













小模型卷起來了:Mistral聯合英偉達開源12B小模型,128k上下文
今天凌晨,OpenAI 突然發布了 GPT-4o 的迷你版本 ——GPT-4o mini。這個模型替代了原來的 GPT-3.5,作為免費模型在 ChatGPT 上提供。其 API 價格也非常美麗,每百萬輸入 token 僅為 15 美分,每百萬輸出 token 60 美分, 比之前的 SOTA 模型便宜一個數量級,比 OpenAI 此前最便宜的 GPT-3.5 Turbo 還要便宜 60% 以上。
OpenAI CEO 山姆?奧特曼對此的形容是:通往智能的成本已經「too cheap to meter」。

與動輒上千億參數的大模型相比,小模型的優勢是顯而易見的:它們不僅計算成本更低,訓練和部署也更為便捷,可以滿足計算資源受限、數據安全級別較高的各類場景。因此,在大筆投入大模型訓練之余,像 OpenAI、谷歌等科技巨頭也在積極訓練好用的小模型。
其實,比 OpenAI 官宣 GPT-4o mini 早幾個小時,被譽為「歐洲版 OpenAI」的 Mistral AI 也官宣了一個小模型 ——Mistral NeMo。

這個小模型由 Mistral AI 和英偉達聯合打造,參數量為 120 億(12B),上下文窗口為 128k。
Mistral AI 表示,Mistral NeMo 的推理能力、世界知識和編碼準確性在同類產品中都是 SOTA 級別的。由于 Mistral NeMo 依賴于標準架構,因此易于使用,可在任何使用 Mistral 7B 的系統中成為替代品。
下表比較了 Mistral NeMo 基本模型與兩個最新的開源預訓練模型(Gemma 2 9B 和 Llama 3 8B)的準確性。(嚴格來講,這個對比不太公平,畢竟Mistral NeMo 的參數量比另外兩個都要大不少)

表 1:Mistral NeMo 基本模型與 Gemma 2 9B 和 Llama 3 8B 的性能比較。
他們在 Apache 2.0 許可證下發布了預訓練的基本檢查點和指令微調檢查點,允許商用。Mistral NeMo 經過量化感知訓練,可在不損失任何性能的情況下進行 FP8 推理。
面向大眾的多語言模型
該模型專為全球多語言應用而設計。它受過函數調用訓練,擁有一個大型上下文窗口,在英語、法語、德語、西班牙語、意大利語、葡萄牙語、中文、日語、韓語、阿拉伯語和印地語方面表現尤為突出。
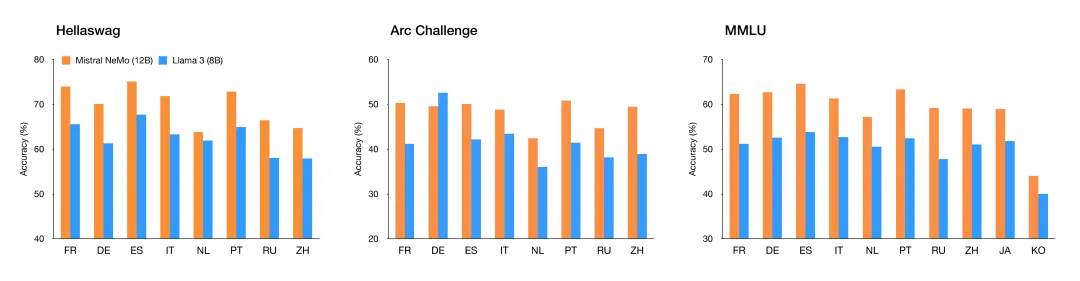
圖 1:Mistral NeMo 在多語言基準測試中的表現。
Tekken:更高效的分詞器
Mistral NeMo 使用基于 Tiktoken 的新分詞器 Tekken,該分詞器經過 100 多種語言的訓練,能比以前 Mistral 模型中使用的 SentencePiece 分詞器更有效地壓縮自然語言文本和源代碼。在壓縮源代碼、中文、意大利文、法文、德文、西班牙文和俄文時,它的效率要高出約 30%。在壓縮韓文和阿拉伯文時,它的效率是原來的 2 倍和 3 倍。事實證明,與 Llama 3 分詞器相比,Tekken 在壓縮所有語言中約 85% 的文本方面更勝一籌。

