Python中組合分類和回歸的神經網絡模型
Python中文社區 (ID:python-china)
某些預測問題需要為同一輸入預測數字值和類別標簽。一種簡單的方法是在同一數據上開發回歸和分類預測模型,然后依次使用這些模型。另一種通常更有效的方法是開發單個神經網絡模型,該模型可以根據同一輸入預測數字和類別標簽值。這被稱為多輸出模型,使用現代深度學習庫(例如Keras和TensorFlow)可以相對容易地開發和評估。
在本教程中,您將發現如何開發用于組合回歸和分類預測的神經網絡。完成本教程后,您將知道:
- 一些預測問題需要為每個輸入示例預測數字和類別標簽值。
- 如何針對需要多個輸出的問題開發單獨的回歸和分類模型。
- 如何開發和評估能夠同時進行回歸和分類預測的神經網絡模型。
教程概述
本教程分為三個部分:他們是:
- 回歸和分類的單一模型
- 單獨的回歸和分類模型
鮑魚數據集
回歸模型
分類模型
- 組合回歸和分類模型
回歸和分類的單一模型
開發用于回歸或分類問題的深度學習神經網絡模型是很常見的,但是在某些預測建模任務上,我們可能希望開發一個可以進行回歸和分類預測的單一模型。回歸是指涉及預測給定輸入的數值的預測建模問題。分類是指預測建模問題,涉及預測給定輸入的類別標簽或類別標簽的概率。
我們可能要預測數值和分類值時可能會有一些問題。解決此問題的一種方法是為每個所需的預測開發一個單獨的模型。這種方法的問題在于,由單獨的模型做出的預測可能會有所不同。使用神經網絡模型時可以使用的另一種方法是開發單個模型,該模型能夠對相同輸入的數字和類輸出進行單獨的預測。這稱為多輸出神經網絡模型。這種類型的模型的好處在于,我們有一個模型可以開發和維護,而不是兩個模型,并且同時在兩種輸出類型上訓練和更新模型可以在兩種輸出類型之間的預測中提供更大的一致性。我們將開發一個能夠同時進行回歸和分類預測的多輸出神經網絡模型。
首先,讓我們選擇一個滿足此要求的數據集,并從為回歸和分類預測開發單獨的模型開始。
單獨的回歸和分類模型
在本節中,我們將從選擇一個實際數據集開始,在該數據集中我們可能需要同時進行回歸和分類預測,然后針對每種類型的預測開發單獨的模型。
鮑魚數據集
我們將使用“鮑魚”數據集。確定鮑魚的年齡是一項耗時的工作,并且希望僅根據物理細節來確定鮑魚的年齡。這是一個描述鮑魚物理細節的數據集,需要預測鮑魚的環數,這是該生物年齡的代名詞。
“年齡”既可以預測為數值(以年為單位),也可以預測為類別標簽(按年為普通年)。無需下載數據集,因為我們將作為工作示例的一部分自動下載它。數據集提供了一個數據集示例,我們可能需要輸入的數值和分類。
首先,讓我們開發一個示例來下載和匯總數據集。
- # load and summarize the abalone dataset
- from pandas import read_csv
- from matplotlib import pyplot
- # load dataset
- url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/abalone.csv'
- dataframe = read_csv(url, header=None)
- # summarize shape
- print(dataframe.shape)
- # summarize first few lines
- print(dataframe.head())
首先運行示例,然后下載并匯總數據集的形狀。我們可以看到有4,177個示例(行)可用于訓練和評估模型,還有9個要素(列)包括目標變量。我們可以看到,除了第一個字符串值之外,所有輸入變量都是數字變量。為了簡化數據準備,我們將從模型中刪除第一列,并著重于對數字輸入值進行建模。
- (4177, 9)
- 012345678
- 0 M 0.4550.3650.0950.51400.22450.10100.15015
- 1 M 0.3500.2650.0900.22550.09950.04850.0707
- 2 F 0.5300.4200.1350.67700.25650.14150.2109
- 3 M 0.4400.3650.1250.51600.21550.11400.15510
- 4 I 0.3300.2550.0800.20500.08950.03950.0557
我們可以將數據用作開發單獨的回歸和分類多層感知器(MLP)神經網絡模型的基礎。
注意:我們并未嘗試為此數據集開發最佳模型;相反,我們正在展示一種特定的技術:開發可以進行回歸和分類預測的模型。
回歸模型
在本節中,我們將為鮑魚數據集開發回歸MLP模型。首先,我們必須將各列分為輸入和輸出元素,并刪除包含字符串值的第一列。我們還將強制所有加載的列都具有浮點類型(由神經網絡模型期望)并記錄輸入特征的數量,稍后模型需要知道這些特征。
- # split into input (X) and output (y) variables
- X, y = dataset[:, 1:-1], dataset[:, -1]
- X, y = X.astype('float'), y.astype('float')
- n_features = X.shape[1]
接下來,我們可以將數據集拆分為訓練和測試數據集。我們將使用67%的隨機樣本來訓練模型,而剩余的33%則用于評估模型。
- # split data into train and test sets
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
然后,我們可以定義一個MLP神經網絡模型。該模型將具有兩個隱藏層,第一個具有20個節點,第二個具有10個節點,都使用ReLU激活和“正常”權重初始化(一種好的做法)。層數和節點數是任意選擇的。輸出層將具有用于預測數值和線性激活函數的單個節點。
- # define the keras model
- model = Sequential()
