譯者 | 李睿
審校 | 重樓
專業(yè)化的必要性
醫(yī)院有很多具有不同專長的專家和醫(yī)生,他們擅長解決各自領域內的醫(yī)療難題。外科醫(yī)生、心臟病專家、兒科醫(yī)生等各類專家緊密合作,為患者提供了全面而個性化的醫(yī)療護理服務。同樣,人們也可以將這一合作模式應用于人工智能領域。
人工智能中的混合專家(MoE)架構被定義為不同“專家”模型的混合或融合,能夠共同處理或響應復雜的數(shù)據(jù)輸入。當涉及到人工智能時,MoE模型中的每個專家都專門研究一個更宏大的問題——就像每位醫(yī)生都專門在其醫(yī)學領域內深耕一樣。這樣的設計提高了效率,并增強了系統(tǒng)的有效性和準確性。
Mistral AI提供的開源基礎大型語言模型(LLM)可以與OpenAI相媲美。并且已經(jīng)在Mixtral 8x7B模型中使用MoE架構,是一種尖端的大型語言模型(LLM)形式的革命性突破。以下將深入探討Mistral AI的Mixtral為什么在其他基礎LLM中脫穎而出,以及當前的LLM現(xiàn)在采用MoE架構的原因,并突出其速度、大小和準確性。
升級LLM的常用方法
為了更好地理解MoE架構如何增強LLM,本文將討論提高LLM效率的常用方法。人工智能從業(yè)者和開發(fā)人員通過增加參數(shù)、調整架構或微調來增強模型。
·增加參數(shù):通過提供更多信息并對其進行解釋,模型學習和表示復雜模式的能力得到了提高。這可能會導致過擬合和幻覺,需要從人類反饋中進行廣泛的強化學習(RLHF)。
- 調整架構:引入新的層或模塊可以適應不斷增加的參數(shù)數(shù)量,并提高特定任務的性能。然而,對底層架構的更改很難實現(xiàn)。
- 微調:預先訓練的模型可以根據(jù)特定數(shù)據(jù)或通過遷移學習進行微調,允許現(xiàn)有的LLM處理新的任務或領域,而無需從頭開始。這是最簡單的方法,并且不需要對模型進行重大更改。
什么是MoE架構?
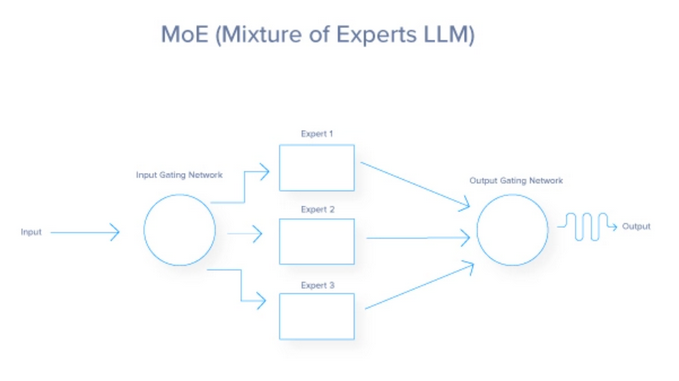
混合專家(MoE)架構是一種神經(jīng)網(wǎng)絡設計,通過為每個輸入動態(tài)激活稱為“專家”的專用網(wǎng)絡子集來提高效率和性能。門控網(wǎng)絡決定激活哪些專家導致稀疏激活和減少計算成本。MoE架構由兩個關鍵組件組成:門控網(wǎng)絡和專家網(wǎng)絡。以下進行分析:
從本質上來說,MoE架構的功能就像一個高效的交通系統(tǒng),根據(jù)實時情況和期望的目的地,將每輛車(或在這種情況下是數(shù)據(jù))導向最佳路線。每個任務都被路由到最合適的專門處理該特定任務的專家或子模型。這種動態(tài)路由確保為每個任務使用最有能力的資源,從而提高模型的整體效率和有效性。MoE架構利用了三種方法來提高模型的保真度。
(1)通過多個專家完成任務,MoE通過為每個專家添加更多參數(shù)來增加模型的參數(shù)大小。
(2)MoE改變了經(jīng)典的神經(jīng)網(wǎng)絡架構,它包含了一個門控網(wǎng)絡,以確定哪些專家被用于指定的任務。
(3)每個人工智能模型都有一定程度的微調,因此MoE中的每個專家都經(jīng)過微調,以達到傳統(tǒng)模型無法利用的額外調整層的預期效果。
MoE門控網(wǎng)絡
門控網(wǎng)絡在MoE模型中充當決策者或控制器。它評估傳入的任務,并確定哪個專家適合處理這些任務。這一決策通常基于學習權值,隨著時間的推移,通過訓練進行調整,進一步提高其與專家匹配任務的能力。門控網(wǎng)絡可以采用各種策略,從概率方法(將軟任務分配給多個專家)到確定性方法(將每個任務路由到單個專家)。
MoE專家
MoE模型中的每個專家代表一個較小的神經(jīng)網(wǎng)絡、機器學習模型或針對問題域的特定子集優(yōu)化的LLM。例如,在Mistral中,不同的專家可能專注于理解某些語言、方言,甚至是查詢類型。專業(yè)化確保每個專家都精通自己的領域,當結合其他專家的貢獻時,將在廣泛的任務上實現(xiàn)卓越的性能。
MoE損失函數(shù)
雖然損失函數(shù)不被視為是MoE架構的主要組成部分,但它在模型的未來性能中起著關鍵作用,因為它被設計用于優(yōu)化單個專家和門控網(wǎng)絡。
它通常結合每個專家計算的損失,這些損失由門控網(wǎng)絡分配給他們的概率或重要性進行加權。這有助于在調整門控網(wǎng)絡以提高路由準確性的同時,對專家的特定任務進行微調。
從始至終的MoE流程
現(xiàn)在總結MoE整個流程,并添加更多細節(jié)。
以下是對路由過程從始至終如何工作的總結解釋:
- 輸入處理:輸入數(shù)據(jù)的初始處理;主要是在LLM案例中的提示。