圖 2:Tekken 的壓縮率。
指令微調
Mistral NeMO 經歷了高級微調和對齊階段。與 Mistral 7B 相比,它在遵循精確指令、推理、處理多輪對話和生成代碼方面的能力大大提升。

表 2:Mistral NeMo 指令微調模型的準確率。使用 GPT4o 作為裁判進行的評估。
Mistral NeMo 基礎模型和指令微調模型的權重都托管在 HuggingFace 上。
- 基礎模型:https://huggingface.co/mistralai/Mistral-Nemo-Base-2407
- 指令微調模型:https://huggingface.co/mistralai/Mistral-Nemo-Instruct-2407
你現在就可以使用 mistral-inference 試用 Mistral NeMo,并使用 mistral-finetune 對其進行調整。
該模型被還打包在一個容器中,作為 NVIDIA NIM inference 微服務,可從 ai.nvidia.com 獲取。
模型變小之后,小公司也能用 AI 賺錢了
在接受 Venturebeat 采訪時,英偉達應用深度學習研究副總裁 Bryan Catanzaro 詳細闡述了小型模型的優勢。他說:「小型模型更容易獲取和運行,可以有不同的商業模式,因為人們可以在家中自己的系統上運行它們。事實上,Mistral NeMo 可以在許多人已經擁有的 RTX GPU 上運行。」

這一進展發生在 AI 行業的關鍵時刻。雖然很多注意力都集中在擁有數千億參數的龐大模型上,但人們對能夠在本地商業硬件上運行的更高效模型越來越感興趣。這種轉變是由對數據隱私的擔憂、對更低延遲的需求以及對更具成本效益的 AI 解決方案的渴望所驅動的。
Mistral-NeMo 128k 的上下文窗口是一個突出的功能,允許模型處理和理解比許多競爭對手更多的文本塊。Catanzaro 說:「我們認為長上下文能力對許多應用來說可能很重要。如果無需進行微調,那模型會更容易部署。」
這種擴展的上下文窗口對于處理冗長文檔、復雜分析或復雜編碼任務的企業來說尤其有價值。它有可能消除頻繁上下文刷新的需要,從而產生更加連貫一致的輸出。
該模型的效率和本地部署能力可能會吸引在聯網受限或有嚴格數據隱私要求的環境中運營的企業。然而,Catanzaro 澄清了該模型的預期使用場景。他說:「我會更多地考慮筆記本電腦和臺式電腦,而不是智能手機。」
這一定位表明,雖然 Mistral-NeMo 使 AI 更接近個人業務用戶,但它還沒有達到移動部署的水平。
行業分析師認為,這次發布可能會顯著擾亂 AI 軟件市場。Mistral-NeMo 的推出代表了企業 AI 部署的潛在轉變。通過提供一種可以在本地硬件上高效運行的模型,英偉達和 Mistral AI 正在解決阻礙許多企業廣泛采用 AI 的擔憂,如數據隱私、延遲以及與基于云的解決方案相關的高成本。
這一舉措可能會使競爭環境更加公平,允許資源有限的小型企業利用以前只有擁有大量 IT 預算的大型公司才能獲得的 AI 能力。然而,這一發展的真實影響將取決于模型在實際應用中的表現以及圍繞它構建的工具和支持生態系統。
隨著各行業的企業繼續努力將 AI 整合到他們的運營中,像 Mistral-NeMo 這樣的模型代表了向更高效、可部署的 AI 解決方案的轉變。這是否會挑戰更大、基于云的模型的主導地位還有待觀察,但它無疑為 AI 在企業環境中的整合開辟了新的可能性。




