- model.add(Dense(20, input_dim=n_features, activation='relu', kernel_initializer='he_normal'))
- model.add(Dense(10, activation='relu', kernel_initializer='he_normal'))
- model.add(Dense(1, activation='linear'))
使用隨機梯度下降的有效Adam版本,將訓練模型以最小化均方誤差(MSE)損失函數。
- # compile the keras model
- model.compile(loss='mse', optimizer='adam')
我們將訓練150個紀元的模型,并以32個樣本的小批量為樣本,再次任意選擇。
- # fit the keras model on the dataset
- model.fit(X_train, y_train, epochs=150, batch_size=32, verbose=2)
最后,在訓練完模型后,我們將在保持測試數據集上對其進行評估,并報告平均絕對誤差(MAE)。
- # evaluate on test set
- yhat = model.predict(X_test)
- error = mean_absolute_error(y_test, yhat)
- print('MAE: %.3f'% error)
綜上所述,下面列出了以回歸問題為框架的鮑魚數據集的MLP神經網絡的完整示例。
- # regression mlp model for the abalone dataset
- from pandas import read_csv
- from tensorflow.keras.models importSequential
- from tensorflow.keras.layers importDense
- from sklearn.metrics import mean_absolute_error
- from sklearn.model_selection import train_test_split
- # load dataset
- url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/abalone.csv'
- dataframe = read_csv(url, header=None)
- dataset = dataframe.values
- # split into input (X) and output (y) variables
- X, y = dataset[:, 1:-1], dataset[:, -1]
- X, y = X.astype('float'), y.astype('float')
- n_features = X.shape[1]
- # split data into train and test sets
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
- # define the keras model
- model = Sequential()
- model.add(Dense(20, input_dim=n_features, activation='relu', kernel_initializer='he_normal'))
- model.add(Dense(10, activation='relu', kernel_initializer='he_normal'))
- model.add(Dense(1, activation='linear'))
- # compile the keras model
- model.compile(loss='mse', optimizer='adam')
- # fit the keras model on the dataset
- model.fit(X_train, y_train, epochs=150, batch_size=32, verbose=2)
- # evaluate on test set
- yhat = model.predict(X_test)
- error = mean_absolute_error(y_test, yhat)
- print('MAE: %.3f'% error)
運行示例將準備數據集,擬合模型并報告模型誤差的估計值。
注意:由于算法或評估程序的隨機性,或者數值精度的差異,您的結果可能會有所不同。考慮運行該示例幾次并比較平均結果。
在這種情況下,我們可以看到該模型實現了約1.5 的誤差。
- Epoch145/150
- 88/88- 0s- loss: 4.6130
- Epoch146/150
- 88/88- 0s- loss: 4.6182
- Epoch147/150
- 88/88- 0s- loss: 4.6277
- Epoch148/150
- 88/88- 0s- loss: 4.6437
- Epoch149/150
- 88/88- 0s- loss: 4.6166
- Epoch150/150
- 88/88- 0s- loss: 4.6132
- MAE: 1.554
到目前為止,一切都很好。接下來,讓我們看一下開發類似的分類模型。
分類模型
鮑魚數據集可以歸類為一個分類問題,其中每個“環”整數都被當作一個單獨的類標簽。該示例和模型與上述回歸示例非常相似,但有一些重要的變化。這要求首先為每個“ ring”值分配一個單獨的整數,從0開始,以“ class”總數減1結束。這可以使用LabelEncoder實現。我們還可以將類的總數記錄為唯一編碼的類值的總數,稍后模型會需要。
- # encode strings to integer
- y = LabelEncoder().fit_transform(y)
- n_class = len(unique(y))
