譯者 | 朱先忠
審校 | 重樓
自2017年推出以來,轉(zhuǎn)換器(Transformers)已成為機(jī)器學(xué)習(xí)領(lǐng)域的一支突出力量,徹底改變了專業(yè)翻譯和自動完成服務(wù)的能力。
最近,隨著OpenAI公司的ChatGPT和Meta公司的LLama等大型語言模型的出現(xiàn),轉(zhuǎn)換器的受歡迎程度飆升。所有上述這些模型都建立在轉(zhuǎn)換器架構(gòu)的基礎(chǔ)上,引起了業(yè)界極大的關(guān)注。通過利用轉(zhuǎn)換器的力量,這些模型在自然語言理解和生成方面取得了顯著突破。
盡管目前網(wǎng)絡(luò)上已經(jīng)存儲很多很好的資源可以解釋轉(zhuǎn)換器的工作方式,但我發(fā)現(xiàn)自己僅停留在一個理解轉(zhuǎn)換器數(shù)學(xué)工作原理的層次上,卻很難直觀地解釋轉(zhuǎn)換器是如何工作的。在進(jìn)行了多次采訪,與我的同事交談,并就這個問題進(jìn)行了閃電式的(簡短)演講之后,我發(fā)現(xiàn)似乎很多人都存在這樣的問題!
在這篇博客文章中,我將努力提供一個關(guān)于轉(zhuǎn)換器如何在不依賴代碼或數(shù)學(xué)原理的情況下工作原理的高級解釋。我的目標(biāo)是避免混淆技術(shù)術(shù)語,避免與以前的體系結(jié)構(gòu)進(jìn)行比較。雖然我會盡量保持簡單,但這并不容易,因為轉(zhuǎn)換器非常復(fù)雜,但我希望它能更好地直觀地了解它們做什么以及如何做。
什么是轉(zhuǎn)換器?
轉(zhuǎn)換器是一種神經(jīng)網(wǎng)絡(luò)架構(gòu),非常適合處理序列作為輸入的任務(wù)。在這種情況下,序列最常見的例子可能是一個句子,我們可以將其視為一組有序的單詞。
這些模型的目的是為序列中的每個元素創(chuàng)建一個數(shù)字化表示,用于封裝關(guān)于元素及其相鄰上下文的基本信息。然后,可以將得到的數(shù)字表示傳遞給下游網(wǎng)絡(luò),下游網(wǎng)絡(luò)可以利用這些信息來執(zhí)行各種任務(wù),包括生成和分類。
通過創(chuàng)建這樣豐富的表示,這些模型使下游網(wǎng)絡(luò)能夠更好地理解輸入序列中的潛在模式和關(guān)系,這增強(qiáng)了它們生成連貫和上下文相關(guān)輸出的能力。
轉(zhuǎn)換器的關(guān)鍵優(yōu)勢在于它們能夠處理序列中的很長范圍的依賴關(guān)系,并且效率很高;能夠并行處理序列。這對于機(jī)器翻譯、情感分析和文本生成等任務(wù)特別有用。

Azure OpenAI服務(wù)DALL-E模型生成的圖像,其中帶有以下提示:“The green and black Matrix code in the shape of Optimus Prime(擎天柱形狀的綠色和黑色矩陣代碼)”
輸入到轉(zhuǎn)換器的內(nèi)容
要將輸入饋送到轉(zhuǎn)換器中,我們必須首先將其轉(zhuǎn)換為標(biāo)記序列——表示我們輸入的一組整數(shù)。
由于轉(zhuǎn)換器最初應(yīng)用于自然語言處理領(lǐng)域,所以讓我們首先考慮這個場景。將一個句子轉(zhuǎn)換為一系列標(biāo)記的最簡單方法是定義一個詞匯表,該詞匯表充當(dāng)查找表,將單詞映射為整數(shù);我們可以保留一個特定的數(shù)字來表示這個詞匯表中不包含的任何單詞,這樣我們就可以總是分配一個整數(shù)值。

在實(shí)踐中,這是一種過于簡單的文本編碼方式,因為cat和cats等詞會被視為完全不同的標(biāo)記,盡管它們是對同一動物的單數(shù)和復(fù)數(shù)描述!為了克服這一點(diǎn),人們設(shè)計了不同的標(biāo)記化策略,如字節(jié)對編碼,在對單詞進(jìn)行索引之前,將其分解成更小的塊。此外,添加特殊的標(biāo)記來表示句子的開頭和結(jié)尾等特征,為模型提供額外的上下文,這通常很有用。
讓我們考慮下面的例子,以更好地理解標(biāo)記化過程。
“Hello there, isn’t the weather nice today in Drosval?(你好,德羅斯瓦爾市今天天氣好嗎?)”
