













純文本模型訓出「視覺」表征!MIT最新研究:語言模型用代碼就能作畫
只會「看書」的大語言模型,有現實世界的視覺感知力嗎?通過對字符串之間的關系進行建模,關于視覺世界,語言模型到底能學會什么?
最近,麻省理工學院計算機科學與人工智能實驗室(MIT CSAIL)的研究人員對語言模型的視覺能力進行了系統的評估,從簡單形狀、物體到復雜場景,要求模型不斷生成和識別出更復雜的視覺概念,并演示了如何利用純文本模型訓練出一個初步的視覺表征學習系統。

論文鏈接:https://arxiv.org/abs/2401.01862
由于語言模型無法以像素的形式輸入或輸出視覺信息,所以在研究中使用代碼來渲染、表示圖像。
雖然LLM生成的圖像看起來不像自然圖像,但從生成結果,以及模型可以自我糾正來看,對字符串/文本的精確建模可以教會語言模型關于視覺世界中的諸多概念。
此外,研究人員還探索了如何利用文本模型生成的圖像來進行自監督視覺表征學習,結果也展現了其用作視覺模型訓練的潛力,可以僅使用LLM對自然圖像進行語義評估。
語言模型的視覺概念
先問一個問題:對于人來說,理解「青蛙」的視覺概念意味著什么?
知道它皮膚的顏色、有多少只腳、眼睛的位置、跳躍時的樣子等細節就足夠了嗎?
人們普遍認為,要從視覺上理解青蛙的概念,需要看青蛙的圖像,還需要從不同的角度和各種真實世界的場景中對青蛙進行觀察。
如果只觀察文本的話,可以多大程度上理解不同概念的視覺意義?
換到模型訓練角度來看,大型語言模型(LLM)的訓練輸入就只有文本數據,但模型已經被證明可以理解有關形狀、顏色等概念的信息,甚至還能通過線性轉換到視覺模型的表征中。

也就是說,視覺模型和語言模型在世界表征方面是很相似的。
但現有的關于模型表征方法大多基于一組預先選擇的屬性集合來探索模型編碼哪些信息,這種方法無法動態擴展屬性,而且還需要訪問模型的內部參數。
所以研究人員提出了兩個問題:
1、關于視覺世界,語言模型到底了解多少?
2、能否「只用文本模型」訓練出一個可用于自然圖像的視覺系統?
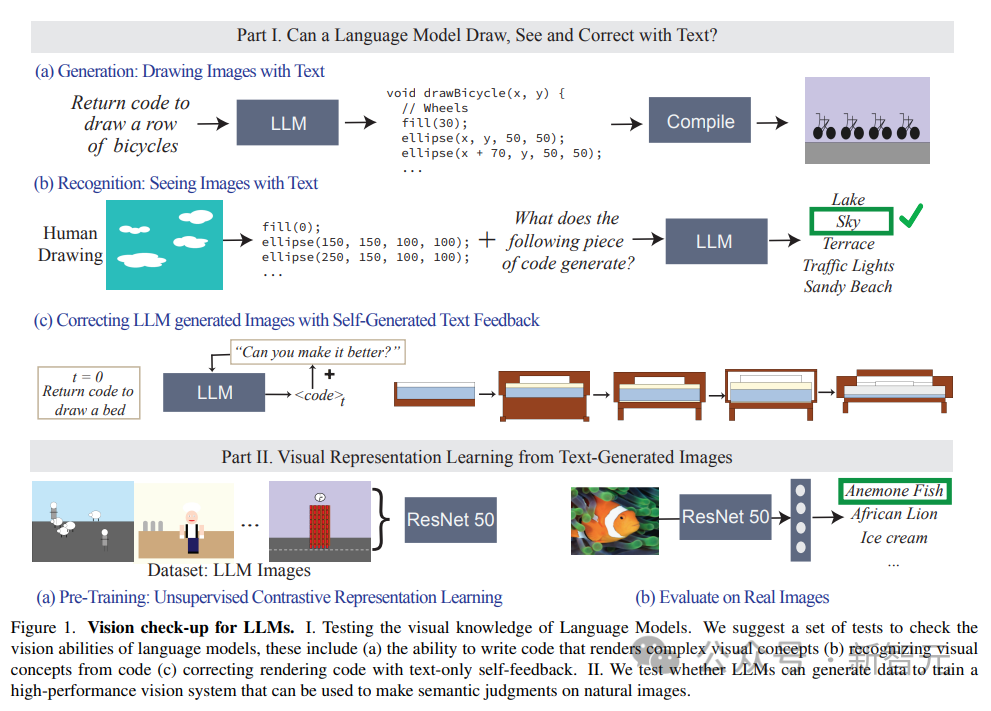
為了找到答案,研究人員通過測試不同語言模型在渲染(render, 即draw)和識別(recognize, 即see)真實世界的視覺概念,來評估哪些信息包含在模型中,從而實現了測量任意屬性的能力,而無需針對每個屬性單獨訓練特征分類器。
雖然語言模型無法生成圖像,但像GPT-4等大模型可以生成出渲染物體的代碼,文中通過textual prompt -> code -> image的過程,逐步增加渲染物體的難度來測量模型的能力。
研究人員發現LLM在生成由多個物體組成的復雜視覺場景方面出奇的好,可以高效地對空間關系進行建模,但無法很好地捕捉視覺世界,包括物體的屬性,如紋理、精確的形狀,以及與圖像中其他物體的表面接觸等。
文中還評估LLM識別感知概念的能力,輸入以代碼表示的繪畫,代碼中包括形狀的序列、位置和顏色,然后要求語言模型回答代碼中描述的視覺內容。

