近日,一篇匿名提交給自然語言處理頂會 ACL 的論文《 N-grammer: Augmenting Transformers with latent n-grams 》中,研究者受到統計語言建模的啟發,通過從文本序列的離散潛在表示構建 n-gram 來增強模型,進而對 Transformer 架構進行了一個簡單而有效的修改,稱為 N-grammer。
具體地,N-grammer 層通過在訓練期間將潛在 n-gram 表示合并到模型中來提高語言模型的效率。由于 N-grammer 層僅在訓練和推理期間涉及稀疏操作,研究者發現具有潛在 N-grammer 層的 Transformer 模型可以匹配更大的 Transformer,同時推理速度明顯更快。在 C4 數據集上對語言建模的 N-grammer 進行評估表明,本文提出的方法優于 Transformer 和 Primer 等基準。

論文地址:https://openreview.net/pdf?id=GxjCYmQAody
N-grammer 層
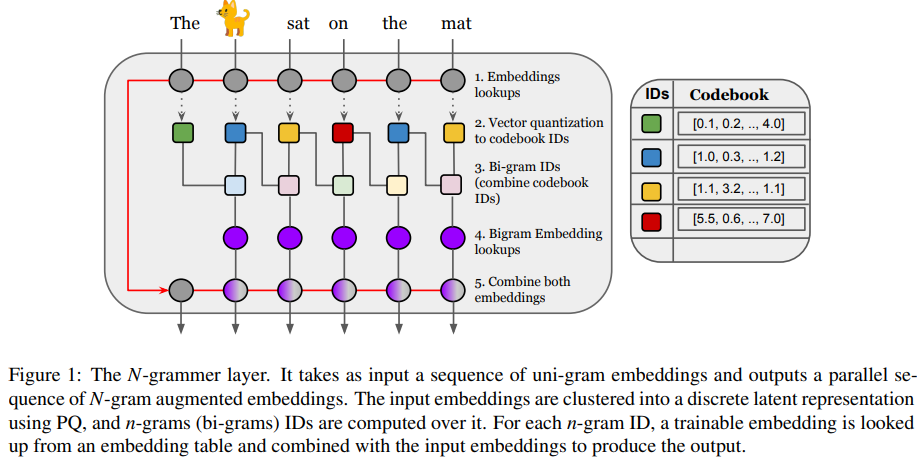
在網絡高層次上,該研究引入了一個簡單的層,該層基于潛在 n-gram 用更多的內存來增強 Transformer 架構。一般來說,N-grammer 層對于任意 N-gram 來說已經足夠了,該研究僅限于使用 bi-gram,以后將會研究高階 n-gram。這個簡單的層由以下幾個核心操作組成:
- 給定文本的 uni-gram 嵌入序列,通過 PQ (Product Quantization)推導出離散潛在表示序列;
- 推導潛在序列 bi-gram 表示;
- 通過哈希到 bi-gram 詞匯表中查找可訓練的 bi-gram 嵌入;
- 將 bi-gram 嵌入與輸入 uni-gram 嵌入相結合。
此外,當提到一組離散項時,該研究使用符號 [m] 表示集合{0,1,···,m−1}。
序列的離散潛在表示
第一步,N-grammer 層從給定的輸入嵌入序列學習 Codebook,獲得具有乘積量化(Product Quantization,PQ)(Jegou 等人,2011 年)的離散潛在表示的并行序列。輸入嵌入是一個 uni-gram 嵌入序列 x ϵ R^( l×h×d ),其中 l 是序列長度,h 是頭數量,d 是每個頭嵌入維度。該研究在 R^ k×h×d 中學習了一個 Codebook c,通過相同的步驟,該研究選取距離輸入嵌入最小的 code book ID,形成序列 x 的離散潛在表示 z ϵ[k]^l×h 的并行序列:
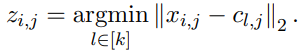
離散潛在表示 Bi-gram ID
第二步是將離散潛在表示 z 轉換為 bi-gram ID b ϵ [k^2 ]^( l×h )。它們通過組合來自前一個位置的 uni-gram 潛在 ID z,然后在當前位置形成潛在 bi-gram ID:
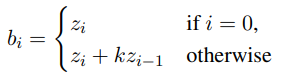