這里,Drosval是GPT-4使用以下提示生成的名稱:“Can you create a fictional place name that sounds like it could belong to David Gemmell’s Drenai universe?(你能創(chuàng)建一個聽起來可能屬于David Gemmell的Drenai宇宙的虛構(gòu)地名嗎?)”;這是故意選擇的,因為它不應(yīng)該出現(xiàn)在任何訓(xùn)練過的機(jī)器模型的詞匯表中。
借助轉(zhuǎn)換器庫中的 bert-base-uncased分詞器,將上面的語句轉(zhuǎn)換為以下標(biāo)記序列:

表示每個單詞的整數(shù)將根據(jù)特定的模型訓(xùn)練和標(biāo)記化策略而變化。解碼后,我們可以看到每個標(biāo)記所代表的單詞:

有趣的是,我們可以看到這與我們當(dāng)初的輸入不同。其中添加了一些特殊的標(biāo)記,我們的縮寫被拆分為多個標(biāo)記,我們虛構(gòu)的地名由不同的“塊”表示。當(dāng)我們使用前面所述的bert-base-uncased模型時,我們也失去了所有的大寫上下文。
然而,雖然我們在示例中使用了一個句子,但轉(zhuǎn)換器并不局限于文本輸入;該體系結(jié)構(gòu)在視覺任務(wù)上也取得了良好的效果。為了將圖像轉(zhuǎn)換為序列,ViT(譯者注:是指轉(zhuǎn)換器在CV領(lǐng)域中的兩個經(jīng)典算法之一,另一個算法是DeiT)的作者將圖像切片為不重疊的16x16像素塊,并在將其傳遞到模型中之前將其連接成長向量。如果我們在推薦系統(tǒng)中使用轉(zhuǎn)換器,一種方法可以是使用用戶瀏覽的最后n個項目的項目ID作為我們網(wǎng)絡(luò)的輸入。如果我們能夠為我們的域創(chuàng)建一個有意義的輸入標(biāo)記表示,我們就可以將其輸入到轉(zhuǎn)換器網(wǎng)絡(luò)中。
嵌入我們的標(biāo)記
一旦我們有了一個整數(shù)序列來表示我們的輸入,我們就可以將它們轉(zhuǎn)換為嵌入。嵌入是一種表示信息的方式,可以通過機(jī)器學(xué)習(xí)算法輕松處理;他們的目的是通過將信息表示為一系列數(shù)字來捕捉以壓縮格式編碼的標(biāo)記的含義。最初,嵌入被初始化為隨機(jī)數(shù)序列,并且在訓(xùn)練期間學(xué)習(xí)有意義的表示。然而,這些嵌入有一個固有的限制:它們沒有考慮到標(biāo)記出現(xiàn)的上下文。這有兩個方面。
一個問題是,根據(jù)任務(wù)的不同,當(dāng)我們嵌入標(biāo)記時,我們可能還希望保留標(biāo)記的順序;這在NLP等領(lǐng)域尤其重要;否則,我們基本上會采用單詞袋方法。為了克服這一點(diǎn),我們將位置編碼應(yīng)用于嵌入。雖然有多種方法可以創(chuàng)建位置嵌入,但主要思想是我們有另一組嵌入,它們表示輸入序列中每個標(biāo)記的位置,并與我們的標(biāo)記嵌入相結(jié)合。

另一個問題是,根據(jù)周圍的標(biāo)記內(nèi)容,標(biāo)記可能會有不同的含義。考慮以下句子:
It’s dark, who turned off the light?(天黑了,誰關(guān)燈了?)