實驗結果發現,LLM與人類正好相反:對于人來說,寫代碼的過程很難,但驗證圖像內容很容易;而模型則是很難解釋/識別出代碼的內容,但卻可以生成復雜場景。
此外,研究結果還證明了語言模型的視覺生成能力可以通過文本糾錯(text-based corrections)來進一步改善。
研究人員首先使用語言模型來生成說明概念的代碼,然后不斷輸入提示「improve its generated code」(改善生成的代碼)作為條件來修改代碼,最終模型可以通過這種迭代的方式來改善視覺效果。

視覺能力數據集:指向場景
研究人員構建了三個文本描述數據集來測量模型在創建、識別和修改圖像渲染代碼的能力,其復雜度從低到高分別為簡單的形狀及組合、物體和復雜的場景。

1. 圖形及其組成(Shapes and their compositions)
包含來自不同類別的形狀組成,如點、線、2D形狀和3D形狀,具有32種不同的屬性,如顏色、紋理、位置和空間排列。
完整的數據集包含超過40萬個示例,使用其中1500個樣本進行實驗測試。
2. 物體(Objects)
包含ADE 20K數據集的1000個最常見的物體,生成和識別的難度更高,因為包含更多形狀的復雜的組合。
3. 場景(Scenes)
由復雜的場景描述組成,包括多個物體以及不同位置,從MS-COCO數據集中隨機均勻抽樣1000個場景描述得到。
數據集中的視覺概念都是用語言進行描述的,例如場景描述為「一個陽光明媚的夏日,在海灘上,有著蔚藍的天空和平靜的海洋」(a sunny summer day on a beach, with a blue sky and calm ocean)。
在測試過程中,要求LLM根據描繪的場景來生成代碼并編譯渲染圖像。
實驗結果
評估模型的任務主要由三個:
1. 生成/繪制文本:評估LLM在生成對應于特定概念的圖像渲染代碼方面的能力。
2. 識別/查看文本:測試LLM在識別以代碼表示的視覺概念和場景方面的性能。我們測試每個模型上的人類繪畫的代碼表示。
3. 使用文本反饋糾正繪圖:評估LLM使用自身生成的自然語言反饋迭代修改其生成代碼的能力。
測試中對模型輸入的提示為:write code in the programming language [programming language name] that draws a [concept]
然后根據模型的輸出代碼進行編譯并渲染,對生成圖像的視覺質量和多樣性進行評估:
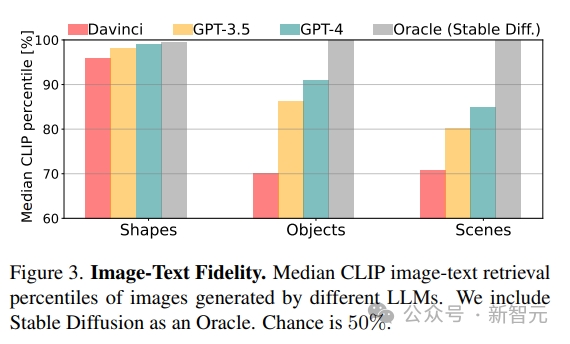
1. 忠實度(Fidelity)
通過檢索圖像的最佳描述來計算生成的圖像與真實描述之間的忠實度。首先使用CLIP得分計算每個圖像與同一類別(形狀/物體/場景)中所有潛在描述之間的一致性,然后以百分比報告真實描述的排序(例如,得分100%意味著真實概念排名第一)。
2. 多樣性(Diversity)
為了評估模型渲染不同內容的能力,在代表相同視覺概念的圖像對上使用LPIPS多樣性得分。
3. 逼真度(realism)
對于從ImageNet的1K圖像的采樣集合,使用Fréchet Inception Distance(FID)來量化自然圖像和LLM生成的圖像的分布差異。
對比實驗中,使用Stable Diffusion獲得的模型作為基線。
LLM能可視化(visualize)什么?
研究結果發現,LLM可以從整個視覺層次可視化現實世界的概念,對兩個不相關的概念進行組合(如汽車形狀的蛋糕),生成視覺現象(如模糊圖像),并設法正確解釋空間關系(如水平排列「一排自行車」)。
意料之中的是,從CLIP分數結果來看,模型的能力會隨著從形狀到場景的概念復雜性的增加而下降。
對于更復雜的視覺概念,例如繪制包含多個對象的場景,GPT-3.5和GPT-4在使用processing和tikz繪制具有復雜描述的場景時比python-matplotlib和python-turtle更準確。
對于物體和場景,CLIP分數表明包含「人」,「車輛」和「戶外場景」的概念最容易繪制,這種渲染復雜場景的能力來自于渲染代碼的表現力,模型在每個場景中的編程能力,以及所涉及的不同概念的內部表征質量。
LLM不能可視化什么?
在某些情況下,即使是相對簡單的概念,模型也很難繪制,研究人員總結了三種常見的故障模式:
1. 語言模型無法處理一組形狀和特定空間組織(space organization)的概念;
2. 繪畫粗糙,缺乏細節,最常出現在Davinci中,尤其是在使用matplotlib和turtle編碼時;
3. 描述是不完整的、損壞的,或只表示某個概念的子集(典型的場景類別)。
4. 所有模型都無法繪制數字。
多樣性和逼真度
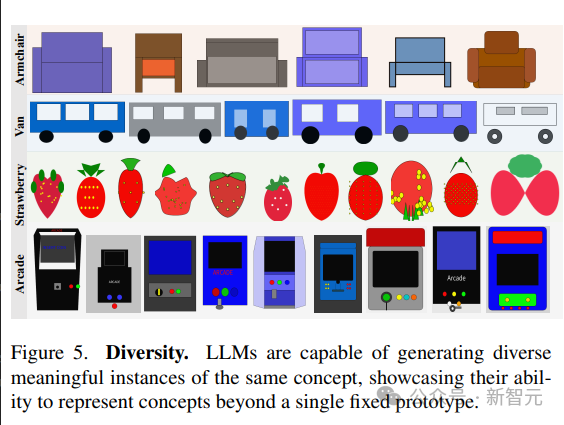
語言模型展示了生成相同概念的不同可視化的能力。
為了生成相同場景的不同樣本,文中對比了兩種策略:
1. 從模型中重復采樣;
2. 對參數化函數進行采樣,該參數化函數允許通過更改參數來創建概念的新繪圖。
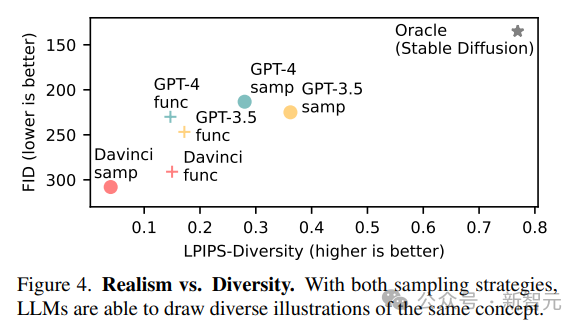
模型呈現視覺概念的多樣化實現的能力反映在高LPIPS多樣性分數中;生成不同圖像的能力表明,LLM能夠以多種方式表示視覺概念,而不局限于一組有限的原型。
LLM生成的圖像遠不如自然圖像真實,與Stable Diffusion相比,模型在FID指標上得分很低,但現代模型的性能要比舊模型更好。
從文本中學習視覺系統
訓練和評估
研究人員使用無監督學習得到的預訓練視覺模型作為網絡骨干,使用MoCo-v2方法在LLM生成的130萬384×384圖像數據集上訓練ResNet-50模型,總共200個epoch;訓練后,使用兩種方法評估在每個數據集上訓練的模型的性能:
1. 在ImageNet-1 k分類的凍結主干上訓練線性層100 epoch,
2. 在ImageNet-100上使用5-最近鄰(kNN)檢索。

