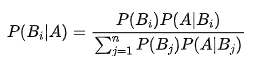
其中B1,B2,…,Bj是一個完備事件組,上面的公式可以表示在事件A已經發生的條件下,尋找導致A發生的各種“原因”的Bi的概率。
樸素貝葉斯
在學習樸素貝葉斯之前,首先需要對貝葉斯分類進行一下了解,貝葉斯分類通過預測一個對象屬于某個類別的概率,通過比較不同類別概率的大小預測其最可能從屬的類別,是基于貝葉斯定理而構成出來的。在處理大規模數據集時,貝葉斯分類器表現出較高的分類準確性。
貝葉斯分類在處理一個未知類型的樣本X時,可以先算出X屬于每一個類別Ci的概率 P(Ci|X),然后選擇其中概率最大的類別。假設有兩個特征變量x和y,并且存在兩個分類類別C1和C2,結合貝葉斯定理:
- 如果P(C1|x,y) > P(C2|x,y),說明在x和y發生的條件下,C1比C2發生的概率要大,那么它應該屬于類別C1
- 反之如果P(C1|x,y) < P(C2|x,y),那么它應該屬于類別C2
而樸素貝葉斯模型(Naive Bayesian Model)作為一種強大的預測建模算法,它在貝葉斯定理的基礎上進行了簡化,假定了目標的特征屬性之間相互獨立,這也是它被形容為“樸素”的原因。在實際情況中如果屬性之間存在關聯,那么分類準確率會降低,不過對于解決絕大部分的復雜問題非常有效。
設在樣本數據集D上,樣本數據的特征屬性集為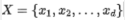 ,類變量可被分為
,類變量可被分為 ,即數據集D可以被分為
,即數據集D可以被分為 個類別。我們假設
個類別。我們假設 相互獨立,那么由貝葉斯定理可得:
相互獨立,那么由貝葉斯定理可得:
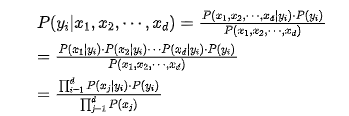
對于相同的測試樣本,分母P(X)的大小是固定不變的,因此在比較后驗概率時,我們可以只比較分子的大小即可。
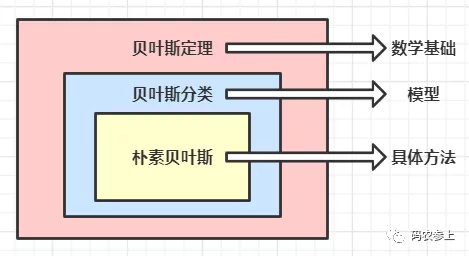
在這里解釋一下貝葉斯定理、貝葉斯分類和樸素貝葉斯之間的區別,貝葉斯定理作為理論基礎,解決了概率論中的逆概率問題,在這個基礎上人們設計出了貝葉斯分類器,而樸素貝葉斯是貝葉斯分類器中的一種,也是最簡單和常用的分類器,可以使用下面的圖來表示它們之間的關系:
在實際應用中,樸素貝葉斯有廣泛的應用,在文本分類、垃圾郵件過濾、情感預測及釣魚網站的檢測方面都能夠起到良好的效果。為了訓練樸素貝葉斯模型,我們需要先在訓練集的基礎上對分類好的數據進行訓練,計算出先驗概率和每個屬性的條件概率,計算完成后,概率模型就可以使用貝葉斯原理對新數據進行預測。
貝葉斯推斷與人腦的工作機制很像,這也是它為什么能夠成為機器學習的基礎,大腦的決策過程就是先對事物進行主觀判斷,然后搜集新的信息,優化主觀判斷,如果新的信息符合這個主觀判斷,那就提高主觀判斷的可信度,如果不符合,就降低主觀判斷的可信度。
代碼實現
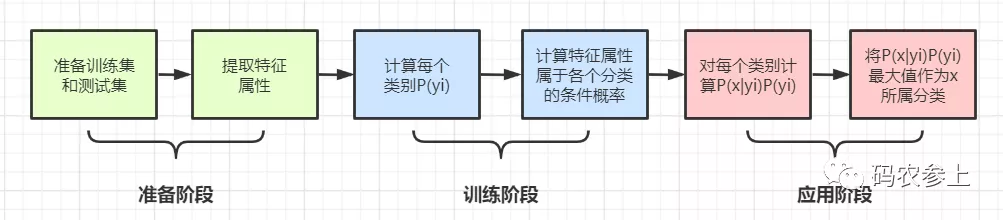
在對理論有了基本的了解后,我們開始分析怎樣將樸素貝葉斯應用于我們文本處理的情感詞分析中。主要步驟如下:
- 對訓練集和測試集完成文本分詞,并通過主觀判斷標注所屬的分類
- 對訓練集進行訓練,統計每個詞匯出現在分類下的次數,計算每個類別在訓練樣本中的出現頻率、及每個特征屬性對每個類別的條件概率(即似然概率)
- 將訓練好的模型應用于測試集的樣本上,根據貝葉斯分類計算樣本在每個分類下的概率大小
- 比較在各個分類情況下的概率大小,推測文本最可能屬于的情感分類
使用流程圖表示:
1、準備階段
首先準備數據集,這里使用了對某酒店的評論數據,根據主觀態度將其分為“好評”或“差評”這兩類待分類項,對每行分詞后的語句打好了情感標簽,并且已經提前對完整語句完成了對分詞,數據格式如下:

在每行的數據的頭部,是添加的“好評”或“差評”標簽,標簽與分詞采用tab分割,詞語之間使用空格分割。按照比例,將數據集的80%作為訓練集,剩余20%作為測試集,分配過程盡量保證隨機原則。
2、訓練階段
在訓練階段,主要完成詞頻的統計工作。讀取訓練集,統計出每個詞屬于該分類下出現的次數,用于后續求解每個詞出現在各個類別下的概率,即詞匯與主觀分類情感之間的關系:
- private static void train(){
- Map<String,Integer> parameters = new HashMap<>();
- try(BufferedReader br = new BufferedReader(new FileReader(trainingData))){ //訓練集數據
- String sentence;
- while(null!=(sentence=br.readLine())){
- String[] content = sentence.split("\t| "); //以tab或空格分詞
- parameters.put(content[0],parameters.getOrDefault(content[0],0)+1);
- for (int i = 1; i < content.length; i++) {
- parameters.put(content[0]+"-"+content[i], parameters.getOrDefault(content[0]+"-"+content[i], 0)+1);