Wow, this parcel is really light!(哇,這個包裹真輕!)
在這里,“l(fā)ight”這個詞被用于兩個不同的上下文,在不同的上下文中它有完全不同的含義!然而,根據(jù)標(biāo)記化策略,嵌入可能是相同的。在轉(zhuǎn)換器中,這是由它的注意力機(jī)制來處理的。
從概念上講,什么是注意力?
轉(zhuǎn)換器架構(gòu)使用的最重要的機(jī)制可能是注意力,它使網(wǎng)絡(luò)能夠了解輸入序列的哪些部分與給定任務(wù)最相關(guān)。對于序列中的每個標(biāo)記,注意力機(jī)制識別哪些其他標(biāo)記對于理解給定上下文中的當(dāng)前標(biāo)記很重要。在我們探索如何在轉(zhuǎn)換器中實(shí)現(xiàn)這一點(diǎn)之前,讓我們從簡單的內(nèi)容開始,試著理解注意力機(jī)制在概念上試圖實(shí)現(xiàn)什么,以便建立我們的直覺理解基礎(chǔ)。
理解注意力的一種方法是將其視為一種方法,該方法將每個標(biāo)記嵌入替換為包含關(guān)于其相鄰標(biāo)記的信息的嵌入;而不是對每個標(biāo)記使用相同的嵌入,而不管其上下文如何。如果我們知道哪些標(biāo)記與當(dāng)前標(biāo)記相關(guān),那么捕獲此上下文的一種方法是創(chuàng)建這些嵌入的加權(quán)平均值,或者更一般地說,線性組合。
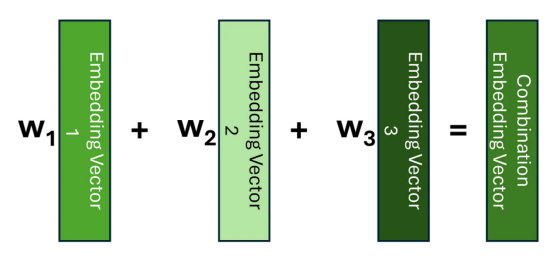
讓我們考慮一個簡單的例子,說明如何查找我們前面看到的一個句子。在應(yīng)用注意力之前,序列中的嵌入沒有其鄰近的上下文。因此,我們可以將單詞“light”的嵌入可視化為以下線性組合。

在這里,我們可以看到,我們的權(quán)重只是單位矩陣。在應(yīng)用我們的注意力機(jī)制后,我們想學(xué)習(xí)一個權(quán)重矩陣,這樣我們就可以用類似于下面的方式來表達(dá)我們的“light”嵌入。

這一次,對與我們選擇的標(biāo)記的序列的最相關(guān)部分相對應(yīng)的嵌入賦予更大的權(quán)重;這應(yīng)當(dāng)確保在新的嵌入向量中捕獲最重要的上下文。
包含當(dāng)前上下文信息的嵌入有時被稱為上下文嵌入,這最終是我們試圖創(chuàng)建的。
既然我們已經(jīng)對注意力試圖實(shí)現(xiàn)的目標(biāo)有了很高的理解,那么讓我們在下一節(jié)中來探討一下這是如何實(shí)際實(shí)現(xiàn)的。
注意力是如何計算的?
