用于形狀精確三維感知圖像合成的著色引導生成隱式模型
本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。
生成輻射場的發展推動了3D感知圖像合成的發展。由于觀察到3D對象從多個視點看起來十分逼真,這些方法引入了多視圖約束作為正則化,以從2D圖像學習有效的3D輻射場。盡管取得了進展,但由于形狀-顏色的模糊性,它們往往無法捕獲準確的3D形狀,從而限制了在下游任務中的適用性。在這項研究工作中,來自馬普所和港中文大學的學者通過提出一種新的著色引導生成隱式模型ShadeGAN來解決這種模糊性,它學習了一種改進的形狀表示。

論文地址:https://arxiv.org/pdf/2110.15678.pdf代碼地址:https://github.com/xingangpan/shadegan關鍵在于,精確的3D形狀還應在不同的照明條件下產生逼真的渲染效果。多重照明約束通過顯式建模照明和在各種照明條件下執行著色實現。梯度是通過將合成圖像饋送到鑒別器得到的。為了補償計算曲面法線的額外計算負擔,研究團隊進一步設計了通過曲面跟蹤的高效體繪制策略,將訓練和推理時間分別減少24%和48%。在多個數據集上實驗表明,在捕獲精確的底層三維形狀的同時,ShadeGAN做到了實現具備真實感的三維感知圖像合成。他們還展示了該方法在三維形狀重建方面相對于現有方法的改進性能,在圖像重照明方面亦有適用性。
1.介紹
高級深度生成模型,例如StyleGAN和BigGAN,在自然圖像合成方面取得了巨大成功。但這些基于2D表示的模型無法以3D一致性方式合成實例新視圖。它們也無法表示明確的三維物體形狀。為了克服這些限制,研究人員提出了新的深度生成模型,將3D場景表示為神經輻射場。3D感知生成模型可以顯式控制視點,同時在圖像合成過程中保持3D一致性。它們展示了在無監督情況下從一組無約束的2D圖像中學習3D形狀的巨大潛力。如果可以訓練出學習精確3D物體形狀的3D感知生成模型,各種下游應用就可以的到拓展,如3D形狀重建和圖像重照明。現有3D感知圖像合成嘗試傾向于學習不準確且有噪聲的粗略3D形狀,如下圖所示。研究發現,這種不準確是由于方法所采用的訓練策略不可避免地存在模糊性。特別是一種正則化,稱之為“多視圖約束”,用于強制三維表示,使其從不同的視點看起來更逼真。這種約束通常首先將生成器的輸出(例如,輻射場)投影到隨機采樣視點,然后將它作為假圖像提供給鑒別器進行訓練。雖然這種約束使模型能夠以3D感知的方式合成圖像,但會受到形狀-顏色模糊關聯的影響,即便有微小的形狀變化也能生成類似的RGB圖像,這些圖像在鑒別器看來同樣可信,因為許多物體顏色是局部平滑的。因此,不準確的形狀仍然隱藏在這個約束下。
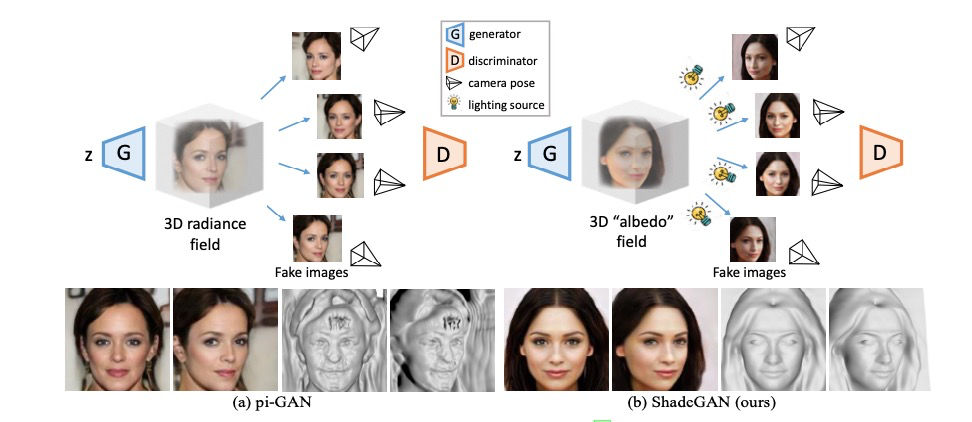
在本文中,研究團隊提出了一種新的著色引導生成隱式模型(ShadeGAN)來解決上述歧義。特別是,ShadeGAN通過顯式建模著色(即照明和形狀的交互)學習更精確的3D形狀。一個精確的3D形狀不僅應該從不同的角度看起來很逼真,在不同的照明條件下也應該十分逼真,即滿足“多重照明約束”。這一想法與光度立體有著相似的直覺,它表明可以從不同照明條件下拍攝的圖像中恢復精確表面法線。請注意,多重照明約束是可行的,因為用于訓練的真實圖像通常是在各種照明條件下拍攝的。為了滿足此約束,ShadeGAN采用可重新照明的顏色場作為中間表示,近似反照率,但不一定滿足視點獨立性。渲染期間,顏色場在隨機采樣的照明條件下著色。由于通過這種著色處理的圖像外觀強烈依賴于曲面法線,因此與早期的著色不可知生成模型相比,不準確的3D形狀表示將更清晰地顯示出來。通過滿足多重照明約束,可以鼓勵ShadeGAN推斷更精確的3D形狀,如上圖中右下所示。上述著色處理需要通過反向傳播來通過生成器計算法線方向,并且在3D體繪制中,對于單個像素的計算需要重復幾十次,從而引入額外的計算開銷。
