













華人女博士提出高效NAS算法:AutoML一次「訓練」適配億萬硬件

近日,由加州大學河濱分校主導、喬治梅森和圣母大學共同合作的團隊提出,可以利用延遲的單調性來從根本上促進硬件適配NAS —— 即不同設備上的神經架構延遲排名通常是相關的。
當強延遲單調性存在時,可以復用代理硬件上NAS所得到的架構給任意新目標硬件,而不會損失Pareto最優性。通過這種方法,結合現有的SOTA NAS技術,硬件適配NAS的代價可以降到常數O(1)。
目前,論文已經被國際性能建模和分析頂會ACM SIGMETRICS 2022接收。

論文地址:https://arxiv.org/abs/2111.01203
項目地址:https://ren-research.github.io/OneProxy/
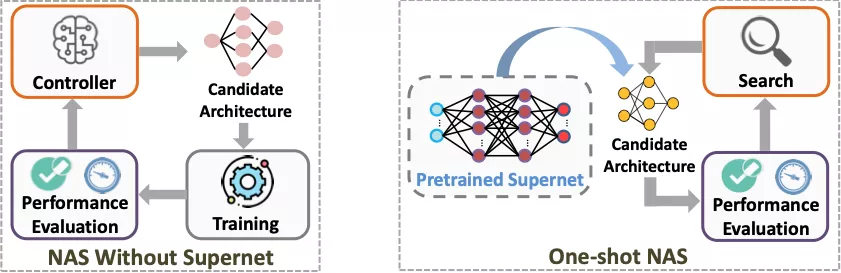
神經架構搜索(NAS)
神經網絡是層狀結構,每一層可能是卷積層、激活層或全連接層等。
NAS的過程就像搭積木,積木的每一層都有多種選擇,比如當前層是卷積層時,使用多大的卷積核就是一種選擇。在把各層的選擇組合起來之后,便構成了一個完整的神經架構。
通過NAS,一般會得到多個「最優」架構,比如高精度同時高延遲和低精度同時低延遲的架構。而NAS的最終目標就是找出這樣一系列在精度VS延遲的權衡中最優的架構(稱為Pareto最優架構)。相應地,硬件適配NAS就是對給定目標設備進行NAS,從而找到當前設備上的一系列Pareto最優架構。
由此可見,NAS就是一個「選擇-組合」的過程,所以過程中必定會得到非常多個可供選擇的架構。從中挑出Pareto最優架構的方法是對這些架構的延遲和精度進行排名而擇其優。
對此,本文將使用精度和推理延遲兩個指標來衡量一個神經架構的性能。
