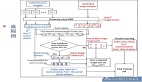
打架識別,基于循環神經網絡RNN的視頻分類任務
哈嘍,大家好。
今天給大家分享AI項目——打架識別。

使用的技術跟我們上次分享的摔倒識別不同,摔倒識別使用的是基于骨骼點的時空卷積神經網絡,適用于人體骨骼行為,而這次分享的打架識別使用的是循環神經網絡RNN,可以實現更通用的視頻分類任務。
當然也可以用Vision Transformer,文中也有介紹。
代碼已經打包好了,獲取方式見評論區。
1. 整體思路
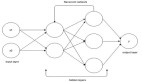
視頻其實就是某種行為的連續序列,因此要使用序列模型處理,循環神經網絡RNN就是序列模型。
RNN最初應用在自然語言處理中,如:根據輸入詞,判斷下一次詞的概率

模型為了讀懂每個詞代表的含義,模型會把每個詞用n維向量表示,這個過程 其實就是word embedding。
按照這個思路,一段視頻其實就是一句話,視頻里每張畫面就是一個詞,同樣地,我們也可以用卷機神經網絡將每張圖映射成n維向量。
所以,我們就可以訓練一個RNN模型,將表示視頻的n維向量送入RNN模型,讓他輸出視頻類別的概率。
現在比較流行的RNN模型有LSTM、GRU,本文使用的是GRU。
2. 數據集
打架的開源數據集有很多,如:fight-detection-surv-dataset、A-Dataset-for-Automatic-Violence-Detection-in-Videos和UBI_FIGHTS等等。
我使用的是fight-detection-surv-dataset數據集,包括 150 個打架視頻和 150 個正常視頻。
數據集很小,訓練的時候很容易過擬合,精度只有 70%。但思路和代碼都是可以復用的。
大家做的時候可以換成大的數據集,比如:ucf數據,包含很多動作視頻

ucf50數據集
我用這個數據集訓練過 GRU 和 Transformer模型,效果還可以。
3. 提取視頻特征
接下來,我們要做的就是提取視頻特征,將視頻中每張畫面映射成n維向量。
使用InceptionResNetV2網絡,輸入一張圖片,輸出的是 1536 維向量。
這樣,詞向量就已經有了。然后再抽取每個視頻的前20幀,組成一個句子。
dataset_feats是20 * 1536的向量。
這樣,我們就將一個視頻用向量形式表示出來了。
4. 循環神經網絡
GRU是LSTM的一個變種

模型搭建也比較簡單。
GRU超參數 4 代表 4 個 unit,即:模型輸出向量長度是 4,大家如果做其他分類任務,可以嘗試調整該值。

編譯模型
這是個多分類任務,因此損失函數使用sparse_categorical_crossentropy。
接著就可以訓練模型了,模型在訓練集和測試集精度如下:

5. vision transformer
同樣的,我們也可以用流行的Transformer來訓練視頻分類模型

對于視頻分類任務,不需要Decoder網絡,用多頭自注意力模型搭建一個 Encoder網絡即可。
關于vision transformer后續有機會的話我會專門分享一個項目,這次代碼以GRU為主。