- }
- }
- }catch (IOException e){
- e.printStackTrace();
- }
- saveModel(parameters);
- }
將訓練好的模型保存到文件中,可以方便在下次使用時不用重復進行模型的訓練:
- private static void saveModel(Map<String,Integer> parameters){
- try(BufferedWriter bw =new BufferedWriter(new FileWriter(modelFilePath))){
- parameters.keySet().stream().forEach(key->{
- try {
- bw.append(key+"\t"+parameters.get(key)+"\r\n");
- } catch (IOException e) {
- e.printStackTrace();
- }
- });
- bw.flush();
- }catch (IOException e){
- e.printStackTrace();
- }
- }
查看保存好的模型,數據的格式如下:
- 好評-免費送 3
- 差評-真煩 1
- 好評-禮品 3
- 差評-臟亂差 6
- 好評-解決 15
- 差評-挨宰 1
- ……
這里對訓練的模型進行保存,所以如果后續有同樣的分類任務時,可以直接在訓練集的基礎上進行計算,對于分類速度要求較高的任務,能夠有效的提高計算的速度。
3、加載模型
加載訓練好的模型:
- private static HashMap<String, Integer> parameters = null; //用于存放模型
- private static Map<String, Double> catagory=null;
- private static String[] labels = {"好評", "差評", "總數","priorGood","priorBad"};
- private static void loadModel() throws IOException {
- parameters = new HashMap<>();
- List<String> parameterData = Files.readAllLines(Paths.get(modelFilePath));
- parameterData.stream().forEach(parameter -> {
- String[] split = parameter.split("\t");
- String key = split[0];
- int value = Integer.parseInt(split[1]);
- parameters.put(key, value);
- });
- calculateCatagory(); //分類
- }
對詞進行分類,統計出好評及差評的詞頻總數,并基于它們先計算得出先驗概率:
- //計算模型中類別的總數
- public static void calculateCatagory() {
- catagory = new HashMap<>();
- double good = 0.0; //好評詞頻總數
- double bad = 0.0; //差評的詞頻總數
- double total; //總詞頻
- for (String key : parameters.keySet()) {
- Integer value = parameters.get(key);
- if (key.contains("好評-")) {
- good += value;
- } else if (key.contains("差評-")) {
- bad += value;
- }
- }
- total = good + bad;
- catagory.put(labels[0], good);
- catagory.put(labels[1], bad);
- catagory.put(labels[2], total);
- catagory.put(labels[3],good/total); //好評先驗概率
- catagory.put(labels[4],bad/total); //差評先驗概率
- }
查看執行完后的統計值:
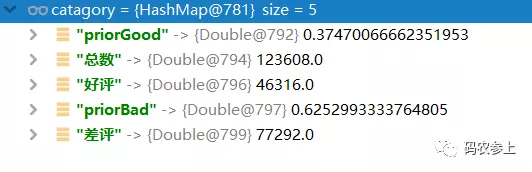
“好評”對應的詞匯出現的總次數是46316個,“差評”對應的詞匯出現的總次數是77292個,訓練集詞頻總數為123608個,并可基于它們計算出它們的先驗概率:
- 該文檔屬于某個類別的條件概率= 該類別的所有詞條詞頻總數 / 所有詞條的詞頻總數
4、測試階段
測試階段,加載我們提前準備好的測試集,對每一行分詞后的評論語句進行主觀情感的預測:
- private static void predictAll() {
- double accuracyCount = 0.;//準確個數
- int amount = 0; //測試集數據總量
- try (BufferedWriter bw = new BufferedWriter(new FileWriter(outputFilePath))) {
