













智源千萬級指令微調數據集Infinity-Instruct持續迭代,Llama3.1僅微調即可接近GPT-4
指令微調是引導語言模型落地、構建高性能對話模型的關鍵一步。針對目前開源的指令數據集質量低、覆蓋領域少、數據信息不透明等問題,智源研究院推出了千萬級指令微調數據集Infinity Instruct。該數據集今年6月發布,近日完成了新一輪迭代,包括Infinity-Instruct-7M基礎指令數據集和Infinity-Instruct-Gen對話指令數據集。
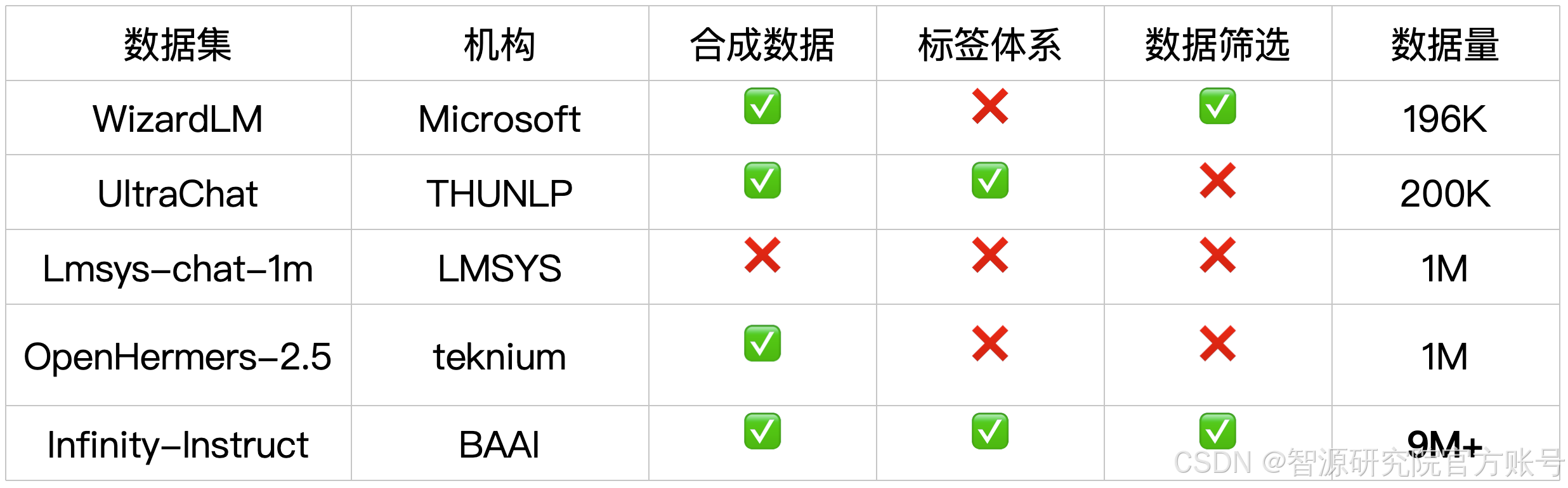
Infinity-Instruct-7M包含744萬條數學、代碼、常識問答等領域的基礎指令數據,用于進一步全面提升預訓練模型的基礎能力。Opencompass測試結果顯示,經過在Infinity-Instruct-7M數據集上的微調,Llama3.1-70B、Mistral-7B-v0.1綜合能力評價可基本對齊官方自己發布的對話模型,且InfInstruct-7M-Mistral-7B的綜合評分超過了GPT-3.5,InfInstruct-7M-Llama3.1-70B已十分接近GPT-4。
*官方匯報結果
Infinity-Instruct-Gen包含149萬條合成的復雜指令,用于提升模型在各種真實對話場景中回復的魯棒性。基于該數據,對經過Infinity-Instruct-7M增強的模型做進一步SFT,即可取得超過官方對話模型的效果。而大多數的官方對話模型除了做基本的SFT外,還會做DPO/RLHF等對齊訓練以提升模型的對話能力,產生額外的訓練成本。
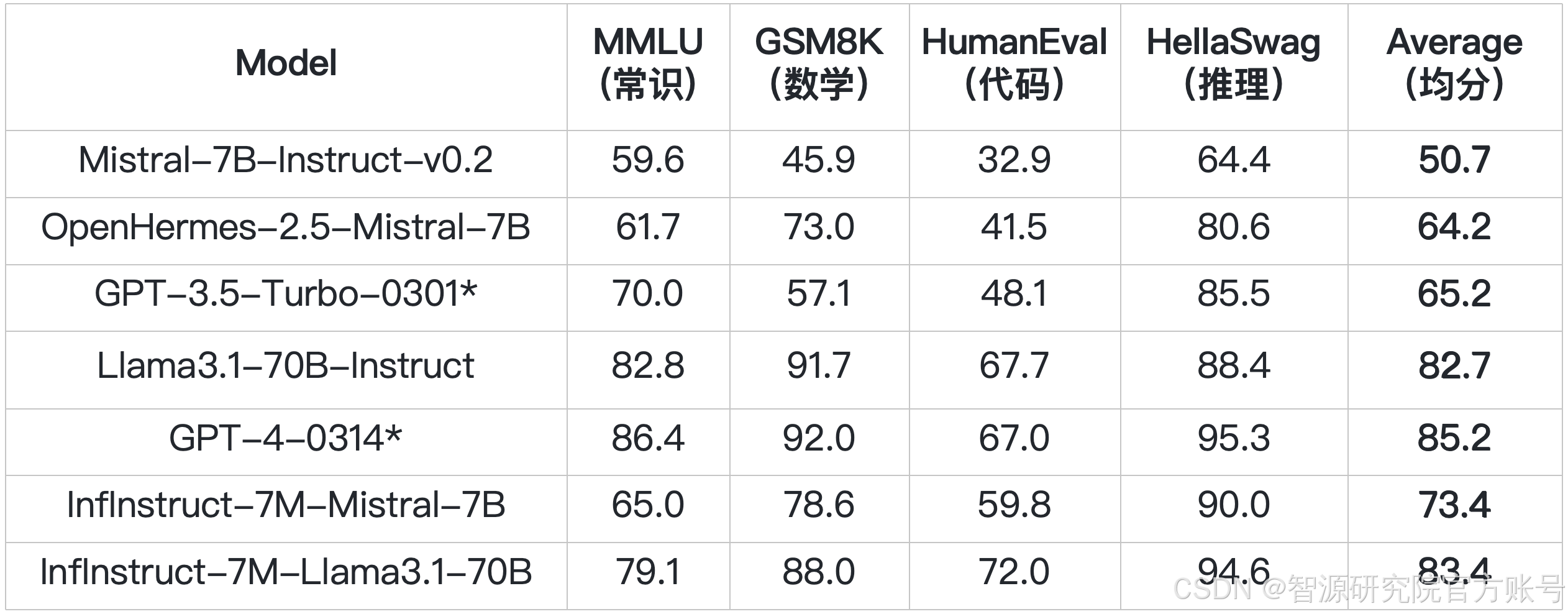
