XGBoost機器學習模型的決策過程

使用 XGBoost 的算法在 Kaggle 和其它數據科學競賽中經常可以獲得好成績,因此受到了人們的歡迎。本文用一個具體的數據集分析了 XGBoost 機器學習模型的預測過程,通過使用可視化手段展示結果,我們可以更好地理解模型的預測過程。
隨著機器學習的產業應用不斷發展,理解、解釋和定義機器學習模型的工作原理似乎已成日益明顯的趨勢。對于非深度學習類型的機器學習分類問題,XGBoost 是最流行的庫。由于 XGBoost 可以很好地擴展到大型數據集中,并支持多種語言,它在商業化環境中特別有用。例如,使用 XGBoost 可以很容易地在 Python 中訓練模型,并把模型部署到 Java 產品環境中。
雖然 XGBoost 可以達到很高的準確率,但對于 XGBoost 如何進行決策而達到如此高的準確率的過程,還是不夠透明。當直接將結果移交給客戶的時候,這種不透明可能是很嚴重的缺陷。理解事情發生的原因是很有用的。那些轉向應用機器學習理解數據的公司,同樣需要理解來自模型的預測。這一點變得越來越重要。例如,誰也不希望信貸機構使用機器學習模型預測用戶的信譽,卻無法解釋做出這些預測的過程。
另一個例子是,如果我們的機器學習模型說,一個婚姻檔案和一個出生檔案是和同一個人相關的(檔案關聯任務),但檔案上的日期暗示這樁婚姻的雙方分別是一個很老的人和一個很年輕的人,我們可能會質疑為什么模型會將它們關聯起來。在諸如這樣的例子中,理解模型做出這樣的預測的原因是非常有價值的。其結果可能是模型考慮了名字和位置的獨特性,并做出了正確的預測。但也可能是模型的特征并沒有正確考慮檔案上的年齡差距。在這個案例中,對模型預測的理解可以幫助我們尋找提升模型性能的方法。
在這篇文章中,我們將介紹一些技術以更好地理解 XGBoost 的預測過程。這允許我們在利用 gradient boosting 的威力的同時,仍然能理解模型的決策過程。
為了解釋這些技術,我們將使用 Titanic 數據集。該數據集有每個泰坦尼克號乘客的信息(包括乘客是否生還)。我們的目標是預測一個乘客是否生還,并且理解做出該預測的過程。即使是使用這些數據,我們也能看到理解模型決策的重要性。想象一下,假如我們有一個關于最近發生的船難的乘客數據集。建立這樣的預測模型的目的實際上并不在于預測結果本身,但理解預測過程可以幫助我們學習如何最大化意外中的生還者。
import pandas as pd
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import operator
import matplotlib.pyplot as plt
import seaborn as sns
import lime.lime_tabular
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import Imputer
import numpy as np
from sklearn.grid_search import GridSearchCV
%matplotlib inline
我們要做的首件事是觀察我們的數據,你可以在 Kaggle 上找到(https://www.kaggle.com/c/titanic/data)這個數據集。拿到數據集之后,我們會對數據進行簡單的清理。即:
- 清除名字和乘客 ID
- 把分類變量轉化為虛擬變量
- 用中位數填充和去除數據
這些清洗技巧非常簡單,本文的目標不是討論數據清洗,而是解釋 XGBoost,因此這些都是快速、合理的清洗以使模型獲得訓練。
data = pd.read_csv("./data/titantic/train.csv")
y = data.Survived
X = data.drop(["Survived", "Name", "PassengerId"], 1)
X = pd.get_dummies(X)
現在讓我們將數據集分為訓練集和測試集。
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=42)
并通過少量的超參數測試構建一個訓練管道。
pipeline = Pipeline(
[('imputer', Imputer(strategy='median')),
('model', XGBClassifier())])
parameters = dict(model__max_depth=[3, 5, 7],
model__learning_rate=[.01, .1],
model__n_estimators=[100, 500])
cv = GridSearchCV(pipeline, param_grid=parameters)
cv.fit(X_train, y_train)
接著查看測試結果。為簡單起見,我們將會使用與 Kaggle 相同的指標:準確率。
test_predictions = cv.predict(X_test)
print("Test Accuracy: {}".format(
accuracy_score(y_test, test_predictions)))
Test Accuracy: 0.8101694915254237
至此我們得到了一個還不錯的準確率,在 Kaggle 的大約 9000 個競爭者中排到了前 500 名。因此我們還有進一步提升的空間,但在此將作為留給讀者的練習。
我們繼續關于理解模型學習到什么的討論。常用的方法是使用 XGBoost 提供的特征重要性(feature importance)。特征重要性的級別越高,表示該特征對改善模型預測的貢獻越大。接下來我們將使用重要性參數對特征進行分級,并比較相對重要性。
fi = list(zip(X.columns, cv.best_estimator_.named_steps['model'].feature_importances_))
fi.sort(key = operator.itemgetter(1), reverse=True)
top_10 = fi[:10]
x = [x[0] for x in top_10]
y = [x[1] for x in top_10]
top_10_chart = sns.barplot(x, y)
plt.setp(top_10_chart.get_xticklabels(), rotation=90)
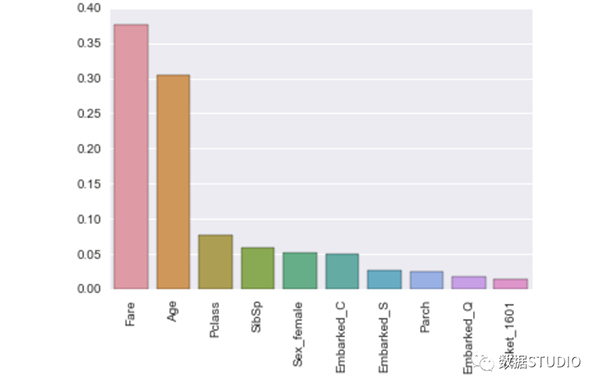
從上圖可以看出,票價和年齡是很重要的特征。我們可以進一步查看生還/遇難與票價的相關分布:
sns.barplot(y_train, X_train['Fare'])
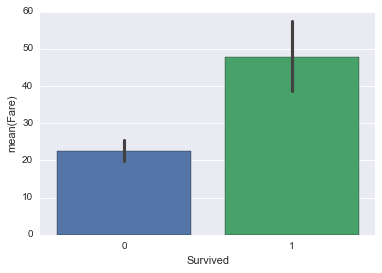
我們可以很清楚地看到,那些生還者相比遇難者的平均票價要高得多,因此把票價當成重要特征可能是合理的。
特征重要性可能是理解一般的特征重要性的不錯方法。假如出現了這樣的特例,即模型預測一個高票價的乘客無法獲得生還,則我們可以得出高票價并不必然導致生還,接下來我們將分析可能導致模型得出該乘客無法生還的其它特征。
這種個體層次上的分析對于生產式機器學習系統可能非常有用。考慮其它例子,使用模型預測是否可以某人一項貸款。我們知道信用評分將是模型的一個很重要的特征,但是卻出現了一個擁有高信用評分卻被模型拒絕的客戶,這時我們將如何向客戶做出解釋?又該如何向管理者解釋?