將數據像以前一樣分為訓練集和測試集后,我們可以定義模型并將模型的輸出數更改為等于類數,并使用對于多類分類通用的softmax激活函數。
- # define the keras model
- model = Sequential()
- model.add(Dense(20, input_dim=n_features, activation='relu', kernel_initializer='he_normal'))
- model.add(Dense(10, activation='relu', kernel_initializer='he_normal'))
- model.add(Dense(n_class, activation='softmax'))
假設我們已將類別標簽編碼為整數值,則可以通過最小化適用于具有整數編碼類別標簽的多類別分類任務的稀疏類別交叉熵損失函數來擬合模型
- # compile the keras model
- model.compile(loss='sparse_categorical_crossentropy', optimizer='adam')
在像以前一樣將模型擬合到訓練數據集上之后,我們可以通過計算保留測試集上的分類準確性來評估模型的性能。
- # evaluate on test set
- yhat = model.predict(X_test)
- yhat = argmax(yhat, axis=-1).astype('int')
- acc = accuracy_score(y_test, yhat)
- print('Accuracy: %.3f'% acc)
綜上所述,下面列出了針對鮑魚數據集的MLP神經網絡的完整示例,該示例被歸類為分類問題。
- # classification mlp model for the abalone dataset
- from numpy import unique
- from numpy import argmax
- from pandas import read_csv
- from tensorflow.keras.models importSequential
- from tensorflow.keras.layers importDense
- from sklearn.metrics import accuracy_score
- from sklearn.model_selection import train_test_split
- from sklearn.preprocessing importLabelEncoder
- # load dataset
- url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/abalone.csv'
- dataframe = read_csv(url, header=None)
- dataset = dataframe.values
- # split into input (X) and output (y) variables
- X, y = dataset[:, 1:-1], dataset[:, -1]
- X, y = X.astype('float'), y.astype('float')
- n_features = X.shape[1]
- # encode strings to integer
- y = LabelEncoder().fit_transform(y)
- n_class = len(unique(y))
- # split data into train and test sets
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
- # define the keras model
- model = Sequential()
- model.add(Dense(20, input_dim=n_features, activation='relu', kernel_initializer='he_normal'))
- model.add(Dense(10, activation='relu', kernel_initializer='he_normal'))
- model.add(Dense(n_class, activation='softmax'))
- # compile the keras model
- model.compile(loss='sparse_categorical_crossentropy', optimizer='adam')
- # fit the keras model on the dataset
- model.fit(X_train, y_train, epochs=150, batch_size=32, verbose=2)
- # evaluate on test set
- yhat = model.predict(X_test)
- yhat = argmax(yhat, axis=-1).astype('int')
- acc = accuracy_score(y_test, yhat)
- print('Accuracy: %.3f'% acc)
運行示例將準備數據集,擬合模型并報告模型誤差的估計值。
注意:由于算法或評估程序的隨機性,或者數值精度的差異,您的結果可能會有所不同。考慮運行該示例幾次并比較平均結果。
在這種情況下,我們可以看到該模型的準確度約為27%。
- Epoch145/150
- 88/88- 0s- loss: 1.9271
- Epoch146/150
- 88/88- 0s- loss: 1.9265
- Epoch147/150
- 88/88- 0s- loss: 1.9265
- Epoch148/150
- 88/88- 0s- loss: 1.9271
- Epoch149/150
- 88/88- 0s- loss: 1.9262
- Epoch150/150