智源在MTBench、AlpacaEval2、Arena-Hard三個主流榜單上評測了Infinity-Instruct 7M+Gen對模型對話能力的增益,其中,AlpacaEval2和Arena-Hard與真實人類評價榜單Chatbot Arena有很高的一致率,MTBench則評測模型的多輪對話能力。
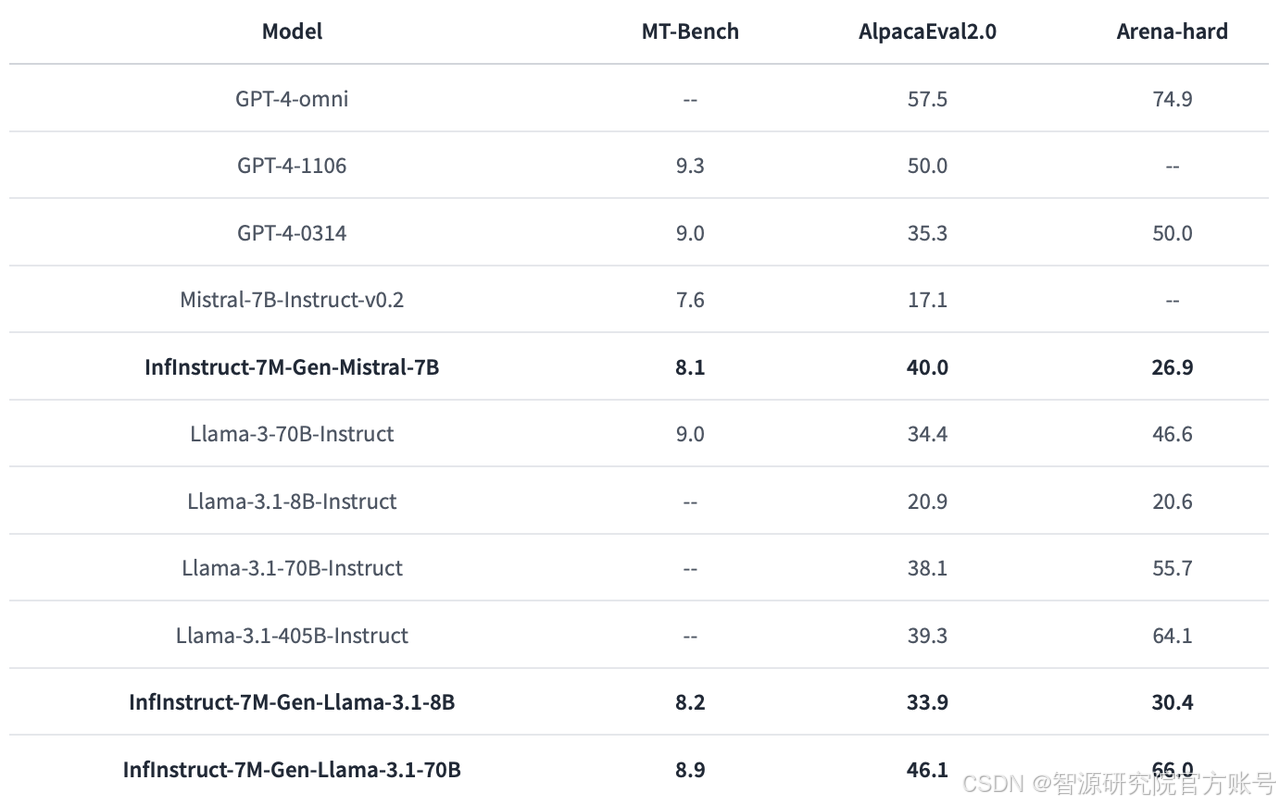
如下左圖所示,InfInstruct-7M-Gen-Mistral-7B,InfInstruct-7M-Gen-Llama3.1-8B,InfInstruct-7M-Gen-Llama3.1-70B等經過Infinity Instruct微調的模型已經超越了官方對話模型的性能。Arena-Hard上InfInstruct-7M-Gen-Llama3.1-70B(66)超過了Llama3.1-70B-Instruct(55.7)和Llama3.1-405B-Instruct(64.1)。此外,如右下圖所示,AlpacaEval2.0榜單上,InfInstruct-7M-Gen-Llama3.1-70B(46.1)更是超過了GPT4-0314(35.3),非常接近GPT4-1106(50)的水準,真正實現了GPT-4級別的對話能力。

Infinity Instruct數據集今年6月在Flopsera,Huggingface等平臺發布后,快速到達了Huggingface Dataset的Trending第一,且吸引大量基于Infinity Instruct的開源微調工作。
下載使用 Infinity-Instruct可在Huggingface、DataHub、Flopsera等平臺下載。
Huggingface: https://huggingface.co/datasets/BAAI/Infinity-Instruct
DataHub: https://data.baai.ac.cn/details/InfinityInstruct