其中 k 是 codebook 大小,這直接將離散潛在序列從詞匯空間[k] 映射到潛在 bi-gram 詞匯空間 [k^2 ] 。
構建 bi-gram 表示
第三步是構建序列 bi-gram 潛在表示 b。考慮所有的 k^2 bi-gram,并通過對每個這樣的 bi-gram 嵌入來增強模型。在實踐中,對于 uni-gram 詞匯為 32,000 的機器翻譯模型壓縮,在不犧牲質量的情況下,需要將 187 個 token 聚類為 k = 212 個 cluster。在這種情況下,需要考慮所有的 bi-gram,涉及構建一個包含 1600 萬行的嵌入表。由于所構建的表仍然很大,該研究通過對每個頭使用單獨的哈希函數,將潛在 bi-gram ID 映射到大小為 v 的較小的 bi-gram 詞匯表。
更準確地講,該研究有一個潛在 bi-gram 嵌入表 B ϵ R^v×h×d_b,其中 v 為 bi- gram 詞匯,d_b 為 bi-gram 嵌入維度。然后將文本序列 bi-gram 嵌入構建為:
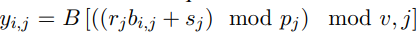
與嵌入進行結合
最后一步是將 uni-gram 嵌入 x ϵ R^(l×h×d)與潛在 bi-gram 嵌入 y∈R^(l×h×db)相結合,形成文本序列新表示。bi-gram 嵌入和 uni-gram 嵌入都是獨立的層歸一化(LN),然后沿著嵌入維度連接兩者以產生 w = [LN(x), LN(y)] ϵ R^l×h×(d+db) ,并將其作為輸入傳遞給 Transformer 網絡的其余部分。
實驗結果
該研究在 C4 數據集上將 N-grammer 模型與 Transformer 架構(Vaswani 等人,2017 年)以及最近提出的 Primer 架構(So 等人,2021 年)進行了比較。其中,該研究使用 Adam 優化器,所有模型的學習率為 10^-3,而對于 n-gram 嵌入表,學習率為 10^-2。
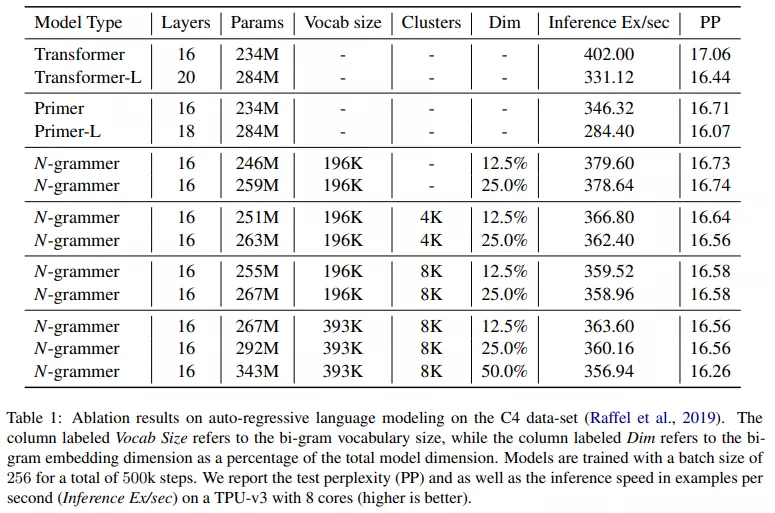
下表 1 比較了 N-grammer、Primer 和 Transformer 模型,其中基線 Transformer 模型有 16 層和 8 個頭,模型維度為 1024。研究者在 TPU v3 上以 256 的批大小和 1024 的序列長度訓練所有模型。研究者對 N-grammer 模型進行了消融研究,bi-gram 嵌入維度大小從 128 到 512 不等。由于添加 n-gram 嵌入增加了可訓練參數的數量,該研究還在表 1 中訓練了兩個大基線(Transformer-L 和 Primer-L),它們的參數順序與 N-grammer 模型相同。然而,與較大的 Transformer 模型不同,N-grammer 的訓練和推理成本與嵌入層中的參數數量不成比例,因為它們依賴于稀疏操作。
該研究還測試了一個簡單版本的 N-grammer,研究者直接從 uni-gram 詞匯表(3.3 節中的)而不是從潛在表示中計算 n-gram(3.1 節的)。由表 1 可知,它對應于在 clusters 列中沒有條目的 N- grammer。