- 88/88- 0s- loss: 1.9260
- Accuracy: 0.274
到目前為止,一切都很好。接下來,讓我們看一下開發一種能夠同時進行回歸和分類預測的組合模型。
組合回歸和分類模型
在本節中,我們可以開發一個單一的MLP神經網絡模型,該模型可以對單個輸入進行回歸和分類預測。這稱為多輸出模型,可以使用功能性Keras API進行開發。
首先,必須準備數據集。盡管我們應該使用單獨的名稱保存編碼后的目標變量以將其與原始目標變量值區分開,但是我們可以像以前一樣為分類準備數據集。
- # encode strings to integer
- y_class = LabelEncoder().fit_transform(y)
- n_class = len(unique(y_class))
然后,我們可以將輸入,原始輸出和編碼后的輸出變量拆分為訓練集和測試集。
- # split data into train and test sets
- X_train, X_test, y_train, y_test, y_train_class, y_test_class = train_test_split(X, y, y_class, test_size=0.33, random_state=1)
接下來,我們可以使用功能性API定義模型。該模型采用與獨立模型相同的輸入數量,并使用以相同方式配置的兩個隱藏層
- # input
- visible = Input(shape=(n_features,))
- hidden1 = Dense(20, activation='relu', kernel_initializer='he_normal')(visible)
- hidden2 = Dense(10, activation='relu', kernel_initializer='he_normal')(hidden1)
然后,我們可以定義兩個單獨的輸出層,它們連接到模型的第二個隱藏層。
第一個是具有單個節點和線性激活函數的回歸輸出層。
- # regression output
- out_reg = Dense(1, activation='linear')(hidden2)
第二個是分類輸出層,對于每個要預測的類都有一個節點,并使用softmax激活函數。
- # classification output
- out_clas = Dense(n_class, activation='softmax')(hidden2)
然后,我們可以使用一個輸入層和兩個輸出層定義模型。
- # define model
- model = Model(inputs=visible, outputs=[out_reg, out_clas])
給定兩個輸出層,我們可以使用兩個損失函數來編譯模型,第一個(回歸)輸出層的均方誤差損失和第二個(分類)輸出層的稀疏分類交叉熵。
- # compile the keras model
- model.compile(loss=['mse','sparse_categorical_crossentropy'], optimizer='adam')
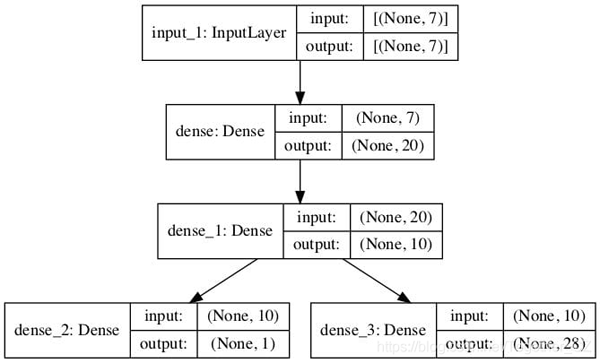
我們還可以創建模型圖以供參考。這需要安裝pydot和pygraphviz。如果存在問題,則可以注釋掉該行以及 plot_model()函數的import語句。
- # plot graph of model
- plot_model(model, to_file='model.png', show_shapes=True)
每次模型進行預測時,它將預測兩個值。同樣,訓練模型時,每個輸出每個樣本將需要一個目標變量。這樣,我們可以訓練模型,并仔細地向模型的每個輸出提供回歸目標和分類目標數據。
- # plot graph of model
- plot_model(model, to_file='model.png', show_shapes=True)
然后,擬合模型可以對保留測試集中的每個示例進行回歸和分類預測。
- # make predictions on test set
- yhat1, yhat2 = model.predict(X_test)
第一個數組可用于通過平均絕對誤差評估回歸預測。
- # calculate error for regression model
- error = mean_absolute_error(y_test, yhat1)
- print('MAE: %.3f'% error)
第二個數組可用于通過分類準確性評估分類預測。
- # evaluate accuracy for classification model
- yhat2 = argmax(yhat2, axis=-1).astype('int')
- acc = accuracy_score(y_test_class, yhat2)
- print('Accuracy: %.3f'% acc)
就是這樣。結合在一起,下面列出了訓練和評估用于鮑魚數據集上的組合器回歸和分類預測的多輸出模型的完整示例。
- # mlp for combined regression and classification predictions on the abalone dataset
- from numpy import unique
- from numpy import argmax
- from pandas import read_csv
- from sklearn.metrics import mean_absolute_error
- from sklearn.metrics import accuracy_score
- from sklearn.model_selection import train_test_split
- from sklearn.preprocessing importLabelEncoder