工作簡介
卷積神經網絡(CNN)已被部署在越來越多樣化的硬件設備和平臺上。而神經網絡架構極大地影響著最終的模型性能,比如推理精度和延遲。因此,在NAS的過程中綜合目標硬件的影響至關重要,即硬件適配的NAS。
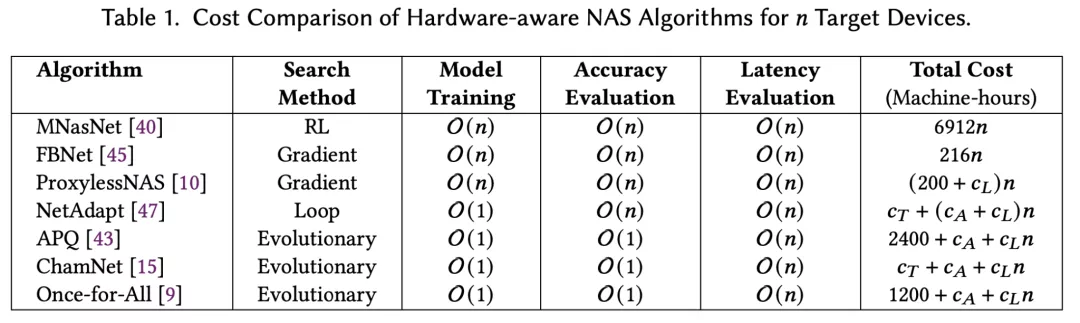
高效進行硬件適配NAS的關鍵是快速在目標設備上評估各個神經架構的延推理延遲。如果簡單地直接測量每個架構的延遲,會導致一次NAS就需要數周甚至數月。所以SOTA硬件適配的NAS主要依賴于為每個設備建立延遲查找表或預測器。
然而構建延遲預測器非常耗時以及需要大量的工程工作。例如,MIT的ProxylessNAS在移動設備上測量了5000個DNN的平均推理延遲,以此為基礎構建延遲查找表。
假設每次測量的理想耗時是20秒(根據TensorFlow官方指南),即使不間斷地測量,在一個設備上構建延遲預測器也需要27個多小時。類似地,Meta提出的ChamNet收集了35萬條延遲記錄,僅僅用于在一個設備上構建延遲預測器。
今年ICLR的spotlight工作HW-NAS-Bench也花了一個月在NAS-Bench-201和FBNet模型空間上搜集延遲數據,并為六個設備構建延遲預測器。在Microsoft的最新工作nn-meter中,單是收集一個邊緣設備上的延遲測量值就需要4.4天。
這些事實證明了SOTA的硬件適配NAS —— 為每個目標設備構建延遲預測器 —— 成本非常高昂。
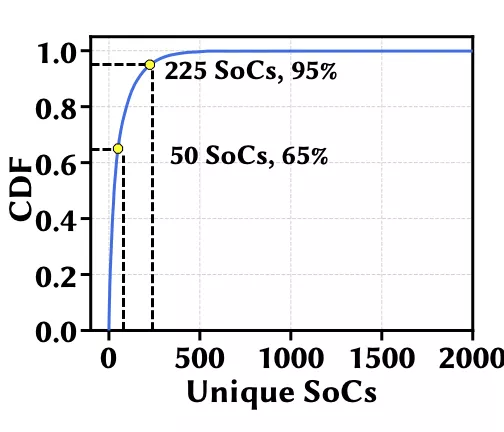
更復雜的是,CNN部署的目標設備極其多樣化,包括移動CPU、ASIC、邊緣設備、和GPU等。例如,光是移動設備,市面上就有兩千多個SoC,排名前30的SoC才勉強各有超過1% 的份額。所以,如何在極其多樣化的目標設備上有效地進行硬件適配NAS已成為一項挑戰。