- List<String> testData = Files.readAllLines(Paths.get(testFilePath)); //測試集數據
- for (String instance : testData) {
- String conclusion = instance.substring(0, instance.indexOf("\t")); //已經打好的標簽
- String sentence = instance.substring(instance.indexOf("\t") + 1);
- String prediction = predict(sentence); //預測結果
- bw.append(conclusion + " : " + prediction + "\r\n");
- if (conclusion.equals(prediction)) {
- accuracyCount += 1.;
- }
- amount += 1;
- }
- //計算準確率
- System.out.println("accuracyCount: " + accuracyCount / amount);
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
在測試中,調用下面的predict方法進行分類判斷。在計算前,再來回顧一下上面的公式,在程序中進行簡化運算:
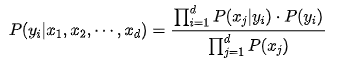
對于同一個預測樣本,分母相同,所以我們可以只比較分子 的大小。對分子部分進行進一步簡化,對于連乘預算,我們可以對其進行對數操作,變成各部分相加:
的大小。對分子部分進行進一步簡化,對于連乘預算,我們可以對其進行對數操作,變成各部分相加:
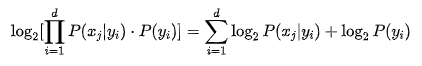
這樣對于概率的大小比較,就可以簡化為比較 先驗概率和各個似然概率分別取對數后相加的和。先驗概率我們在之前的步驟中已經計算完成并保存,所以這里只計算各詞匯在分類條件下的似然概率即可。predict方法的實現如下:
- private static String predict(String sentence) {
- String[] features = sentence.split(" ");
- String prediction;
- //分別預測好評和差評
- double good = likelihoodSum(labels[0], features) + Math.log(catagory.get(labels[3]));
- double bad = likelihoodSum(labels[1], features) + Math.log(catagory.get(labels[4]));
- return good >= bad?labels[0]:labels[1];
- }
在其中調用likelihood方法計算似然概率的對數和:
- //似然概率的計算
- public static double likelihoodSum(String label, String[] features) {
- double p = 0.0;
- Double total = catagory.get(label) + 1;//分母平滑處理
- for (String word : features) {
- Integer count = parameters.getOrDefault(label + "-" + word, 0) + 1;//分子平滑處理
- //計算在該類別的情況下是該詞的概率,用該詞的詞頻除以類別的總詞頻
- p += Math.log(count / total);
- }
- return p;
- }
在計算似然概率的方法中,如果出現在訓練集中沒有包括的詞匯,那么會出現它的似然概率為0的情況,為了防止這種情況,對分子分母進行了分別加1的平滑操作。
最后在主函數中調用上面的步驟,最終如果計算出基于樣本的好評概率大于等于差評概率,那么將它分類劃入“好評”,反之劃入“差評”類別,到此就完成了訓練和測試的全過程:
- public static void main(String[] args) throws IOException {
- train();
- loadModel();
- predictAll();
- }
執行全部代碼,結果如下,可以看到獲取了93.35%的準確率。
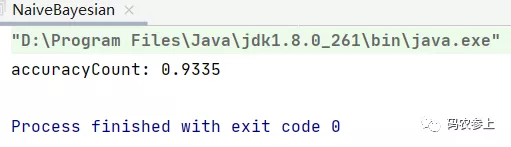
對比最后輸出的文檔中的標簽與預測結果,可以看到,預測結果的準確度還是非常高的。
5、總結
在上面的例子中,還有一些可以進行改進的地方,例如可以在前期建立情感詞庫,在特征值提取的過程中只提取情感詞,去除其余無用詞匯(如介詞等)對分類的影響,只選取關鍵的代表詞作為特征提取,達到更高的分類效率。另外,可以在建立詞庫時,將測試集的情感詞也放入詞庫,避免出現在某個分類條件下似然概率為零的情況,簡化平滑步驟。
此外,樸素貝葉斯的分類對于追加訓練集的情況有很好的應用,如果訓練集不斷的增加,可以在現有訓練模型的基礎上添加新的樣本值、或對已有的樣本值的屬性進行修改,在此基礎上,可以實現增量的模型修改。