從結果中可以看到,僅使用LLM生成的數據訓練得到的模型,就可以為自然圖像提供強大的表征能力,而無需再訓練線性層。
結果分析
研究人員將LLM生成的圖像與現有程序生成的圖像進行對比,包括簡單的生成程序,如dead-levaves,fractals和StyleGAN,以生成高度多樣化的圖像。
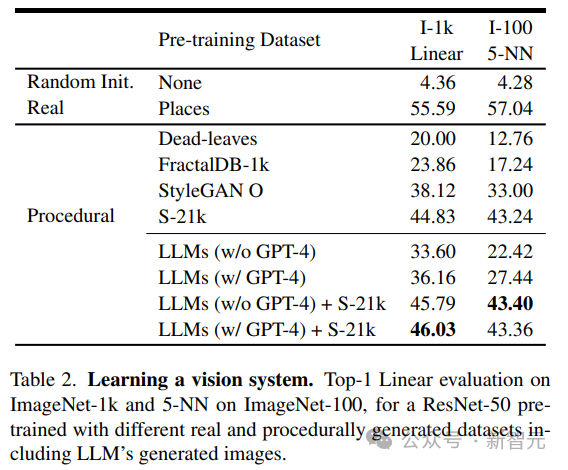
從結果中來看,LLM方法要優于dead-levaves和fractals,但還不是sota;在對數據進行人工檢查后,研究人員將這種劣效性(inferiority)歸因于大多數LLM生成的圖像中缺乏紋理。
為了解決這一問題,研究人員將機Shaders-21k數據集與從LLM獲得的樣本相結合以生成紋理豐富的圖像。
從結果中可以看到,該方案可以大幅提升性能,并優于其他基于程序生成的方案。




