在本項工作中,作者解決了如何在不同目標設備上降低硬件適配NAS的延遲評估成本。作者首先證明了神經架構的延遲單調性普遍存在,尤其是同一平臺的設備間。延遲單調性意味著不同架構的延遲排名順序在多個設備上相關。
在此基礎上,只需要選擇一個設備作為代理并為它構建延遲預測器 —— 而不是像SOTA那樣為每個單獨的目標設備構建延遲預測器 —— 就足夠了。
實驗結果表明,與專門針對每個目標設備進行優化的NAS相比,僅使用一個代理設備的方法幾乎不會損失Pareto最優性。本項工作被收錄于SIGMETRICS’22。
普遍存在的延遲單調性
作為本項工作的根基,作者首先研究了神經架構的延遲單調性,并證明它普遍存在于設備間,尤其是同一平臺的設備。本文使用Spearman等級相關系數(SRCC)來定量地衡量延遲的單調程度。SRCC的值介于-1和1之間,兩個設備上模型延遲的SRCC越大表明延遲的單調性越好。通常,SRCC的值大于0.9時被視為強單調性。
1. 同一平臺的設備間
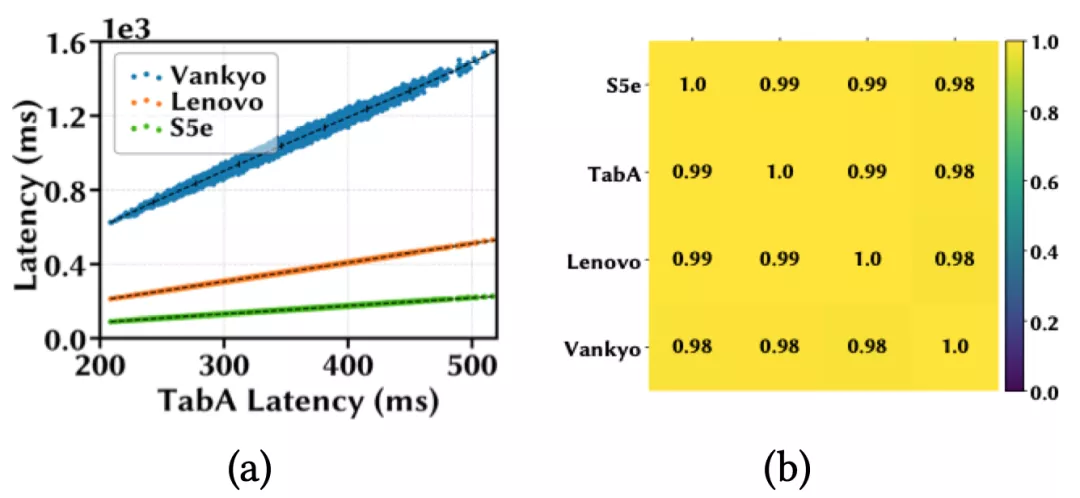
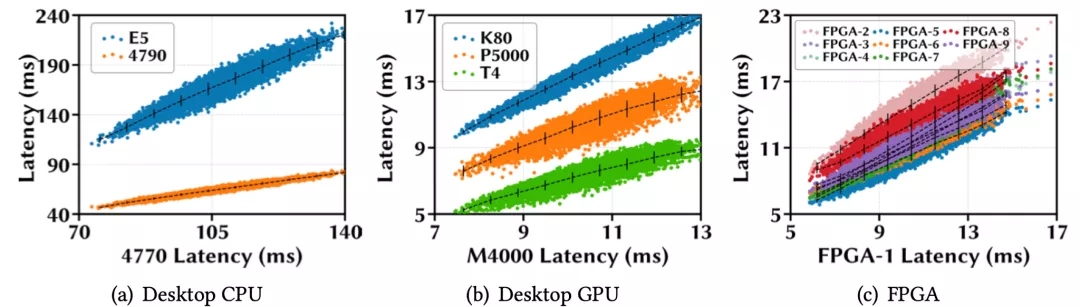
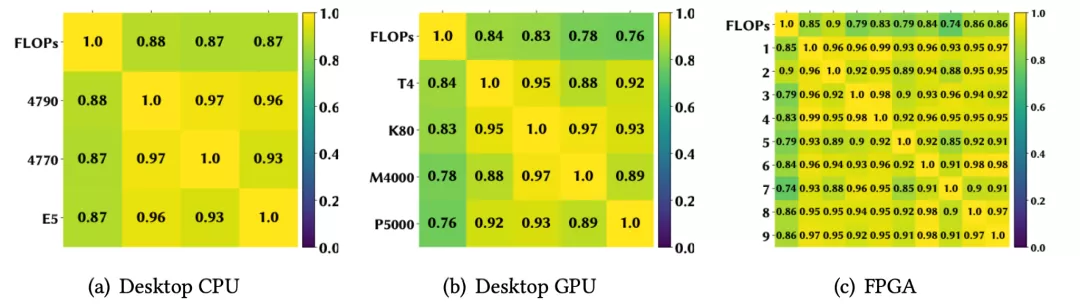
作者首先在四個移動設備上進行了延遲單調性實驗,分別是三星Galaxy S5e和TabA,聯想Moto Tab和Vankyo MatrixPad Z1;并從 MobileNet-V2搜索空間隨機sample了10k個模型。接下來在四個設備上分別部署這些模型并計算它們的平均推理延遲。