注意力有多種類型,主要區(qū)別在于用于執(zhí)行線性組合的權(quán)重的計算方式。在這里,我們來考慮一下原始論文中介紹的縮放點(diǎn)積注意力,因為這是最常見的方法。在本節(jié)中,假設(shè)我們所有的嵌入都已進(jìn)行了位置編碼。
回想一下,我們的目標(biāo)是使用原始嵌入的線性組合來創(chuàng)建上下文嵌入,讓我們從簡單的講解開始,假設(shè)我們可以將所需的所有必要信息編碼到我們學(xué)習(xí)的嵌入向量中,我們所需要計算的只是權(quán)重。
要計算權(quán)重,我們必須首先確定哪些標(biāo)記彼此相關(guān)。為了實(shí)現(xiàn)這一點(diǎn),我們需要在兩個嵌入之間建立一個相似性的概念。表示這種相似性的一種方法是使用點(diǎn)積,我們希望學(xué)習(xí)嵌入,這樣得分越高,兩個單詞就越相似。
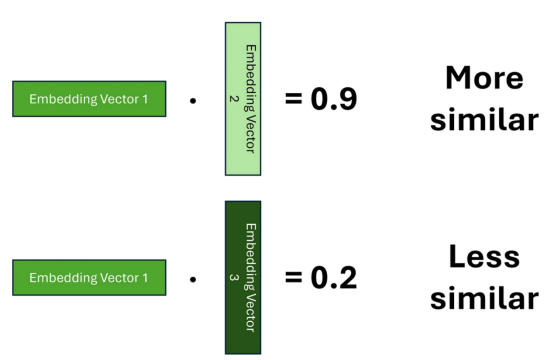
對于每個標(biāo)記,我們需要計算其與序列中其他標(biāo)記的相關(guān)性,我們可以將其推廣為矩陣乘法,這為我們提供了權(quán)重矩陣;其通常被稱為注意力得分。為了確保我們的權(quán)重總和為1,我們還應(yīng)用SoftMax函數(shù)。然而,由于矩陣乘法可以產(chǎn)生任意大的數(shù)字,這可能導(dǎo)致SoftMax函數(shù)對于大的注意力分?jǐn)?shù)返回非常小的梯度;這可能導(dǎo)致訓(xùn)練過程中的梯度消失問題。為了抵消這種影響,在應(yīng)用SoftMax之前,將注意力分?jǐn)?shù)乘以比例因子。
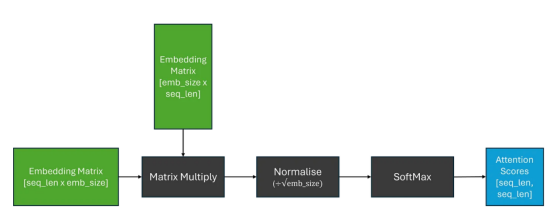
現(xiàn)在,為了得到我們的上下文嵌入矩陣,我們可以將注意力得分與原始嵌入矩陣相乘;這相當(dāng)于我們的嵌入的線性組合。
嵌入是位置編碼的") 簡化的注意力計算:假設(shè)嵌入是位置編碼的
簡化的注意力計算:假設(shè)嵌入是位置編碼的
雖然模型可能學(xué)習(xí)足夠復(fù)雜的嵌入,以生成注意力得分和隨后的上下文嵌入;我們試圖將大量信息壓縮到嵌入維度中,嵌入維度通常很小。
因此,為了讓模型更容易學(xué)習(xí)這項任務(wù),讓我們介紹一些更容易學(xué)習(xí)的參數(shù)!與其直接使用嵌入矩陣,不如讓它通過三個獨(dú)立的線性層(矩陣乘法);這應(yīng)該使模型能夠“注意”嵌入的不同部分。如下圖所示:
積自注意:假設(shè)嵌入是位置編碼的") 縮放后的點(diǎn)積自注意:假設(shè)嵌入是位置編碼的
縮放后的點(diǎn)積自注意:假設(shè)嵌入是位置編碼的
從圖像中,我們可以看到線性投影被標(biāo)記為Q、K和V。在最初的論文中,這些投影被命名為Query、Key和Value,據(jù)說是從信息檢索中獲得的靈感。就我個人而言,我從未發(fā)現(xiàn)這種類比有助于我的理解,所以我傾向于不關(guān)注這一點(diǎn);為了與文獻(xiàn)保持一致,我遵循了這里的術(shù)語,并明確表示這些線性層是不同的。
現(xiàn)在,我們了解了這個過程是如何工作的,我們可以把注意力計算看作一個有三個輸入的單個塊,這些輸入將傳遞給Q、K和V。

當(dāng)我們將相同的嵌入矩陣傳遞給Q、K和V時,這被稱為自注意。
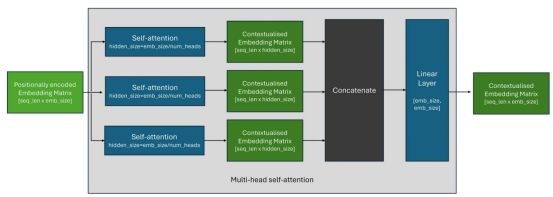
什么是多頭注意力?