現有高效體繪制技術主要針對靜態場景,面對動態特性無法直接應用于生成模型。為了提高ShadeGAN的渲染速度,研究團隊建立了一個有效的曲面跟蹤網絡,以評估基于潛在代碼的渲染對象曲面。這使他們能夠通過僅查詢預測曲面附近的點來節省渲染計算,從而在不影響渲染圖像質量的情況下減少24%和48%的訓練和推理時間。通過多個數據集上進行綜合實驗驗證ShadeGAN的有效性。結果表明,與之前的生成方法相比,本文提出的方法能夠合成照片級真實感圖像,同時捕獲更精確的底層三維形狀。學習到的三維形狀分布能夠實現各種下游任務,比如三維形狀重建,其中ShadeGAN明顯優于BFM數據集上的其他基線。對著色過程進行建模,可以顯式控制照明條件,實現圖像重照明效果。
ShadeGAN可以總結如下:1)使用滿足多重照明約束的著色引導生成模型,從而解決現有三維感知圖像合成中形狀-顏色模糊問題。ShadeGAN能夠學習更精確的3D形狀,從而更好地進行圖像合成。2) 通過曲面跟蹤設計了一種高效的繪制技術,這大大節省了基于體繪制生成模型的訓練和推理時間。3)ShadeGAN學會了將陰影和顏色分離,更接近反照率,在圖像合成中達到了自然重新照明效果
2.ShadeGAN 神經體繪制
從神經輻射場(NeRF)的開創性工作開始,神經體繪制在表示3D場景和合成新視圖方面得到了廣泛的應用。通過基于坐標神經網絡與體繪制相結合,NeRF以3D一致性完成高保真視圖合成。目前已經提出了一些嘗試擴展或改進NeRF。比如進一步模擬照明,然后學習在給定對齊多視圖、多照明圖像情況下,將反射與著色分離。此外,許多研究從空間稀疏性、建筑設計或高效渲染角度加速了靜態場景的渲染。這些照明和加速技術應用于基于體繪制的生成模型并非易事,因為它們通常從為定位、未配對的圖像中學習,表示相對于輸入潛在編碼變化的動態場景。研究團隊首次嘗試在基于體繪制的生成模型中對照明進行建模,作為精確三維形狀學習的正則化。并進一步為方法設計了高校的渲染技術,它具有相似的見解,但不依賴于通過真實深度進行訓練,也不限于視點小范圍。
生成三維感知圖像合成
生成對抗網絡(GANs)可以生成高分辨率的真實照片圖像,但對攝像機視點的明確控制卻很匱乏。為了能夠以3D感知的方式合成圖像,許多最新方法研究了如何將3D表示合并到GANs中。有些研究直接從3D數據中學習,但在本文中,研究團隊關注的是只能訪問無約束2D圖像方法,因為這是更實際的設置。研究團隊多次嘗試采用3D體素特征和學習神經渲染,雖然產生了逼真的3D感知合成,但3D體素不可解釋,無法轉換為3D形狀。NeRF可以成功促使在GANs中使用輻射場作為中間3D表示,是有一些令人印象深刻、具有多視圖一致性的3D感知圖像合成,但這些方法提取的3D形狀通常不精確且有噪聲。在本文中,研究團隊的主要目標是通過在渲染過程中顯式地建模照明來解決不準確形狀。這項創新有助于實現更好的3D感知圖像合成,將具有更廣泛的應用。
從2D圖像進行無監督的3D形狀學習
ShadeGAN涉及無監督方法,即從無約束單目視圖2D圖像中學習3D物體形狀。雖然一些方法使用外部3D形狀模板或2D關鍵點作為弱監督,但本文考慮了更有難度的設置——只有2D圖像是可用的。大多數方法采用“綜合分析”范式,就是設計了照片幾何自動編碼器,以在重建損失情況下推斷每個圖像的三維形狀和視點。這是可以學習一些對象類的3D形狀,只是通常依賴正則化來防止瑣碎的解決方案,如常用的對象形狀對稱假設。這種假設傾向于產生對稱結果,可能忽略對象的不對稱方面。最近,GAN2Shape表明,可以為2D GAN生成的圖像恢復3D形狀。但這種方法需要低效的實例特定訓練,并恢復深度貼圖,而不是完整的三維表示。本文提出的三維感知生成模型也可以作為無監督三維形狀學習的有力方法。與上述基于自動編碼器的方法相比,基于GAN的方法避免了推斷每個圖像的視點需求,而且不依賴于強正則性。通過實驗更加證明了與最新、最先進的方法Unsp3d和GAN2Shape相比,ShadeGAN具有更高的性能。