Flopsera: http://open.flopsera.com/flopsera-open/details/InfinityInstruct
Huggingface提供了快速下載Infinity-Instruct系列數據集及模型的代碼。
##數據集下載
from datasets import load_dataset
dataset_7M = load_dataset('BAAI/Infinity-Instruct','7M',split='train')
dataset_Gen = load_dataset('BAAI/Infinity-Instruct','Gen',split='train')
##模型下載
from transformers import AutoModelForCausalLM, AutoTokenizer
model_llama3_1_70B = AutoModelForCausalLM.from_pretrained("BAAI/Infinity-Instruct-7M-Gen-Llama3_1-70B",
torch_dtype=torch.bfloat16,
device_map="auto"
)
tokenizer_llama3_1_70B = AutoTokenizer.from_pretrained("BAAI/Infinity-Instruct-7M-Gen-Llama3_1-70B")
model_mistral_7B = AutoModelForCausalLM.from_pretrained("BAAI/Infinity-Instruct-7M-Gen-Mistral-7B",
torch_dtype=torch.bfloat16,
device_map="auto"
)
tokenizer_mistral_7B = AutoTokenizer.from_pretrained("BAAI/Infinity-Instruct-7M-Gen-Mistral-7B")Infinity-Instruct給每一條指令數據標注了語種、能力類型、任務類型、數據來源等信息,便于使用者根據自身需要篩選數據子集。

技術路線
智源研究院搜集了7500萬余條開源指令作為待選指令池,采用數據選擇與指令合成兩條途徑快速迭代,構建高質量的基礎、對話指令數據集,以填補開源對話模型與GPT-4之間的基礎能力、對話能力差距。
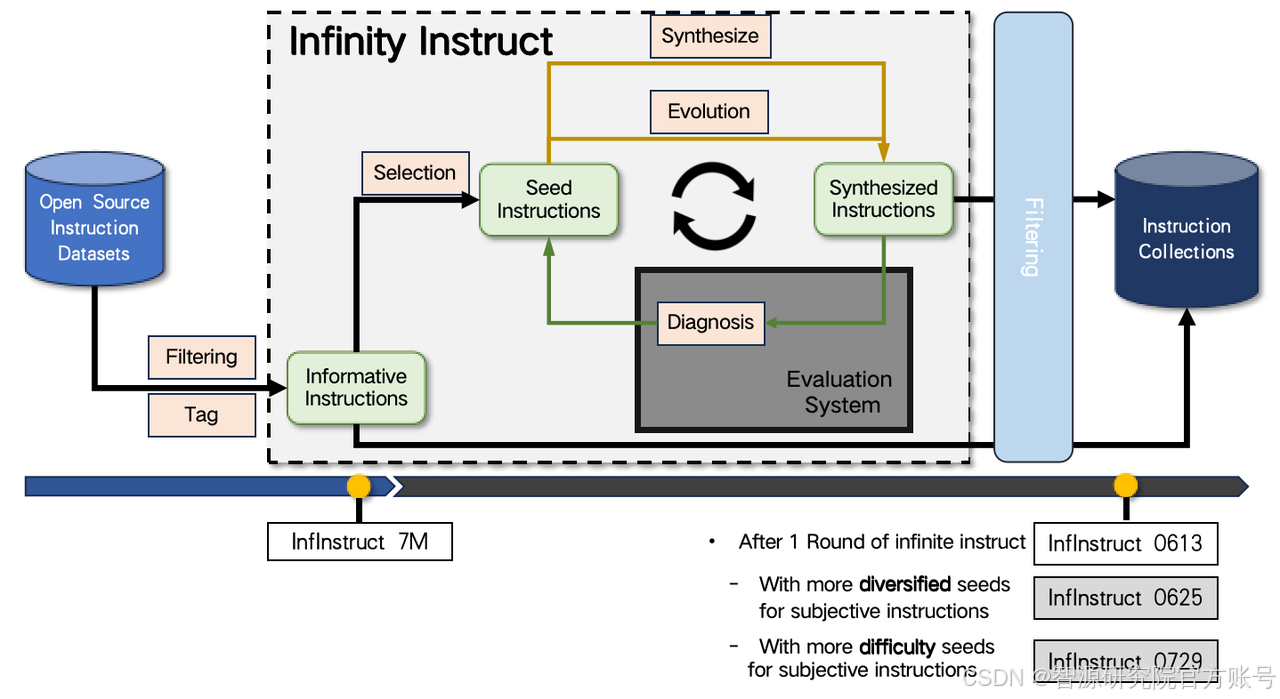
基礎指令數據篩選
對于基礎指令數據集,篩選流程主要考慮訓練數據集和目標數據集數據分布的對齊,基于DSIR的思路,在訓練數據集上進行排序,選取訓練集的子集,擬合目標數據集的分布。

對話數據集生成、進化、評價
對于對話指令數據集,Infinity-Instruct首先采樣了部分高質量的開源指令集,并為每條指令分配一組標簽,描述完成指令所需的能力和知識。標簽系統共有兩個級別:
第一級標簽: 宏觀類別,如 "自然語言處理 "和 "數學推理"。共包括 26 個類別。
第二集標簽:刻畫具體任務,包含超過1.5w個類別。

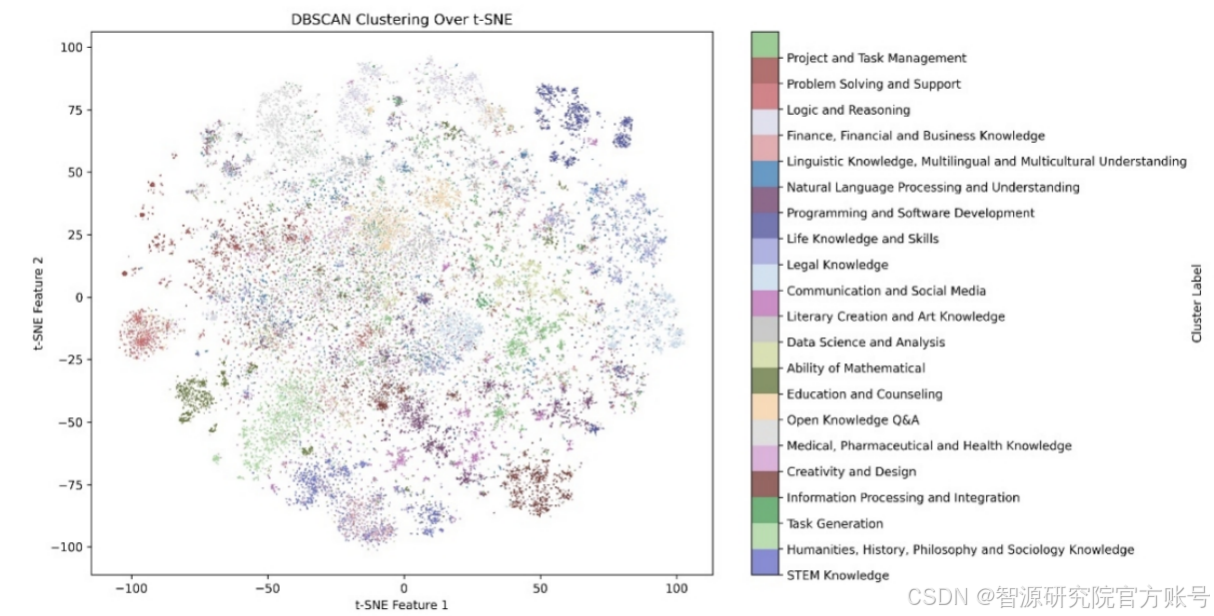
基于此系統,就能識別指令集的內容分布以及完成不同任務所需的能力,構建一個高質量的種子數據集。隨后,Infinity-Instruct參考WizardLM的方法對種子指令在廣度、深度方向上進行擴展,并用AI Agent從指令合規性的角度剔除未能進化的數據。最后,進化后的指令作為初始輸入,使用AI Agent扮演不同角色,為每條指令生成 2 至 4 輪對話。
數據去污、去重
為避免構造的數據存在自身重復、或與評測榜單重復的樣本,Infinity-Instruct對所有數據應用了MinHash進行去重。并基于BGE檢索剔除了和AlpacaEval、MT-Bench等評測榜單重復的樣本。
訓練框架