在實(shí)踐中,我們經(jīng)常并行使用多個自注意塊,以便使轉(zhuǎn)換器能夠同時關(guān)注輸入序列的不同部分——這被稱為多頭注意(multi-head attention)。
多頭注意力背后的想法很簡單,多個獨(dú)立的自我注意力塊的輸出被連接在一起,然后通過線性層。這個線性層使模型能夠?qū)W習(xí)組合來自每個注意力頭部的上下文信息。
在實(shí)踐中,每個自注意塊中使用的隱藏維度大小通常被選擇為原始嵌入大小除以注意頭的數(shù)量;以保持嵌入矩陣的形狀。
轉(zhuǎn)換器還由什么組成?
盡管介紹轉(zhuǎn)換器的論文(現(xiàn)在臭名昭著)被命名為“注意力”,但這有點(diǎn)令人困惑,因為轉(zhuǎn)換器的組件不僅僅是注意力!
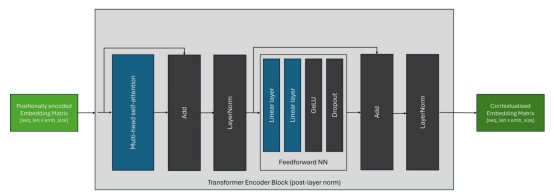
其實(shí),轉(zhuǎn)換器塊還包含以下內(nèi)容:
- 前饋神經(jīng)網(wǎng)絡(luò)(FFN):一種兩層神經(jīng)網(wǎng)絡(luò),獨(dú)立應(yīng)用于批量和序列中的每個標(biāo)記嵌入。FFN塊的目的是將額外的可學(xué)習(xí)參數(shù)引入到轉(zhuǎn)換器中,這些參數(shù)負(fù)責(zé)確保上下文嵌入是不同的和分散的。最初的論文使用了GeLU激活函數(shù),但FFN的組件可能因架構(gòu)而異。
- 層規(guī)范化:有助于穩(wěn)定深度神經(jīng)網(wǎng)絡(luò)的訓(xùn)練,包括轉(zhuǎn)換器。它使每個序列的激活函數(shù)規(guī)范化,防止它們在訓(xùn)練過程中變得過大或過小;這可能導(dǎo)致梯度相關(guān)的問題,例如梯度消失或爆炸。這種穩(wěn)定性對于有效訓(xùn)練非常深入的轉(zhuǎn)換器模型至關(guān)重要。
- 跳過連接:與ResNet架構(gòu)一樣,殘差連接用于緩解消失梯度問題并提高訓(xùn)練穩(wěn)定性。
雖然轉(zhuǎn)換器架構(gòu)自引入以來一直保持相當(dāng)穩(wěn)定,但層規(guī)范化塊的位置可能因轉(zhuǎn)換器架構(gòu)而異。原始架構(gòu),現(xiàn)在稱為后層規(guī)范(post-layer norm),如下所示:
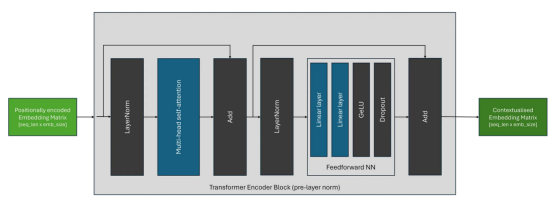
如下圖所示,在最近的體系結(jié)構(gòu)中,最常見的放置是前層規(guī)范(pre-layer norm),它將規(guī)范化塊放置在跳過連接中的自注意塊和FFN塊之前。
轉(zhuǎn)換器有哪些不同類型?