3.ShadeGAN方法論
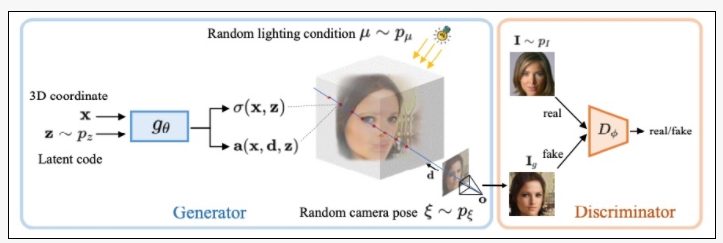
ShadeGAN通過無約束和未標記的 2D 圖像學習考慮3D 感知圖像合成問題。在生成隱式模型中建模著色,也就是照明和形狀的交互,實現對更精確三維對象形狀的無監督學習。接下來會先提供關于神經輻射場(NeRF)的初步介紹,然后詳細介紹著色引導生成隱式模型。
3.1 神經輻射場的初步研究
作為一種深度隱式模型,NeRF使用MLP網絡將3D場景表示為輻射場。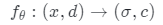 取三維坐標
取三維坐標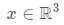 和觀察方向
和觀察方向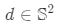 作為輸入,并輸出體積密
作為輸入,并輸出體積密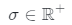 和顏色
和顏色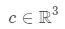 。為了在給定的相機姿勢下渲染圖像,通過沿其對應的相機光線
。為了在給定的相機姿勢下渲染圖像,通過沿其對應的相機光線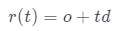 的體繪制獲得圖像的每個像素顏色C,如下所示:
的體繪制獲得圖像的每個像素顏色C,如下所示:
 實踐中,這種體繪制是使用分層和分層采樣的離散形式實現的。由于該渲染過程是可微分的,因此通過靜態場景的姿勢圖像直接優化NeRF。經過訓練后,NeRF允許在新的相機姿勢下渲染圖像,實現高質量新穎視圖合成。
實踐中,這種體繪制是使用分層和分層采樣的離散形式實現的。由于該渲染過程是可微分的,因此通過靜態場景的姿勢圖像直接優化NeRF。經過訓練后,NeRF允許在新的相機姿勢下渲染圖像,實現高質量新穎視圖合成。
3.2著色引導生成隱式模型
開發生成隱式模型是十分有趣的,它可以為3D感知圖像合成顯式著色過程建模。研究團隊對NeRF中的MLP網絡進行了兩個擴展。首先,與大多數深度生成模型類似,它進一步取決于從先驗分布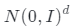 中采樣的潛在編碼z。其次,它不直接輸出顏色c,而是輸出可重新點亮的前余弦顏色項
中采樣的潛在編碼z。其次,它不直接輸出顏色c,而是輸出可重新點亮的前余弦顏色項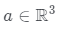 。
。
它在概念上類似于反照率,在給定的光照條件下,它可以被遮蔽。雖然反照率是獨立于視點的,但在這項工作中,為了解釋數據集偏差,并沒有嚴格地對一個數據集實現這種獨立性。因此,本文的生成器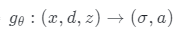 取坐標x、觀察方向d和潛在方向編碼z作為輸入,并輸出體積密度σ和前余弦顏色a。注意,這里σ獨立于d,而a對d的依賴是可選的。為了獲得相機光線
取坐標x、觀察方向d和潛在方向編碼z作為輸入,并輸出體積密度σ和前余弦顏色a。注意,這里σ獨立于d,而a對d的依賴是可選的。為了獲得相機光線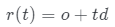 的顏色C,近界和遠界
的顏色C,近界和遠界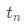 和
和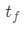 ,研究團隊通過以下方式計算最終的前余弦顏色A:
,研究團隊通過以下方式計算最終的前余弦顏色A:
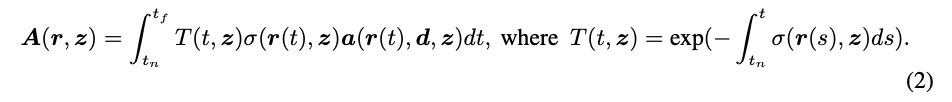 研究團隊還使用以下公式計算法向n:
研究團隊還使用以下公式計算法向n: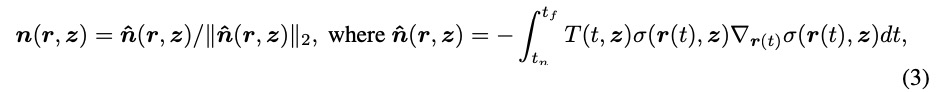
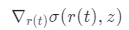 是體積密度σ相對于其輸入坐標的導數,它自然捕捉局部法線方向,并可通過反向傳播計算。然后通過Lambertian著色獲得最終顏色C,如下所示:
是體積密度σ相對于其輸入坐標的導數,它自然捕捉局部法線方向,并可通過反向傳播計算。然后通過Lambertian著色獲得最終顏色C,如下所示:
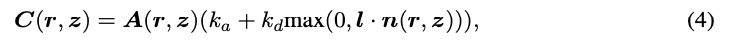
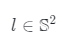 是照明方向,
是照明方向,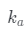 和
和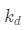 是環境系數和漫反射系數。
是環境系數和漫反射系數。
攝像機和照明采樣等式(2-4)描述了給定相機光線r(t)和照明條件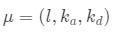 渲染像素顏色的過程。生成完整圖像
渲染像素顏色的過程。生成完整圖像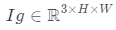 要求除潛在編碼z外,還需對攝像姿勢
要求除潛在編碼z外,還需對攝像姿勢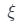 和照明條件μ進行采樣,即
和照明條件μ進行采樣,即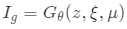 。
。
在設置中,攝像姿態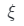 可以用俯仰角和偏航角來描述,并從先前的高斯分布或均勻分布
可以用俯仰角和偏航角來描述,并從先前的高斯分布或均勻分布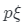 中采樣,正如在以前的工作中所做的一樣。在訓練過程中隨機采樣相機姿勢將激發學習的3D場景從不同角度看起來逼真。雖然這種多視圖約束有利于學習有效的三維表示,但它通常不足以推斷準確的三維對象形狀。
中采樣,正如在以前的工作中所做的一樣。在訓練過程中隨機采樣相機姿勢將激發學習的3D場景從不同角度看起來逼真。雖然這種多視圖約束有利于學習有效的三維表示,但它通常不足以推斷準確的三維對象形狀。
因此,在本文中,研究團隊還通過從先驗分布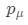 中隨機采樣照明條件μ來進一步引入多重照明約束。實際上,可以使用現有方法從數據集估算
中隨機采樣照明條件μ來進一步引入多重照明約束。實際上,可以使用現有方法從數據集估算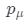 。在實驗中,一個簡單且手動調整的先驗分布也可以產生合理結果。由于等式(4)中的漫反射項
。在實驗中,一個簡單且手動調整的先驗分布也可以產生合理結果。由于等式(4)中的漫反射項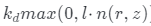 導致著色過程對法線方向敏感,該多重照明約束將使模型正則化,學習產生自然著色的更精確3D形狀。
導致著色過程對法線方向敏感,該多重照明約束將使模型正則化,學習產生自然著色的更精確3D形狀。
訓練生成模型遵循GANs范例,生成器與參數為φ的鑒別器D一起以對抗的方式進行訓練。在訓練期間,生成器通過相應的先驗分布pz、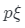 和