幸運的是,近期出現了華盛頓大學關于解釋任意分類器的預測過程的研究。他們的方法稱為 LIME,已經在 GitHub 上開源(https://github.com/marcotcr/lime)。本文不打算對此展開討論,可以參見論文(https://arxiv.org/pdf/1602.04938.pdf)
接下來我們嘗試在模型中應用 LIME。基本上,首先需要定義一個處理訓練數據的解釋器(我們需要確保傳遞給解釋器的估算訓練數據集正是將要訓練的數據集):
X_train_imputed = cv.best_estimator_.named_steps['imputer'].transform(X_train)
explainer = lime.lime_tabular.LimeTabularExplainer(X_train_imputed,
feature_names=X_train.columns.tolist(),
class_names=["Not Survived", "Survived"],
discretize_continuous=True)
隨后你必須定義一個函數,它以特征數組為變量,并返回一個數組和每個類的概率:
model = cv.best_estimator_.named_steps['model']
def xgb_prediction(X_array_in):
if len(X_array_in.shape) < 2:
X_array_in = np.expand_dims(X_array_in, 0)
return model.predict_proba(X_array_in)
最后,我們傳遞一個示例,讓解釋器使用你的函數輸出特征數和標簽:
X_test_imputed = cv.best_estimator_.named_steps['imputer'].transform(X_test)
exp = explainer.explain_instance(
X_test_imputed[1],
xgb_prediction,
num_features=5,
top_labels=1)
exp.show_in_notebook(show_table=True,
show_all=False)
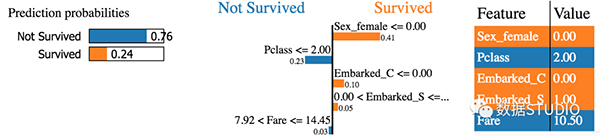
在這里我們有一個示例,76% 的可能性是不存活的。我們還想看看哪個特征對于哪個類貢獻最大,重要性又如何。例如,在 Sex = Female 時,生存幾率更大。讓我們看看柱狀圖:
sns.barplot(X_train['Sex_female'], y_train)
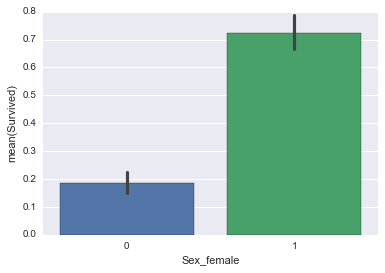
所以這看起來很有道理。如果你是女性,這就大大提高了你在訓練數據中存活的幾率。所以為什么預測結果是「未存活」?看起來 Pclass =2.0 大大降低了存活率。讓我們看看:
sns.barplot(X_train['Pclass'], y_train)
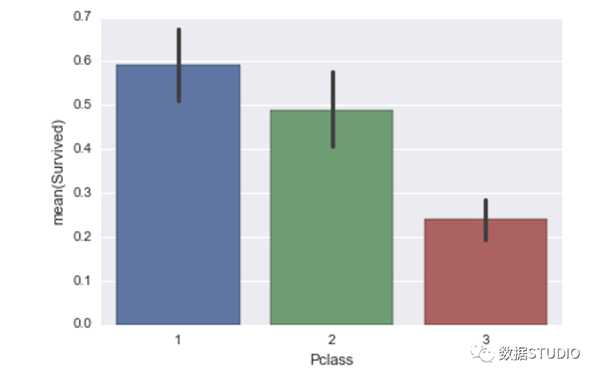
看起來 Pclass 等于 2 的存活率還是比較低的,所以我們對于自己的預測結果有了更多的理解。看看 LIME 上展示的 top5 特征,看起來這個人似乎仍然能活下來,讓我們看看它的標簽:
y_test.values[0]>>>1
這個人確實活下來了,所以我們的模型有錯!感謝 LIME,我們可以對問題原因有一些認識:看起來 Pclass 可能需要被拋棄。這種方式可以幫助我們,希望能夠找到一些改進模型的方法。
本文為讀者提供了一個簡單有效理解 XGBoost 的方法。希望這些方法可以幫助你合理利用 XGBoost,讓你的模型能夠做出更好的推斷。