雖然現(xiàn)在有許多不同的轉(zhuǎn)換器架構(gòu),但大多數(shù)可以分為三種主要類型。
編碼器架構(gòu)
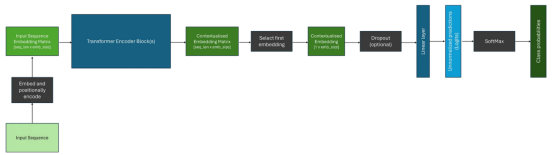
編碼器模型旨在產(chǎn)生可用于下游任務(wù)(如分類或命名實(shí)體識別)的上下文嵌入,因為注意力機(jī)制能夠注意整個輸入序列;這就是本文迄今為止所探討的體系結(jié)構(gòu)類型。最流行的編碼器專用轉(zhuǎn)換器系列是BERT及其變體。
在將我們的數(shù)據(jù)通過一個或多個轉(zhuǎn)換器塊之后,我們有一個復(fù)雜的上下文嵌入矩陣,表示序列中每個標(biāo)記的嵌入。然而,要將其用于諸如分類之類的下游任務(wù),我們只需要進(jìn)行一次預(yù)測。傳統(tǒng)上,第一個標(biāo)記被獲取,并通過分類頭部;其通常包含Dropout層和Linear層。可以通過SoftMax函數(shù)將這些層的輸出轉(zhuǎn)換為類別概率。下面描述了一個這樣的例子。
解碼器架構(gòu)
與編碼器架構(gòu)幾乎相同,關(guān)鍵區(qū)別在于解碼器架構(gòu)采用了屏蔽(或因果)自注意層,因此注意機(jī)制只能注意輸入序列的當(dāng)前和先前元素;這意味著生成的上下文嵌入只考慮先前的上下文。流行的僅含解碼器的模型包括GPT系列。
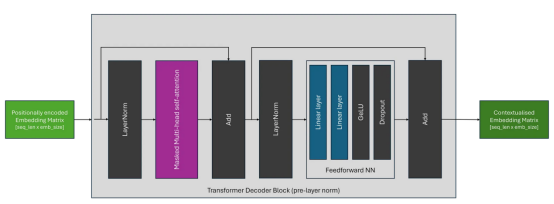
這通常是通過用二進(jìn)制下三角矩陣屏蔽注意力得分,并用負(fù)無窮大替換未屏蔽的元素來實(shí)現(xiàn)的;當(dāng)通過以下SoftMax操作時,這將確保這些位置的注意力得分等于零。我們可以更新我們以前的自我注意圖,將其包括在內(nèi),如下所示:
采用位置編碼嵌入") 屏蔽自注意計算:假設(shè)采用位置編碼嵌入
屏蔽自注意計算:假設(shè)采用位置編碼嵌入
由于解碼器只能從當(dāng)前位置向后參與計算,因此解碼器架構(gòu)通常用于自回歸任務(wù),如序列生成等。然而,當(dāng)使用上下文嵌入來生成序列時,與使用編碼器相比,還有一些額外的考慮因素。下面顯示了一個示例。
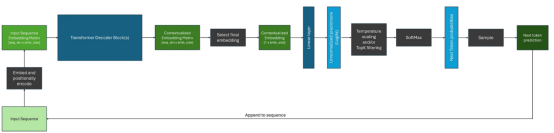
我們可以注意到,雖然解碼器為輸入序列中的每個標(biāo)記生成上下文嵌入,但在生成序列時,我們通常使用與最終標(biāo)記相對應(yīng)的嵌入作為后續(xù)層的輸入。
此外,在將SoftMax函數(shù)應(yīng)用于logits之后,如果不應(yīng)用過濾方案,我們將在模型詞匯表中的每個標(biāo)記上接收概率分布;這可能非常大!通常,我們希望使用各種過濾策略來減少潛在選項的數(shù)量,其中一些最常見的方法是:
- 溫度調(diào)整:溫度(Temperature)是一個應(yīng)用于SoftMax操作內(nèi)部的參數(shù),它會影響生成文本的隨機(jī)性。它通過改變輸出單詞的概率分布來確定模型輸出的創(chuàng)造性或重點(diǎn)內(nèi)容。溫度參數(shù)越高,分布越平坦,輸出越多樣化。
- Top-P采樣:這種方法基于給定的概率閾值過濾下一個標(biāo)記的潛在候選者的數(shù)量,并基于高于該閾值的候選者重新分布概率分布。
- Top-K采樣:這種方法根據(jù)其logit或概率得分(取決于實(shí)現(xiàn))將潛在候選者的數(shù)量限制為K個最可能的標(biāo)記。有關(guān)這些方法的更多詳細(xì)信息,請訪問鏈接:https://peterchng.com/blog/2023/05/02/token-selection-strategies-top-k-top-p-and-temperature/。
一旦我們改變或減少了下一個標(biāo)記的潛在候選者的概率分布,我們就可以從中采樣來得到我們的預(yù)測——這只是從多項式分布中采樣。然后將預(yù)測的標(biāo)記附加到輸入序列并反饋到模型中,直到生成了期望數(shù)量的標(biāo)記,或者模型生成了停止標(biāo)記;表示序列結(jié)束的特殊標(biāo)記。
編碼器-解碼器架構(gòu)
最初,轉(zhuǎn)換器是作為機(jī)器翻譯的一種架構(gòu)提出的,并使用編碼器和解碼器來實(shí)現(xiàn)這一目標(biāo);使用所述編碼器來創(chuàng)建中間表示。雖然編碼器-解碼器轉(zhuǎn)換器已經(jīng)變得不那么常見,但諸如T5之類的架構(gòu)展示了如何將諸如問題回答、總結(jié)和分類之類的任務(wù)構(gòu)建為序列到序列的問題,并使用這種方法來解決。
與編碼器-解碼器架構(gòu)的關(guān)鍵區(qū)別在于,解碼器使用編碼器-解碼器注意力,其在注意力計算期間使用編碼器的輸出(作為K和V)和解碼器塊的輸入(作為Q)。這與自注意形成對比,在自注意中,相同的輸入嵌入矩陣用于所有輸入。除此之外,整個生成過程與僅使用解碼器的架構(gòu)非常相似。
我們可以將編碼器-解碼器架構(gòu)可視化,如下圖所示。在這里,為了簡化圖示,我選擇描繪原始論文中所見的轉(zhuǎn)換器的后層規(guī)范的變體;其中規(guī)范層位于注意塊之后。
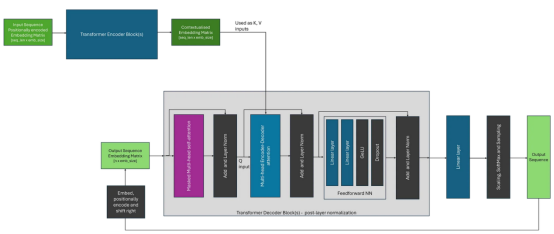
結(jié)論
總之,希望本文能夠給您提供一種關(guān)于轉(zhuǎn)換器工作原理的直覺理解幫助,有助于您以一種易于理解的方式把握此架構(gòu)中的一些細(xì)節(jié),并成為揭開現(xiàn)代轉(zhuǎn)換器架構(gòu)神秘面紗的良好起點(diǎn)!