和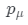 中采樣潛在編碼z、相機姿勢
中采樣潛在編碼z、相機姿勢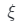 和照明條件μ來生成假圖像
和照明條件μ來生成假圖像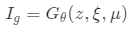 讓l表示從數據分布pI中采樣的真實圖像。用
讓l表示從數據分布pI中采樣的真實圖像。用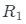 正則化的非飽和GAN損耗來訓練ShadeGAN模型:
正則化的非飽和GAN損耗來訓練ShadeGAN模型:
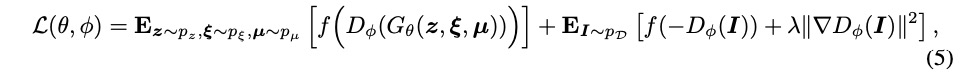 公式中
公式中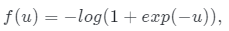 λ 控制正則化強度。
λ 控制正則化強度。
探討在等式(2-4)中,研究團隊通過體繪制獲得A和n之后執行著色。另一種方法是在每個局部空間點執行著色,其中: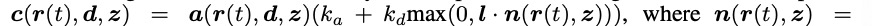
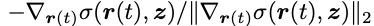 是局部正常。然后可以使用c(r(t), z) 執行體積排序,從而獲得最終的像素顏色。在實踐中,研究團隊觀察到該公式獲得了次優結果。直觀原因是,在此公式中,法線方向在每個局部點處歸一化,忽略了
是局部正常。然后可以使用c(r(t), z) 執行體積排序,從而獲得最終的像素顏色。在實踐中,研究團隊觀察到該公式獲得了次優結果。直觀原因是,在此公式中,法線方向在每個局部點處歸一化,忽略了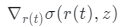 在物體表面附近趨于較大。
在物體表面附近趨于較大。
本文使用的Lambertian著色近似于真實照明場景。雖然作為改進學習的三維形狀的良好正則化,但它可能會在生成圖像的分布和真實圖像的分布之間引入額外的間隙。為了補償這種風險,可以選擇將預測的a調節到光照條件,即a = a(r(t), d, μ, z)。在照明條件偏離實際數據分布的情況下,生成器可以學習調整a值并減小上述間隙。
3.3通過曲面跟蹤實現高效體繪制
與NeRF類似,研究團隊使用離散積分實現體繪制,這通常需要沿攝影機光線采樣幾十個點,如圖所示。在本文中,還需要在等式(3)中對生成器執行反向傳播,以獲得每個點的法線方向,這會大大增加計算成本。為了實現更高效的體繪制,一個自然的想法是利用空間稀疏性。通常,體繪制中的權重T (t, z)σ(r(t), z)在訓練過程中會集中在物體表面位置上。如果在渲染之前知道粗糙曲面的位置,就可以在曲面附近采樣點以節省計算。對于靜態場景,將這種空間稀疏性存儲在稀疏體素網格中,但這種技術不能直接應用于我們的生成模型,因為3D場景相對于輸入的潛在編碼不斷變化。
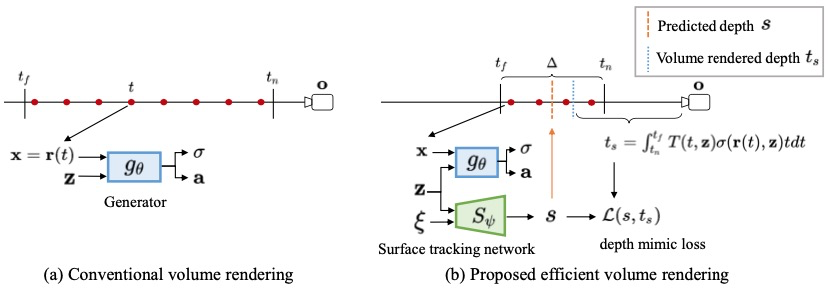
為了在生成隱式模型中實現更高效的體繪制,研究團隊進一步提出了一種曲面跟蹤網絡S,該網絡學習模仿以潛在編碼為條件的曲面位置。特別是,體渲染自然允許通過以下方式對對象曲面進行深度估計:
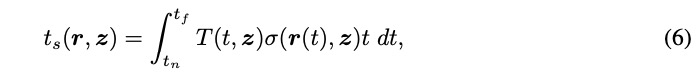
T (t, z)的定義方式與(2)中的方式相同。因此,給定相機姿態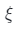 和潛在編碼z,可以渲染全深度貼圖
和潛在編碼z,可以渲染全深度貼圖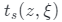 。如上圖(b)所示,使用表面跟蹤網絡