- from tensorflow.keras.models importModel
- from tensorflow.keras.layers importInput
- from tensorflow.keras.layers importDense
- from tensorflow.keras.utils import plot_model
- # load dataset
- url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/abalone.csv'
- dataframe = read_csv(url, header=None)
- dataset = dataframe.values
- # split into input (X) and output (y) variables
- X, y = dataset[:, 1:-1], dataset[:, -1]
- X, y = X.astype('float'), y.astype('float')
- n_features = X.shape[1]
- # encode strings to integer
- y_class = LabelEncoder().fit_transform(y)
- n_class = len(unique(y_class))
- # split data into train and test sets
- X_train, X_test, y_train, y_test, y_train_class, y_test_class = train_test_split(X, y, y_class, test_size=0.33, random_state=1)
- # input
- visible = Input(shape=(n_features,))
- hidden1 = Dense(20, activation='relu', kernel_initializer='he_normal')(visible)
- hidden2 = Dense(10, activation='relu', kernel_initializer='he_normal')(hidden1)
- # regression output
- out_reg = Dense(1, activation='linear')(hidden2)
- # classification output
- out_clas = Dense(n_class, activation='softmax')(hidden2)
- # define model
- model = Model(inputs=visible, outputs=[out_reg, out_clas])
- # compile the keras model
- model.compile(loss=['mse','sparse_categorical_crossentropy'], optimizer='adam')
- # plot graph of model
- plot_model(model, to_file='model.png', show_shapes=True)
- # fit the keras model on the dataset
- model.fit(X_train, [y_train,y_train_class], epochs=150, batch_size=32, verbose=2)
- # make predictions on test set
- yhat1, yhat2 = model.predict(X_test)
- # calculate error for regression model
- error = mean_absolute_error(y_test, yhat1)
- print('MAE: %.3f'% error)
- # evaluate accuracy for classification model
- yhat2 = argmax(yhat2, axis=-1).astype('int')
- acc = accuracy_score(y_test_class, yhat2)
- print('Accuracy: %.3f'% acc)
運行示例將準備數據集,擬合模型并報告模型誤差的估計值。
注意:由于算法或評估程序的隨機性,或者數值精度的差異,您的結果可能會有所不同。考慮運行該示例幾次并比較平均結果。
創建了多輸出模型圖,清楚地顯示了連接到模型第二個隱藏層的回歸(左)和分類(右)輸出層。
在這種情況下,我們可以看到該模型既實現了約1.495 的合理誤差,又實現了與之前相似的約25.6%的精度。
- Epoch145/150
- 88/88- 0s- loss: 6.5707- dense_2_loss: 4.5396- dense_3_loss: 2.0311
- Epoch146/150
- 88/88- 0s- loss: 6.5753- dense_2_loss: 4.5466- dense_3_loss: 2.0287
- Epoch147/150
- 88/88- 0s- loss: 6.5970- dense_2_loss: 4.5723- dense_3_loss: 2.0247
- Epoch148/150
- 88/88- 0s- loss: 6.5640- dense_2_loss: 4.5389- dense_3_loss: 2.0251
- Epoch149/150
- 88/88- 0s- loss: 6.6053- dense_2_loss: 4.5827- dense_3_loss: 2.0226
- Epoch150/150
- 88/88- 0s- loss: 6.5754- dense_2_loss: 4.5524- dense_3_loss: 2.0230
- MAE: 1.495
- Accuracy: 0.256