- 特征提取:轉換原始輸入進行分析。
- 門控網(wǎng)絡評估:通過概率或權重評估專家的適用性。
- 加權路由:根據(jù)計算的權重分配輸入;在這里,已經(jīng)完成最合適的LLM流程的選擇。在某些情況下,選擇多個LLM來回答單個輸入。
- 任務執(zhí)行:處理每個專家分配的輸入。
- 整合專家輸出:將各個專家的結果結合起來,形成最終輸出。
- 反饋和適應:使用性能反饋來改進模型。
- 迭代優(yōu)化:不斷優(yōu)化路線和模型參數(shù)。
使用MoE架構的流行模型
OpenAI的GPT-4和GPT-40
GPT-4和GPT-40支持ChatGPT的高級版本。這些多模態(tài)模型利用MoE來攝取不同的源媒體,例如圖像、文本和語音。有傳言稱,GPT-4有8個專家,每個專家擁有2200億個參數(shù),整個模型的參數(shù)總數(shù)超過1.7萬億個。
Mistral AI的Mixtral 8x7b
Mistral AI 提供了非常強大的開源 AI 模型,并表示他們的 Mixtral 模型是一個 sMoE 模型或稀疏多專家混合模型,以較小的封裝形式提供。Mixtral 8x7b總共有467億個參數(shù),但每個令牌只使用129億個參數(shù),因此以這個成本處理輸入和輸出。他們的MoE模型一直優(yōu)于Llama2 (70B)和GPT-3.5 (175B),同時運行成本更低。
MoE的好處以及是首選架構的原因
最終,MoE架構的主要目標是呈現(xiàn)復雜機器學習任務處理方式的范式轉變。它提供了獨特的優(yōu)勢,并在幾個方面展示了其優(yōu)于傳統(tǒng)模式的優(yōu)勢。
增強的模型可擴展性
- 每個專家負責任務的一部分,因此通過增加專家來擴展不會導致計算需求的成比例增加。
- 這種模塊化方法可以處理更大、更多樣化的數(shù)據(jù)集,并促進并行處理,加快操作速度。例如,將圖像識別模型添加到基于文本的模型中可以集成額外的LLM專家來解釋圖像,同時仍然能夠輸出文本。
- 多功能性允許模型在不同類型的數(shù)據(jù)輸入中擴展其功能。
提高效率和靈活性
- MoE模型非常高效,與傳統(tǒng)架構使用所有參數(shù)不同,MoE模型只有選擇地只讓必要的專家參與特定的輸入。
- 該架構減少了每次推理的計算負荷,允許模型適應不同的數(shù)據(jù)類型和專門的任務。
專業(yè)化和準確性
- MoE系統(tǒng)中的每個專家都可以針對整體問題的特定方面進行微調,從而在這些領域獲得更高的專業(yè)知識和準確性。
- 像這樣的專業(yè)化在醫(yī)學成像或財務預測等領域很有幫助,在這些領域,精確度是關鍵。
- MoE可以在范圍狹窄的領域產(chǎn)生更好的結果,因為它有細致入微的理解,詳細的知識,以及在專門任務上優(yōu)于通才模型的能力。
MoE架構的缺點
雖然MoE架構提供了顯著的優(yōu)勢,但它也帶來了可能影響其采用和有效性的挑戰(zhàn)。
- 模型復雜性:管理多個神經(jīng)網(wǎng)絡專家和用于引導流量的門控網(wǎng)絡使MoE的開發(fā)和運營成本具有挑戰(zhàn)性。
- 訓練穩(wěn)定性:門控網(wǎng)絡和專家之間的相互作用引入了不可預測的動態(tài),阻礙了實現(xiàn)統(tǒng)一的學習率,需要廣泛的超參數(shù)調整。
- 不平衡:讓專家閑置是對MoE模型的糟糕優(yōu)化,將資源花費在不使用的專家身上或過于依賴某些專家。平衡工作負載分布和調優(yōu)有效門對于高性能MoE AI至關重要。
應該注意的是,隨著MoE架構的改進,上述缺點通常會隨著時間的推移而減少。
專業(yè)化塑造的未來
反思MoE方法及其與人類的相似之處,可以看到,正如專業(yè)團隊比一般勞動力取得更多成就一樣,專業(yè)模型在人工智能模型中的表現(xiàn)也優(yōu)于單一模型。優(yōu)先考慮多樣性和專業(yè)知識可以將大規(guī)模問題的復雜性轉化為專家可以有效解決的可管理部分。
當展望未來時,需要考慮專業(yè)系統(tǒng)在推進其他技術方面的更廣泛影響。MoE的原則可以影響醫(yī)療保健、金融和自治系統(tǒng)等行業(yè)的發(fā)展,促進更高效、更準確的解決方案。
MoE的旅程才剛剛開始,其持續(xù)發(fā)展有望推動人工智能及其他領域的進一步創(chuàng)新。隨著高性能硬件的不斷發(fā)展,這種專家AI的混合體可以在人們的智能手機中運行,將提供更智能的體驗,但首先需要有人去訓練它們。
原文標題:Why the Newest LLMs Use a MoE (Mixture of Experts) Architecture,作者:Kevin Vu