。如上圖(b)所示,使用表面跟蹤網絡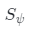 模擬
模擬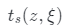 ,這是一個以z,
,這是一個以z, 為輸入并輸出深度圖的輕量級卷積神經網絡。深度模擬損失為:
為輸入并輸出深度圖的輕量級卷積神經網絡。深度模擬損失為:
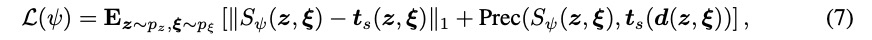
其中,Prec是促使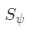 更好地捕捉表面邊緣的感知損失。在訓練過程中,
更好地捕捉表面邊緣的感知損失。在訓練過程中,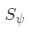 與發生器和鑒別器一起進行優化。每次在采樣一個潛在編碼z和一個相機姿勢
與發生器和鑒別器一起進行優化。每次在采樣一個潛在編碼z和一個相機姿勢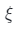 之后,可以得到深度貼圖的初始猜測
之后,可以得到深度貼圖的初始猜測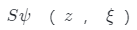 。
。
然后,對于具有預測深度s像素,可以在等式(2,3,6)中執行體繪制,且近邊界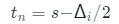 和遠界
和遠界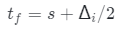 ,
,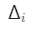 是體積渲染的間隔,該間隔隨著訓練迭代i的增長而減小。
是體積渲染的間隔,該間隔隨著訓練迭代i的增長而減小。
具體來說,我們從一個大的間隔開始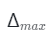 并減小到
并減小到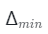 。像
。像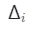 減少時,用于渲染m的點數也相應減少。與生成器相比,高效的曲面跟蹤網絡的計算成本是微乎其微的,因為前者只需要一次前向過程來渲染圖像,而后者將被查詢H × W × m 次。因此,m的減少將顯著加快ShadeGAN的訓練和推理速度。
減少時,用于渲染m的點數也相應減少。與生成器相比,高效的曲面跟蹤網絡的計算成本是微乎其微的,因為前者只需要一次前向過程來渲染圖像,而后者將被查詢H × W × m 次。因此,m的減少將顯著加快ShadeGAN的訓練和推理速度。
4.實驗
實驗表明,ShadeGAN學習的3D形狀比以前的方法精確得多,同時允許對照明條件進行顯式控制。使用的數據集包括CelebA、BFM和CAT,它們都只包含無約束的2D RGB圖像。在模型結構方面,我們采用了基于SIREN的MLP作為生成器,卷積神經網絡作為鑒別器。對于光照條件的先驗分布,使用Unsup3d估計真實數據的光照條件,然后擬合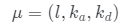 的多元高斯分布作為先驗。消融研究中還包括手工制作的先驗分布。除非另有說明,否則在所有實驗中,讓前余弦顏色a取決于照明條件μ以及觀察方向d。
的多元高斯分布作為先驗。消融研究中還包括手工制作的先驗分布。除非另有說明,否則在所有實驗中,讓前余弦顏色a取決于照明條件μ以及觀察方向d。
與基線進行比較