最后,除非另有說明,否則所有圖像均由作者創(chuàng)作。
參考資料
- [1706.03762] Attention Is All You Need (arxiv.org):
https://arxiv.org/abs/1706.03762。 - Recent Advances in Google Translate — Google Research Blog:
https://blog.research.google/2020/06/recent-advances-in-google-translate.html。 - How GitHub Copilot is getting better at understanding your code — The GitHub Blog:
https://github.blog/2023-05-17-how-github-copilot-is-getting-better-at-understanding-your-code/。 - Introducing ChatGPT (openai.com):https://openai.com/blog/chatgpt。
- gpt-4.pdf (openai.com):
https://cdn.openai.com/papers/gpt-4.pdf#:~:text=This%20technical%20report%20presents%20GPT-4%2C%20a%20large%20multimodal,as%20dialogue%20systems%2C%20text%20summarization%2C%20and%20machine%20translation.。 - Introducing LLaMA: A foundational, 65-billion-parameter language model (meta.com):
https://ai.meta.com/blog/large-language-model-llama-meta-ai/。 - The Illustrated Transformer — Jay Alammar — Visualizing machine learning one concept at a time. (jalammar.github.io):http://jalammar.github.io/illustrated-transformer/。
- Byte-Pair Encoding tokenization — Hugging Face NLP Course:https://huggingface.co/learn/nlp-course/chapter6/5?fw=pt。
- Drenai series | David Gemmell Wiki | Fandom:https://davidgemmell.fandom.com/wiki/Drenai_series。
- bert-base-uncased · Hugging Face:
https://huggingface.co/bert-base-uncased。 - Transformers (huggingface.co):
https://huggingface.co/docs/transformers/index。 - [2010.11929v2] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (arxiv.org)
- Getting Started With Embeddings (huggingface.co):https://huggingface.co/blog/getting-started-with-embeddings。
- A Gentle Introduction to the Bag-of-Words Model — MachineLearningMastery.com:https://machinelearningmastery.com/gentle-introduction-bag-words-model/。
- [2104.09864] RoFormer: Enhanced Transformer with Rotary Position Embedding (arxiv.org):https://arxiv.org/abs/2104.09864。
- Scaled Dot-Product Attention Explained | Papers With Code:https://paperswithcode.com/method/scaled。
- Softmax function — Wikipedia:https://en.wikipedia.org/wiki/Softmax_function。
- [1607.06450] Layer Normalization (arxiv.org):https://arxiv.org/abs/1607.06450。
- Vanishing gradient problem — Wikipedia:https://en.wikipedia.org/wiki/Vanishing_gradient_problem。
- [1512.03385] Deep Residual Learning for Image Recognition (arxiv.org):
https://arxiv.org/abs/1512.03385。 - [1810.04805] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (arxiv.org):https://arxiv.org/abs/1810.04805。
- [2005.14165] Language Models are Few-Shot Learners (arxiv.org):https://arxiv.org/abs/2005.14165。
- Token selection strategies: Top-K, Top-P, and Temperature (peterchng.com):https://peterchng.com/blog/2023/05/02/token-selection-strategies-top-k-top-p-and-temperature/。
- Multinomial distribution — Wikipedia:https://en.wikipedia.org/wiki/Multinomial_distribution。
- [1910.10683] Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (arxiv.org):https://arxiv.org/abs/1910.10683。
譯者介紹
朱先忠,51CTO社區(qū)編輯,51CTO專家博客、講師,濰坊一所高校計算機(jī)教師,自由編程界老兵一枚。
原文標(biāo)題:De-coded: Transformers explained in plain English,作者:Chris HughesChris Hughes