下圖(a)用散點表示這些模型在四個設備上的推理延遲;圖(b)用熱力圖來可視化設備之間模型延遲的相關系數,每個方格的顏色深淺和所標數值直觀地表示一對設備間的SRCC大小。
作者發現,當一個模型在TabA上運行得更快時,在其他設備上也更快,并且任意一對設備間的SRCC都大于 0.98,這表明這10k個模型在這些設備上有非常強的延遲單調性。
更多的實驗還證明,同樣的結論對于其他平臺的設備間也成立,例如CPU,GPU,和FPGA。
2. 跨平臺的設備間
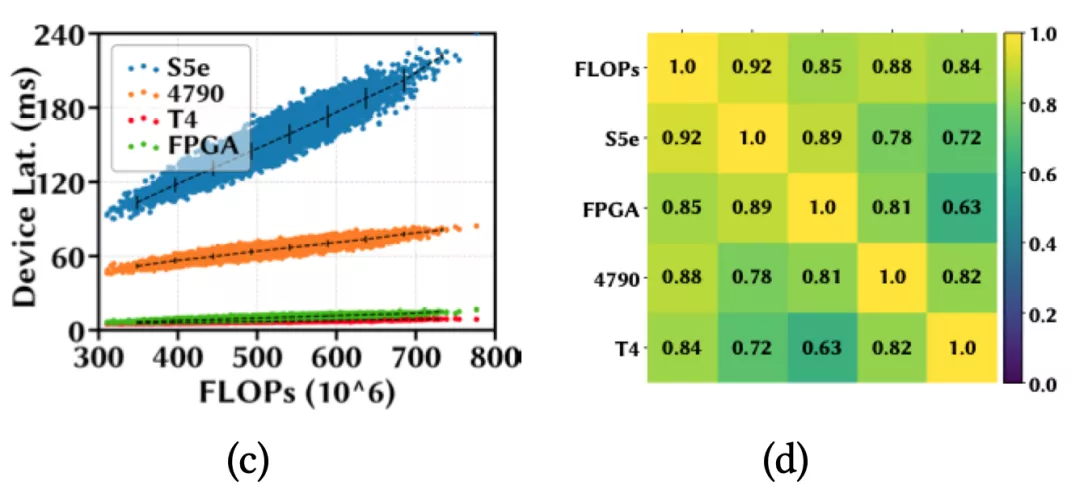
對于跨平臺的設備,由于硬件結構通常顯著不同,延遲排名的相關性自然而然會低于同平臺的設備間。作者在HW-NAS-Bench開源數據集上的實驗也證明了此結論(詳情見原文附錄)。
用一個代理設備進行硬件適配NAS
硬件適配NAS的目的是從數以億計的可選神經架構中找到適配當前硬件的一系列Pareto最優架構。其中,不同硬件只會影響架構的延遲,而不改變架構精度。
通過前一個章節可以知道不同硬件上架構的延遲排名可能有很強的相關性,既然代理硬件上延遲低精度高的架構可能在其他硬件上也延遲低精度高。那么能不能直接復用一個代理硬件上的Pareto最優架構給所有硬件呢?
作者的回答是:能,但是需要滿足一定的條件。
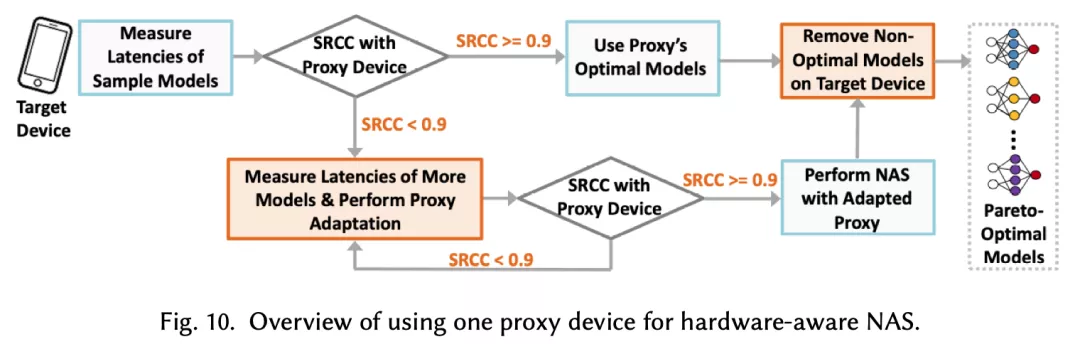
首先,用一個代理設備在目標設備上進行NAS并成功搜索出Pareto最優架構的充分條件是強延遲單調性。當代理設備和目標設備之間的SRCC達不到閾值時,代理設備上NAS搜索出的架構可能與目標的Pareto最優架構有些差距。
實際情況中,設備之間的低延遲單調性可能并不少見,尤其對于跨平臺的設備間。針對這種情況,作者提出了一種有效的遷移學習技術來使代理設備的延遲預測器適應到目標設備,從而提高適應后的「新代理」設備和目標設備之間的延時SRCC。