考慮到微調成本,項目使用FlagScale去掉訓練樣本中不必要的pad,壓縮樣本量,同時應用模型切分、切分支持大模型在數百萬量級指令數據集上的訓練。初步測試可比傳統微調框架,如FastChat+Accelerate快三倍以上。


未來規劃 Infinity Instruct未來將開源基礎、對話指令數據處理的全流程代碼,以及模型訓練代碼。同時,智源將探索擴展Infinity Instruct數據策略到對齊、預訓練階段,支持語言模型構建全生命周期的高質量數據需求。
Infinity RLAIF:基于Infinity Instruct標簽體系以及生成指令構建了50K 對齊數據的第一個版本,實驗結果顯示,Infinity-Gemma-2-9B-SimPO 在AlpacaEval上達到 73.4,在Arena Hard上達到 59.1。未來會進行更多對齊數據、算法的探索。
Infinity Math:基于多個開源數學數據集構建了可無限擴增的數學領域指令數據集,其中POT指令數據可提升在多個7B的基礎語言模型和基礎代碼模型的zero-shot數學能力180%-510%,相關論文被CIKM 2024接收,歡迎引用。
@misc{zhang2024inifinitymath,
title={InfinityMATH: A Scalable Instruction Tuning Dataset in Programmatic Mathematical Reasoning},
author={Bo-Wen Zhang and Yan Yan and Lin Li and Guang Liu},
year={2024},
eprint={2408.07089},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2408.07089},
}





