將ShadeGAN與兩種最先進的生成隱式模型(GRAF和pi-GAN)進行比較。具體地,圖4包括合成圖像以及它們對應的3D網格,其通過在體積密度σ上執行 marching cubes而獲得。雖然GRAF和pi-GAN可以合成具有可控姿勢的圖像,但它們學習到的3D形狀不準確且有噪聲。相比之下,本文的方法不僅合成真實感的3D一致圖像,而且還學習更精確的3D形狀和曲面法線,這表明所提出的多重照明約束作為正則化的有效性。圖5中包含了更多的合成圖像及其相應的形狀。除了更精確的3D形狀外,ShadeGAN還可以從本質上了解反照率和漫反射著色組件。如圖所示,盡管并不完美,ShadeGAN已成功以令人滿意的質量分離陰影和反照率,因為這種分離是多照明約束的自然解決方案。

在BFM數據集上對學習的3D形狀的質量進行定量評估。具體來說,使用每個生成隱式模型生成50k圖像及其相應的深度貼圖。來各個模型的圖像深度對被用作訓練數據,來訓練額外的卷積神經網絡(CNN),這個網絡學習預測輸入圖像的深度圖。然后,在BFM測試集上測試每個經過訓練的CNN,并將其預測與真實深度圖進行比較,作為對所學3D形狀質量的測量。本文報告了尺度不變深度誤差(SIDE)和平均角度偏差(MAD)度量。其中ShadeGAN的表現明顯優于GRAF和pi GAN。ShadeGAN還優于其他先進的無監督3D形狀學習方法,包括unsupervised和GAN2Shape,在無監督3D形狀學習都有著巨大潛力。不同模型合成的圖像的FID分數上,其中ShadeGAN的FID分數略差于BFM和CelebA中的pi GAN。直觀地說,這是由近似著色(即朗伯著色)和真實照明之間的差距造成的,可以通過采用更真實的著色模型和改進之前的照明來避免。

消融研究
研究團隊進一步研究了ShadeGAN中幾種設計選擇的影響。首先,執行局部點特定的著色。如圖所示,局部著色策略的結果明顯比原始策略差,這表明考慮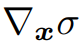 是有益的。
是有益的。

為了驗證所提出的高效體繪制技術的有效性,研究團隊將其對圖像質量和訓練/推理時間的影響包含在選項中。據觀察,高效體繪制對性能影響不大,但ShadeGAN的訓練和推理時間分別顯著減少了24%和48%。此外,在下圖中可視化了曲面跟蹤網絡預測的深度圖和通過體繪制獲得的深度圖。結果表明,在不同的身份和相機姿態下,曲面跟蹤網絡可以一致地預測非常接近真實曲面位置的深度值,因此可以在不犧牲圖像質量的情況下采樣預測曲面附近的點進行渲染。

光照感知圖像合成
由于ShadeGAN對著色過程進行建模,因此在設計上允許對照明條件進行顯式控制。下圖提供了這樣的照明感知圖像合成結果,其中ShadeGAN在不同的照明方向下生成有希望的圖像。在預測的a以照明條件μ為條件的情況下,a會略微改變w.r.t.照明條件,如在陰影過暗的區域,a會更亮,最終圖像更自然。我們還可以在等式4(即Blinn Phong著色,其中h是視點和照明方向之間角度的平分線)中選擇性地添加鏡面反射項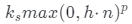 ,以創建鏡面反射高光效果。
,以創建鏡面反射高光效果。

GAN反演
ShadeGAN還可以通過執行GAN反演來重建給定的目標圖像。如下圖所示,這種反演允許我們獲得圖像的幾個因素,包括3D形狀、表面法線、近似反照率和陰影。此外,我們還可以通過更改視點和照明條件來進一步執行視圖合成和重新照明。

討論
由于使用的朗伯陰影近似于真實照明,因此ShadeGAN學習的反照率并沒有完全分離。本文的方法不考慮對象的空間變化的材料特性。在未來,研究團隊打算結合更復雜的著色模型,以更好地了解分離的生成反射場。
5.結論
本文提出的ShadeGAN是一種新的生成隱式模型,用于形狀精確的3D感知圖像合成。并證實在ShadeGAN中通過顯式光照建模實現的多重光照約束顯著有助于從2D圖像學習精確的3D形狀。ShadeGAN還可以在圖像合成過程中控制照明條件,實現自然的圖像重新照明效果。為了降低計算成本,研究團隊進一步設計了一種輕量級曲面跟蹤網絡,它為生成隱式模型提供了一種高效的體繪制技術,顯著加快了訓練和推理速度。