本文通過大量實驗證明,可以成功作為代理設備的延遲SRCC閾值在0.9左右。使用遷移學習技術來提高代理設備和目標設備間SRCC的效果如下,具體細節以及算法描述可以參考原文的對應章節。

實驗結果
作者在多個主流NAS搜索空間——MobileNet-V2、MobileNet-V3、NAS-Bench-201和FBNet上,對多個硬件設備(包括手機、GPU/CPU、ASIC等)進行了實驗,證明了利用延時單調性(結合遷移學習提高單調性的技術),使用一個代理設備來對不同目標設備進行硬件適配NAS的有效性。
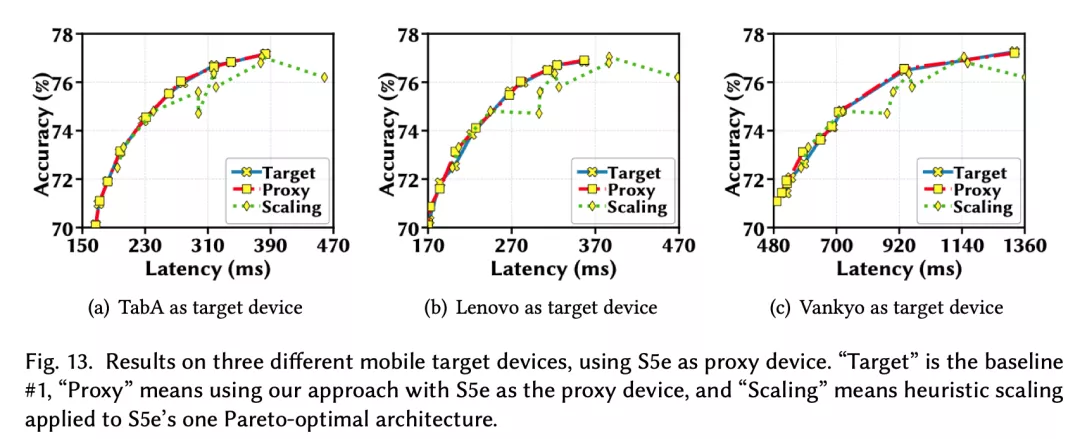
總結
快速評估在目標設備上的推理延遲是能夠在海量的神經構架空間中實現高效優化的關鍵步驟。目前普遍采用的為每個目標設備構建延遲預測器的方法無法滿足實際中目標設備日益增多所帶來的挑戰。
在加州大學河濱分校團隊所提出的全新方法中,基于延遲單調性,僅僅一個代理設備就足以進行硬件適配的神經構架搜索,并且不失最優性。這省去了大量構建延遲預測器的巨大代價,使得今后針對不同平臺和設備快速優化神經構架成為了可能。
作者簡介
論文第一作者盧冰倩目前是加州大學河濱分校的博士生研究助理,本科畢業于浙江大學。博士期間一直從事AutoML和NAS的研究工作,包括自動化機器學習模型選擇、可擴展的硬件適配神經網絡優化,以及硬件適配NAS等。
其導師任紹磊博士,清華大學電子系本科,加州大學洛杉磯分校博士,現任加州大學河濱分校副教授。任教授的研究興趣包括系統與網絡優化(數據中心,云計算,邊緣計算等),近年來專注于機器學習及其應用(包括強化學習,AutoML,TinyML等)。

















